以前对机器学习只有很基本粗糙的了解,因为最近有用到xgboost,所以在实践的过程中顺便加深了对机器学习的一些基本概念以及集成学习的理解,本文并没有很深入,因为很多其他博文写的比我要好,所以本文相当于一个综述,一些链接和补充的机器学习基本概念在附录。
集成学习是把个体学习器(分类器)组合成一个强学习器,组合的方式有两类,一类是个体学习器之间不存在强依赖关系,比如bagging和随机森林(Random Forest)算法(随机选择样本和特征,通过投票获取最好的结果)。另一类是将多个弱学习器组合成一个强学习器,比如boosting系列算法,本文介绍的XGBoost(eXtreme Gradient Boosting)极端梯度提升,就是用加法模型将CART(回归分类)树组合起来,联合决策,下一棵树的输入样本与之前决策树的训练和预测相关。
以下确定频率派统计机器学习的三个要素:模型+策略+方法
模型:
对于xgboost,预测结果为每棵树对于输入的输出得分(即叶子节点得分值
,这个值是在下面目标函数求解中优化得到的,而不是简单的取节点内样本均值
)相加之和,k表示第k棵树。每次加入一棵树都期望可以降低损失函数的值(但是循环迭代停止的条件除了损失函数不再下降还有树的深度max_depth达到最大,样本权重和min_child_weight,树的个数n_estimators等)。

策略(选择目标函数:代价函数(损失函数)+正则项):
目标函数是样本预测误差的和+树的复杂度函数(正则项)。默认目标函数objective='reg:squarederror' 即线性回归,还可选择reg:gamma等处理不同类型问题,也支持自定义loss,只要能泰勒展开求一阶、二阶导就可以。
复杂度函数中γ是叶子节点个数的系数,也是引入分裂带来的增益的阈值(小于这个值不分裂),防止叶子节点数目过多。λ是L2正则项(叶子节点得分值),这样更倾向于得到平滑解。两个都是起到防止过拟合的作用。
节点的分裂依据是依据某个特征值分裂后目标函数(损失函数)的减小值。通过穷举或者加权分位数法找到使当前损失函数减少量最大的特征,划分原样本群: I -> L,R。其中是对应样本一阶导,
是对应样本二阶导。(在随机森林分类中,树的节点分裂用信息增益、基尼系数来判定)
分裂点的选择:https://blog.csdn.net/dpengwang/article/details/87910480
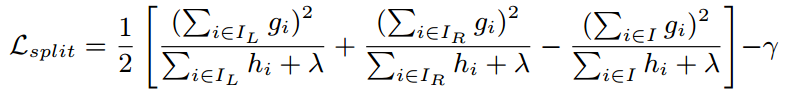
方法:梯度下降法求解
附录:
xgboost官方 API:https://xgboost.readthedocs.io/en/latest/python/python_api.html
调参指南:https://blog.csdn.net/fuqiuai/article/details/79495910
代码:https://www.cnblogs.com/LHWorldBlog/p/9195623.html
树与树之间串行,并行选择最佳分裂点
决策树、CART分类树在损失函数上使用基尼系数(交叉熵泰勒一阶展开求均值)回归树在损失函数上使用均方误差
损失函数(回归:均方误差MSE,分类:交叉熵误差CCE)
L2正则项得到平滑解防止过拟合(还采用每棵树按比例随机选择特征防止过拟合)
梯度下降
boosting
