评估方法
关键:怎么获得“测试集”(test set) ?
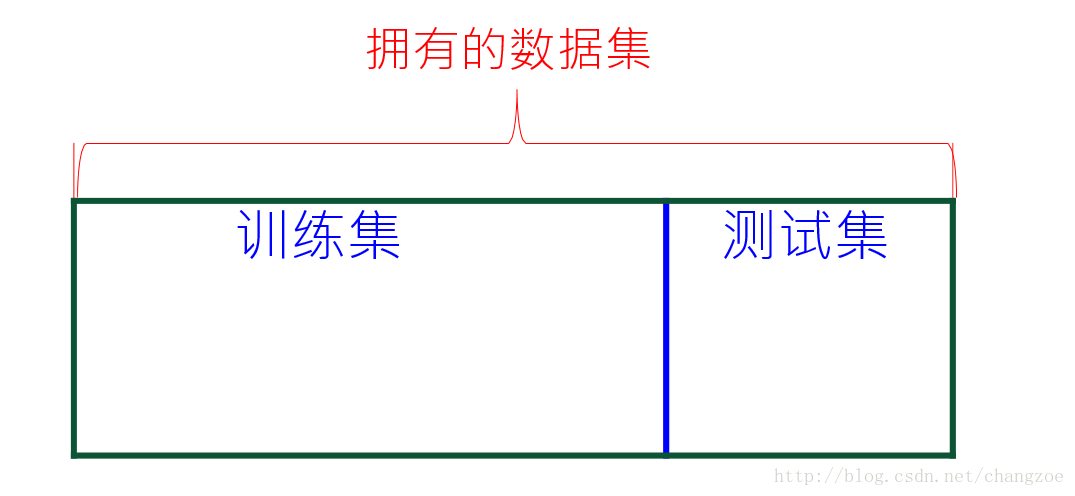
测试集应该与训练集“互斥”
常见方法:
- 留出法 (hold-out)
- 交叉验证法 (cross validation)
- 自助法 (bootstrap)
留出法

注意:
保持数据分布一致性 (例如: 分层采样)
多次重复划分 (例如: 100次随机划分)
测试集不能太大、不能太小 (例如:1/5~1/3)
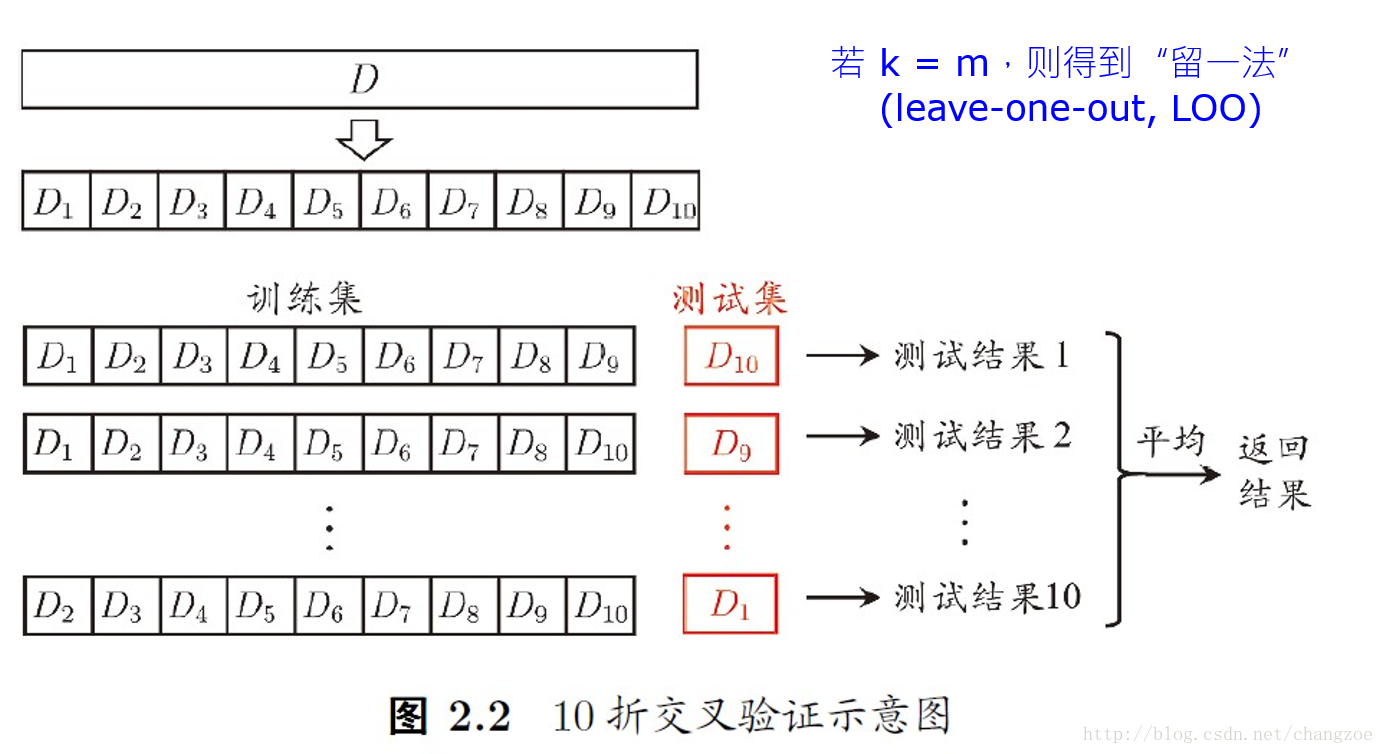
k-折交叉验证法
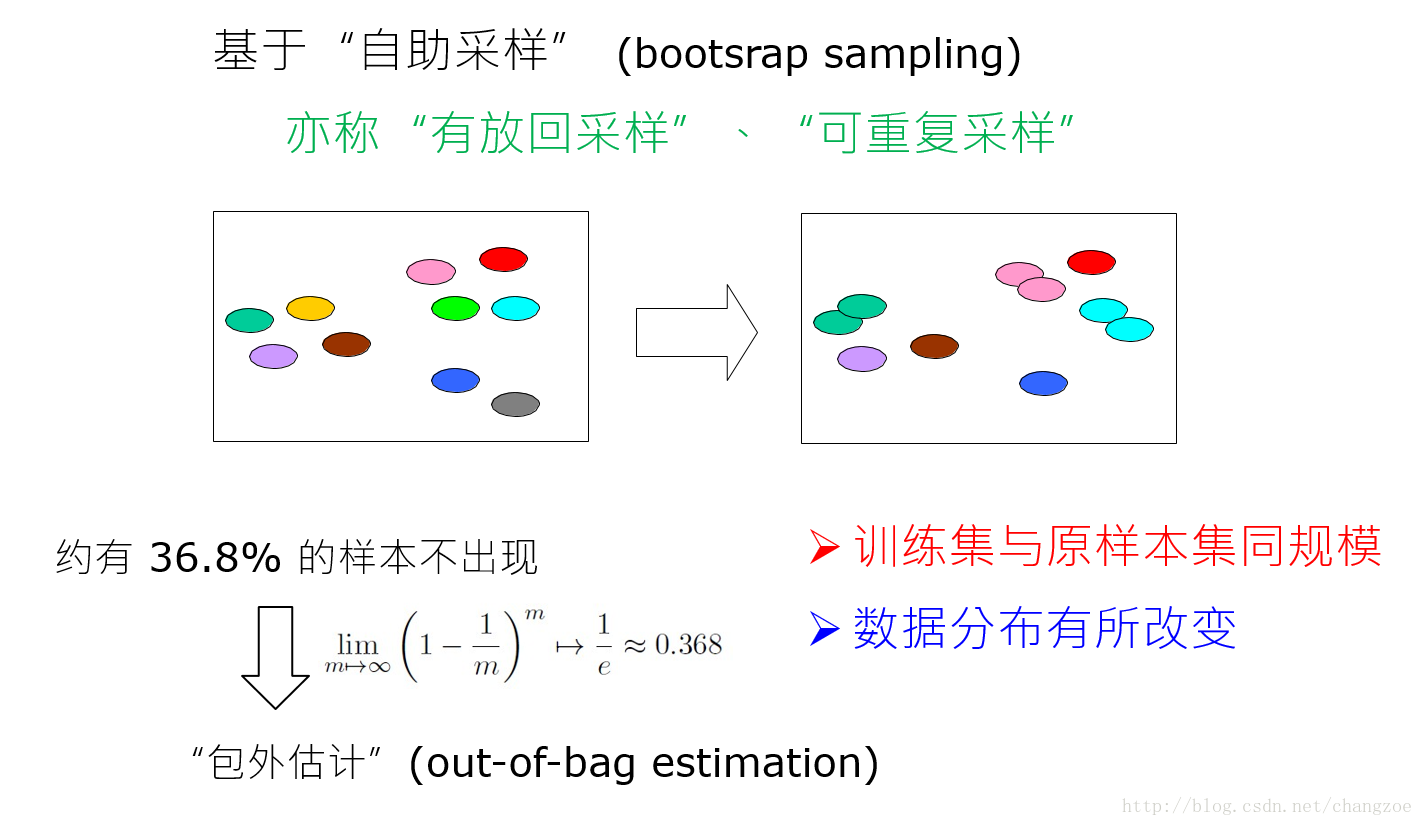
自助法

sklearn.cross_validation模块
cross validation大概的意思是:对于原始数据我们要将其一部分分为traindata,一部分分为test data。train data用于训练,test data用于测试准确率。在test data上测试的结果叫做validation error。将一个算法作用于一个原始数据,我们不可能只做出随机的划分一次train和testdata,然后得到一个validation error,就作为衡量这个算法好坏的标准。因为这样存在偶然性。