生产者
消息发送流程
Kafka 的 Producer 发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程main 线程和 Sender 线程,以及一个线程共享变量RecordAccumulator。
main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka broker。

相关参数:
batch.size:只有数据积累到 batch.size 之后,sender 才会发送数据。
linger.ms:如果数据迟迟未达到 batch.size,sender 等待 linger.time 之后就会发送数据。
异步生产
先启动zookeeper和kafka集群,不再赘述
创建一个maven工程,导入依赖,版本可以在kafka的libs目录里查到

<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.1.1</version>
</dependency>
太慢了,我直接把linux的jar包拉过来了

这个时候才有速度

遇到了一个坑,windows连不上kafka,要先修改kafka的server配置文件,把advertised.listeners那一行的注释符号去掉 地址改为你的虚拟机ipv4地址,然后我把剩下两个改成9093和9094。

测试类:
public class MyProducer {
public static void main(String[] args) {
//生产者的配置信息
Properties properties = new Properties();
properties.put("bootstrap.servers","192.168.2.141:9092");//ip地址
properties.put("acks","all");//ack级别
properties.put("retries",2);//重试次数
properties.put("batch.size",16384);//批次大小16KB
properties.put("linger.ms",1);//等待时间 达到批次大小或等待时间发送
properties.put("buffer.memory",33554432);//缓冲区大小32MB
//key和value(都是String)类的序列化
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//创建生产者对象
Producer<String, String> producer = new KafkaProducer<>(properties);
//发送数据
for(int i=0;i<10;i++)
producer.send(new ProducerRecord<>("data", "i want offer 202" + i));
producer.close();
}
}
重新启动kafka集群,使用consumer消费数据

运行idea的main方法,观察输出

可以发现数据并不是按0123456这样的顺序输出的,在上一篇文章中创建data主题时指定了分区数为2,因此0 2 4 6 8进入了一个分区,1 3 5 7 9进入了一个分区,分区数据是批量发送的,所以结果是1357902468。

可以使用ProducerConfig取代设置的常量字符串

刚才的程序可改为
public static void main(String[] args) {
//生产者的配置信息
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.2.141:9092");//ip地址
properties.put(ProducerConfig.ACKS_CONFIG,"all");//ack级别
properties.put(ProducerConfig.RETRIES_CONFIG,2);//重试次数
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);//批次大小16KB
properties.put(ProducerConfig.LINGER_MS_CONFIG,1);//等待时间 达到批次大小或等待时间发送
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);//缓冲区大小32MB
//key和value(都是String)类的序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
//创建生产者对象
Producer<String, String> producer = new KafkaProducer<>(properties);
//发送数据
for(int i=0;i<10;i++)
producer.send(new ProducerRecord<>("data", "i want offer 202" + i));
producer.close();
}
昨天写到了这里…笔面试忙了两天 现在继续
带回调函数的生产
主要是在send方法中多加了一个匿名函数
public class CallbackProducer {
public static void main(String[] args) {
//配置信息
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.2.141:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
//创建生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
//生产数据
for (int i = 0; i < 10; i++){
int finalI = i;
producer.send(new ProducerRecord<>("data", "面试求过--" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
System.out.println(finalI +": 分区是: " + recordMetadata.partition() + " offset: " + recordMetadata.offset());
}
}
});
}
producer.close();
}
}
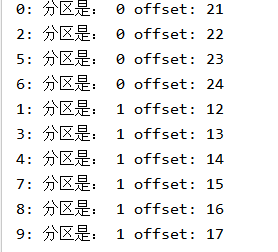
观察linux客户端,可见还是按分区批量生产数据的

观察IDEA控制台的输出,也可以发现是按分区发送数据的,kafka默认使用range分区策略,所以会存在消费量不一致问题,分区1之前存有6个数据,所以offset从7开始。分区2是5个。

生产者分区策略测试
上一篇说过分区的原则

所以我们也可以指定分区为0

此时数据会全部生产到分区0

不指定分区,会按照key的hash值计算

自定义分区器
通过实现Partitioner接口实现,return 1简单模拟分区全为1。
//自定义分区器
public class MyPartition implements Partitioner {
@Override
public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
return 1;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}

运行,可以发现分区全部在1

同步生产
由于 send 方法返回的是一个 Future 对象,根据 Futrue 对象的特点(获取返回结果前会阻塞),我们也可以实现同步发送的效果,只需在调用 Future 对象的 get 方发即可。

消费者
消费数据
创建一个消费者测试类,启动生产者后,观察控制台的输出
public class MyConsumer {
public static void main(String[] args) {
//消费者配置信息
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.2.141:9092");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);//开启自动提交
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000");//自动提交时间为1s
//要反序列化的类
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group1");
//消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
//订阅主题
consumer.subscribe(Collections.singletonList("data"));
while (true) {
//获取数据
ConsumerRecords<String, String> messages = consumer.poll(Duration.ZERO);
//解析并打印
for (ConsumerRecord<String, String> message : messages) {
System.out.println("key: " + message.key() + ",value: " + message.value());
}
}
}
}
结果:

从头消费数据
消费者从offset开始消费数据,如果需要从头消费需要重置offset
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
但同时还需要改变消费者组,否则此时重置不会生效
此时消费者仍属于消费者组group1,所以offset重置失败

当消费者组改为group2时,offset置0,相当于读取到了全部数据

offset读取问题
关闭自动提交

运行消费者,运行生产者生产10条数据,读取到了10条数据

关闭生产者,重启消费者,会将刚才的10条数据自动读出来

不要关闭消费者,再次运行生产者,也会读取到新的10条数据

此时关闭生产者,重启消费者,直接读取到了20条数据

解释:因为关闭了自动提交,所以offset的最新值最终没有更新
假设一开始是0,读了10条信息,offset到了10,但是没有更新所以还是0,下次重启时从0直接读到了10
然后又加入了10条数据,等于有了20条,再次重启,从0读到了20。
手动提交offset
虽然自动提交 offset 十分简便,但由于其是基于时间提交的,开发人员难以把握
offset 提交的时机,因此 Kafka 还提供了手动提交 offset 的 API。
手动提交 offset 的方法有两种:分别是 commitSync(同步提交)和 commitAsync(异步
提交)。
两者的相同点是,都会将本次 poll 的一批数据最高的偏移量提交;不同点是,
commitSync 阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而 commitAsync 则没有失败重试机制,故有可能提交失败
同步:

异步:

也可以在异步方法通过匿名内部类处理错误

