对比学习
Contrastive Learning
1. 概述
自监督学习,通过创建正负样本对,来学习样本之间的相同与差异,获得对比条件下的特征,可以用在预训练阶段
2. SimCLRv2
2.1 Data Augmentation
对于数据集中的每一张图像,进行数据增强,增强方法有
- 裁剪
- 调整大小
- 重新着色

从中任意选取方法(1-2种)对数据进行增强得到增强样本A ,进行另外一种增强得到增强样本a,可以配成一对,形成正样本对,A和a之间的特征应当是相似的
对于不同图片之间,形成负样本对,他们之间的特征应当是差别较大的

2.2 训练过程
我们将正样本对(或负样本对)输入到深度学习模型中,为每一个图像创建一个向量表示(特征),目标是正样本对的向量特征相似,而负样本对的向量特征不相似
下面以正样本对为例,阐述其训练过程,如果是负样本,损失函数前加一个负号即可
通过最大化正样本对两个向量表示的相似性,最小化负样本对两个向量表示的相似性,深度学习模型会逐渐学习到猫与猫是相似的,猫与狗是不同的,于是便可以再见到猫和狗的时候,区分出来。

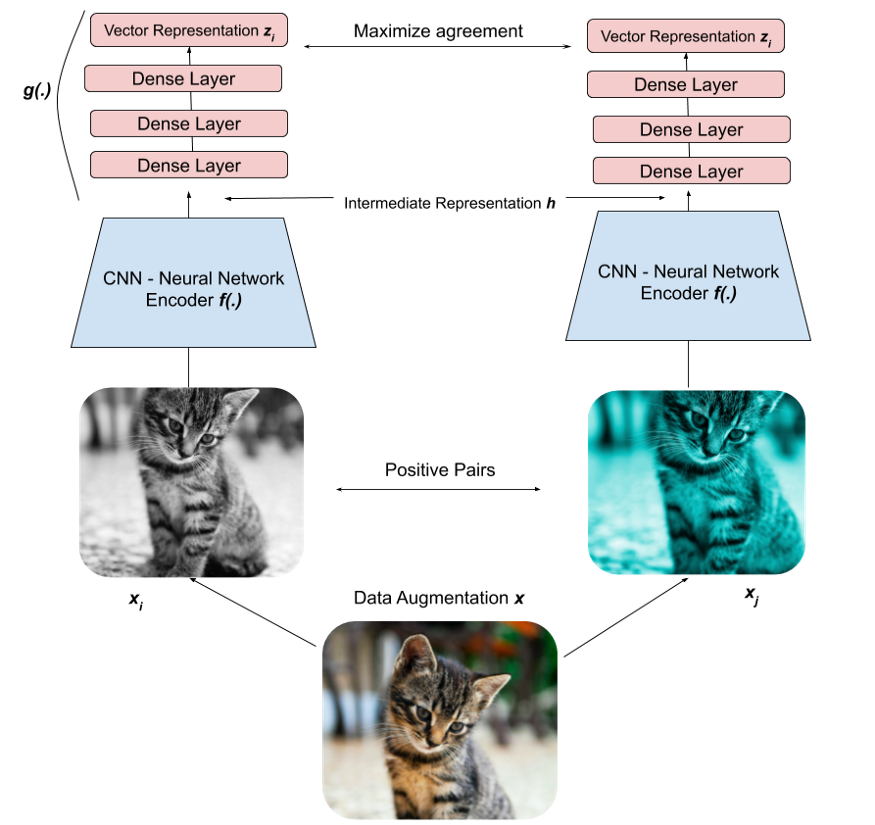
关于这个深度学习模型,还有一些注意的点
1. Projection Head
图像经过CNN网络提取特征后,还需要经过几个Dense Layers,这几层网络称之为Projection head(起到映射特征的功能),根据经验,经过这个步骤,可以提高模型性能
2.最大化相似度(损失函数)
我们要做的是衡量两个表示向量之间的距离,来计算他们之间的相似度

