大家好,这是我们xgboost系列的第一篇。xgboost[1]是一个在机器学习面试中被问到的一个算法。
首先我们探讨一下理解xgboost的核心的一件事。那就是xgboost的数学模型,想要理解它,这个数学是跳不过去的。
xgboost是基于提升树的概念,这种思想就是说学习一棵树可能效果很差,因为一棵树比较不稳定,去除某些特征或者样本以后,重新训练树的结构会变化,这就导致预测的结果不稳定。
为了让模型的效果更鲁棒(结果更稳定一点),我们可以训练一棵树后,然后看树哪些地方没训练好,也就是说和目标的差距。然后再建一棵树,拟合这些差距。这就是boost方法的思路,
xgbosot是boost方法的一种。
下面我将从数据科学算法的通用特征讲起,一个算法需要首先知道它的目标函数,然后看有没有正则化啊,再看看优化手段,也就是说怎么让目标函数最小化。
一、优化的目标函数
首先xgboost的目标函数(损失函数)如下:
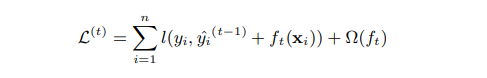
等式左边是t时刻的损失函数,又边的小l表示每个样本的损失,n表示样本数量。
小l里面有两项,第一项为:
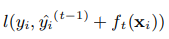
这是需要优化的损失,xgboost的预测值是第t步的预测值和t-1棵树的所有预测值的和作为预测的值。对于每个样本,每棵树都会给他分到一个叶节点。把这t棵树的叶节点相加就是树第t步的预测。
我们希望预测和真实值之间相差很小,比如可以选择mse作为损失函数。
第二项为:
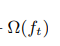
这是一个正则项。式子中的t都表示第t颗树,也就是说对每棵树都这么操作。
二、正则项的真实面目
刚接触到xgboost,我感觉非常的牛,树不像LR或者神经网络一样有明显的参数,怎么做正则化呢?
正则化的本质是减少树的复杂度,树的复杂度可以用树的深度、叶节点的个数表示。
xgboost也用到了类似的想法。xgboost的一棵树的正则化公式如下:
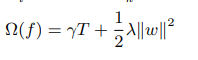
等式右边第一项T表示叶节点的个数。第二项的w看着跟神经网络的参数类似,其实我们可以把树的叶节点的值当作树优化的目标,这个w就是每个叶节点的值。两边的系数是参数。
三、如何最小化目标函数?
高数中我们都学过泰勒展开式,xgboost也用了泰勒展开式的例子。假如我们在
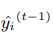
把损失函数按照二阶泰勒公式展开,则损失函数变成:
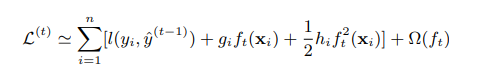
gi为在
的一阶导数,hi为二阶倒数。
将常数去掉后,损失函数为:
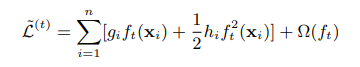
如果定义Ij为第j个叶节点,公式为:
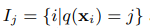
里面的i是说第i个样本,q是一个映射函数,意思是将Xi映射到第j个节点。
将损失函数改写成下式:
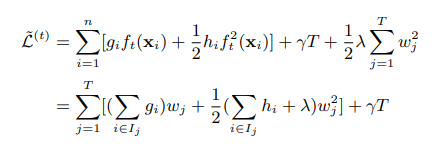
我们需要求极值,我们需要求的参数是w,也就是叶节点的值,直接将第二行求导等于0就可以,得:
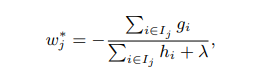 ’
’
将wj带入到上面损失函数的式子中得:
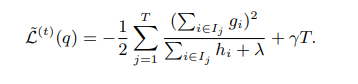
四、分裂点的度量
在第三小节,我们知道了当我们知道树的结构的时候,如何分配叶节点的值,让损失函数最小化。本小结讲述xgboost如何度量分裂点。决策树可以是信息增益、基尼指数等。xgboost也有一个类似的度量方法。
xgboost是一个二叉树,也就是说,从根节点出发, 分出两个岔。它的计算方法是分裂一棵树,然后计算损失函数减小的值,哪种分裂方法损失函数减小得越多,就选哪种方法,计算公式如下:
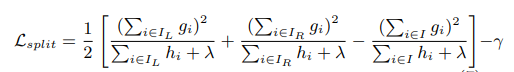
这个公式就是把当前的损失减去左右节点的损失。
总结:我们讲述了xgboost目标函数、正则化、如何优化目标函数、分裂点的度量,下一节将讲述树的分裂方法。
参考文献
[1] https://www.kdd.org/kdd2016/papers/files/rfp0697-chenAemb.pdf
