论文地址:https://arxiv.org/abs/1902.01541
已有的研究工作:
本文关注的是文献的实体解析问题,当前的state-of-art是mention-pair模型,但是该方法在计算和标记数据方面的成本都比较高。
本文的工作和创新点:
本文提出了一种以增量方式处理文本、动态解析引用的模型,是一种在线学习方法。
研究方法:
工作原理:
自左向右地读取文本,在一个固定大小的工作内存中存储实体,当遇到每个token时,有三种选择:将该token链接到现有的内存中,从而创建一个共同的指代链接;存储一个新的实体,覆盖到现有的内存中;忽视这个token并且继续向前阅读。下图显示的是具有两个内存单元的模型的工作示意。
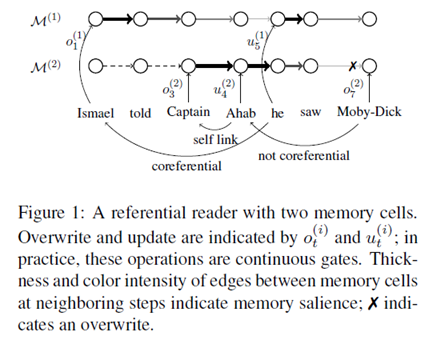
模型简介:
对于一个给定的文档,在两个层级上表示文本,分别是token级别和entity级别。模型包括两个组件,分别是存储单元,用于存储和跟踪文本中实体的状态;循环单元,通过一组门来控制记忆。下图是模型的概述。
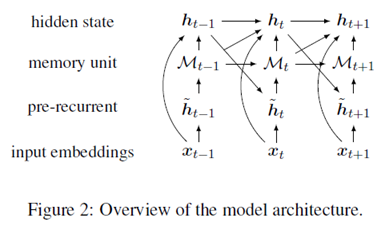
对于循环单元,它的灵感来源于Coreferential-GRU。使用外部存储单元来跟踪实体,让模型学习在每个单元中存储什么,而不是依赖于参照结构来构建动态计算图。其更新方式如下:
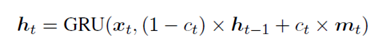
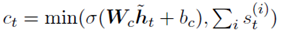
Ct也就是衡量当前token在记忆网络中重要性的一个门。
对于内存单元,它是一个标量的集合,表示的是在某个token处更新或重新某个实体。
实验部分:
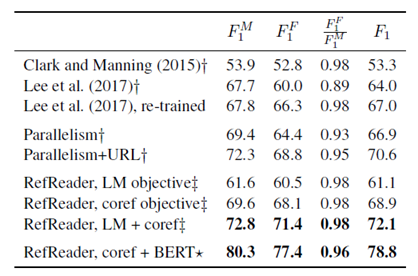
实验在GAP数据集上进行,任务是在文本中正确跟踪实体引用的能力。从结果来看,实验所取得的效果相当好。
评价:
本文做的是文档中实体解析的问题,也就是在本文中正确地跟踪引用的实体。从实验结果来看,提升还是比较明显的。尤其在使用BERT建模的方法取得的提升相当明显,然而BERT的建模是双向的,利用了未来的信息,因此并不能说是纯粹的以增量的方式来更新。但也提醒,未来的工作可以与大规模预训练的一些模型和方法相结合。