我们必须多次的随机的划分train data和test data,分别在其上面算出各自的validation error。这样就有一组validationerror,根据这一组validationerror,就可以较好的准确的衡量算法的好坏。crossvalidation是在数据量有限的情况下的非常好的一个evaluate performance的方法。而对原始数据划分出train data和testdata的方法有很多种,这也就造成了cross validation的方法有很多种。
kFold
classsklearn.model_selection.KFold(n_splits=3,shuffle=False, random_state=None)
参数:
n_splits : 默认3,最小为2;K折验证的K值
shuffle : 默认False;shuffle会对数据产生随机搅动(洗牌)
random_state :默认None,随机种子
方法:
get_n_splits([X, y, groups]) Returnsthe number of splitting iterations in the cross-validator
split(X[, y, groups]) Generateindices to split data into training and test set.
>>> import numpy as np
>>> from sklearn.model_selection import KFold
>>> X = ["a", "b", "c", "d"]
>>> kf = KFold(n_splits=2)
>>> for train, test in kf.split(X):
... print("%s %s" % (train, test))
[2 3] [0 1]
[0 1] [2 3]Repeated K-Fold
重复KFold重复K次折叠n次。 当需要运行KFold n次时,可以使用它,在每次重复中产生不同的分割。
>>> import numpy as np
>>> from sklearn.model_selection import RepeatedKFold
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
>>> random_state = 12883823
>>> rkf = RepeatedKFold(n_splits=2, n_repeats=2, random_state=random_state)
>>> for train, test in rkf.split(X):
... print("%s %s" % (train, test))
...