可以选择使用余弦相似度来衡量距离(其它的也可以)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s1oj4iPi-1682751481997)(null)]
两个向量间的距离就是两个向量之间的夹角
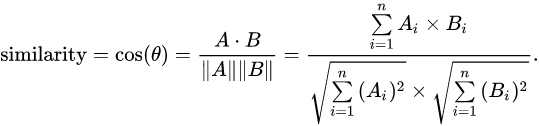
我们以这个夹角作为两个向量之间的相似度度量,我们在一个批次中,会有多种图片的读入,我们需要设置一个损失函数来综合所有图片的距离,对于正样本对,距离要小,损失要小,对于负样本对,距离要大,损失要大
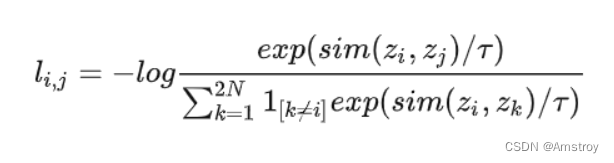
正样本对就是上面说的A和a样本,(B,b),(C,c)等,而负样本对,则是一个批次(N个图像)中,这个正样本与其它样本(非正样本对中的其它样本)的组合(共有(N-1 + N-1个)例如(A,B),(A,C),(A,b),(A,c),
τ为温度系数
关于infoNCE loss的来源与温度系数的作用,可以看这篇文章
https://mp.weixin.qq.com/s/Q6Y3FgQWojm5rnhVyVSvsQ
那么有一个问题是,一个批次N个图像中,如果有两张猫,该怎么办呢,也能算成负样本对嘛?
这是个问题,会有一点副作用的,也有一些论文对这个问题提出了新的解决方案
3. 应用
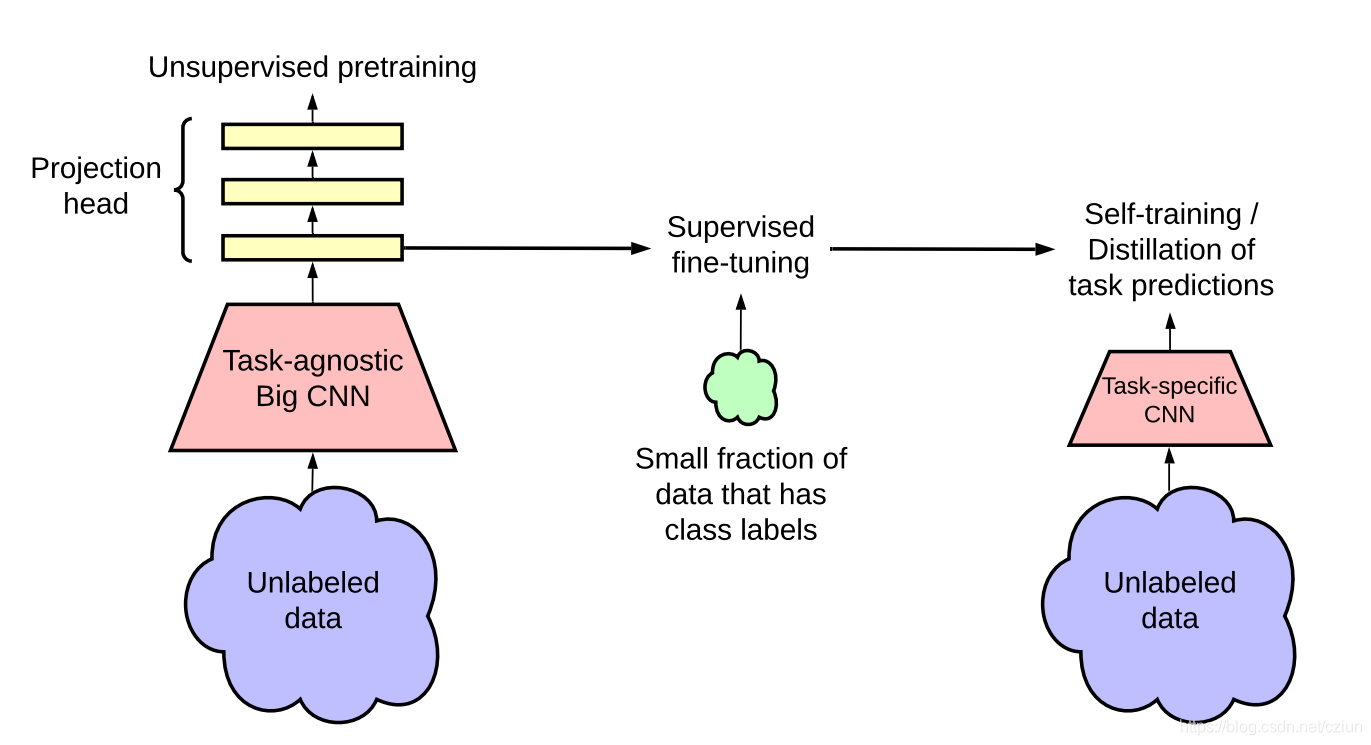
常用方法:自监督的预训练,有监督的微调,知识蒸馏