过拟合:
完美实际希望的,在新样本上表现的很好的学习器。为了达到这个目的,应该从训练样本中学习出适用于所有潜在样本的普遍规律,然而,学习器把样本学的太好,会把训练样本自身的一些特点当前潜在样本会有的特质,这样会导致泛化性能下降。与之相反的是欠拟合,对训练样本一般性质尚未学好
评估方法
- 留出法:直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T。即D=SUT,S交T=空。在S上训练出模型后,用T来评估其测试误差,作为对泛化误差的估计。需要注意的是,训练测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响
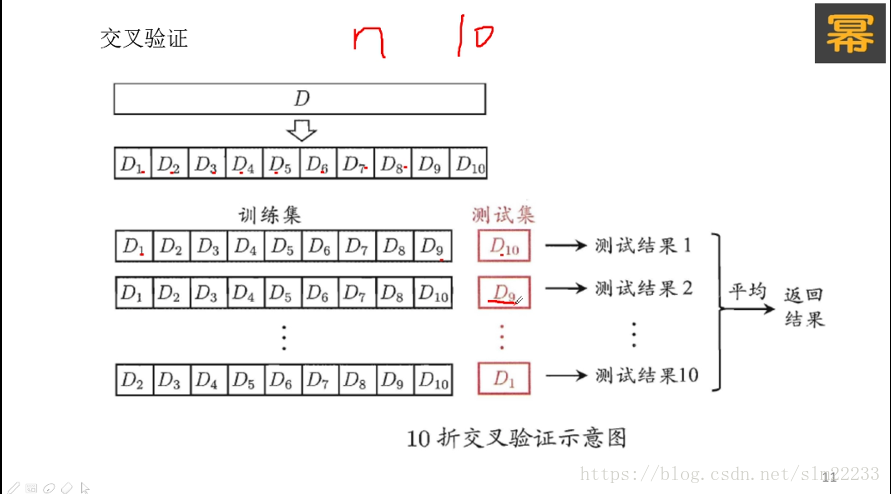
- 交叉验证法:
特殊的交叉验证,留一法:每次只有一个样本用于验证,适用于数据集非常小的情况,当数据量过大时,留一法的复杂度比较高
3.自助法:给定m个样本的数据集D,我们对他进行采样的数据集D’,每次从D中随机挑选一个样本,将其放入D’,然后再放回数据集D,使得样本在下次采样时仍有可能被采到,这个过程重复执行m次后,我们就得到包含m个数据集的样本D’。称为自助采样,通过自助采样,初始数据集D中约有36.8%的样本未出现在样本数据集D’中,于是,我们可以用D’用作训练集,D\D’用作测试集(36.8%的样本),实际评估的模型与期望评估的模型都使用m个训练样本,而我们仍有数据总量1/3的,没在训练集中出现的样本用于测试,这样的测试称‘包外估计’
自助法适用场景:数据集较小,难以有效划分训练/测试集。但自助法改变了初始数据的分布,这会引入估计偏差。因此,在数据量足够时,留出法和交叉验证法更有用一些