[2 3] [0 1]
[0 1] [2 3]
[0 2] [1 3]
[1 3] [0 2]Leave One Out
>>> from sklearn.model_selection import LeaveOneOut
>>> X = [1, 2, 3, 4]
>>> loo = LeaveOneOut()
>>> for train, test in loo.split(X):
... print("%s %s" % (train, test))
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]Leave P Out (LPO)
与Leave-One-Label-Out类似,但这种策略每次取p种类标号的数据作为测试集,其余作为训练集。
>>> from sklearn.model_selection import LeavePOut
>>> X = np.ones(4)
>>> lpo = LeavePOut(p=2)
>>> for train, test in lpo.split(X):
... print("%s %s" % (train, test))
[2 3] [0 1]
[1 3] [0 2]
[1 2] [0 3]
[0 3] [1 2]
[0 2] [1 3]
[0 1] [2 3]Stratified k-fold
与k-fold类似,将数据集划分成k份,不同点在于,划分的k份中,每一份内各个类别数据的比例和原始数据集中各个类别的比例相同。
>>> from sklearn.model_selection import StratifiedKFold
>>> X = np.ones(10)
>>> y = [0, 0, 0, 0, 1, 1, 1, 1, 1, 1]
>>> skf = StratifiedKFold(n_splits=3)
>>> for train, test in skf.split(X, y):
... print("%s %s" % (train, test))
[2 3 6 7 8 9] [0 1 4 5]
[0 1 3 4 5 8 9] [2 6 7]
[0 1 2 4 5 6 7] [3 8 9]train_test_split
>>> import numpy as np
>>> from sklearn.model_selection import train_test_split
>>> from sklearn import datasets
>>> from sklearn import svm
>>> iris = datasets.load_iris()
>>> iris.data.shape, iris.target.shape
((150, 4), (150,))
>>> X_train, X_test, y_train, y_test = train_test_split(
... iris.data, iris.target, test_size=0.4, random_state=0)
>>> X_train.shape, y_train.shape
((90, 4), (90,))
>>> X_test.shape, y_test.shape
((60, 4), (60,))
>>> clf = svm.SVC(kernel='linear', C=1).fit(X_train, y_train)
>>> clf.score(X_test, y_test)
0.96...cross_val_score
sklearn.cross_validation.cross_val_score(estimator, X, y=None, scoring=None, cv=None,n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')
返回值就是对于每次不同的的划分raw data时,在test data上得到的分类的准确率。
参数解释:
estimator:是不同的分类器,可以是任何的分类器。比如支持向量机分类器:estimator = svm.SVC(kernel='linear', C=1)
cv:代表不同的cross validation的方法。如果cv是一个int值,并且如果提供了rawtarget参数,那么就代表使用StratifiedKFold分类方式;如果cv是一个int值,并且没有提供rawtarget参数,那么就代表使用KFold分类方式;也可以给定它一个CV迭代策略生成器,指定不同的CV方法。
scoring:默认Nnoe,准确率的算法,可以通过score_func参数指定;如果不指定的话,是用estimator默认自带的准确率算法>>> from sklearn.model_selection import cross_val_score
>>> clf = svm.SVC(kernel='linear', C=1)
>>> scores = cross_val_score(clf, iris.data, iris.target, cv=5)
>>> scores
array([ 0.96..., 1. ..., 0.96..., 0.96..., 1. ])
#置信区间
>>> print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
Accuracy: 0.98 (+/- 0.03)默认情况下,每个CV迭代计算的得分是估计器的得分方法。 可以通过使用评分参数来改变这一点:
>>> from sklearn import metrics
>>> scores = cross_val_score(
... clf, iris.data, iris.target, cv=5, scoring='f1_macro')
>>> scores
array([ 0.96..., 1. ..., 0.96..., 0.96..., 1. ])请参阅评分参数:详细定义模型评估规则。 在Iris数据集的情况下,样本在各个目标类别之间是平衡的,因此准确度和F1得分几乎相等。
当cv参数是一个整数时,cross_val_score默认使用KFold或StratifiedKFold策略,如果估计器来自ClassifierMixin,则使用后者。
也可以通过传递交叉验证迭代器来使用其他交叉验证策略,例如:
>>> from sklearn.model_selection import ShuffleSplit
>>> n_samples = iris.data.shape[0]
>>> cv = ShuffleSplit(n_splits=3, test_size=0.3, random_state=0)
>>> cross_val_score(clf, iris.data, iris.target, cv=cv)
...
array([ 0.97..., 0.97..., 1. ])