深度学习丢弃法调参分析
net = nn.Sequential(
d2l.FlattenLayer(),
nn.Linear(num_inputs, num_hiddens1),
nn.ReLU(),
nn.Dropout(drop_prob1),
nn.Linear(num_hiddens1, num_hiddens2),
nn.ReLU(),
nn.Dropout(drop_prob2),
nn.Linear(num_hiddens2, 10)
)
#初始化参数
for param in net.parameters():
nn.init.normal_(param, mean=0, std=0.01)
#定义优化器
optimizer = torch.optim.SGD(net.parameters(), lr=0.5, weight_decay = 0.01)
#训练模型
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs,
batch_size, None, None, optimizer)
(1)如果把本节中的两个丢弃概率超参数对调,会有什么结果?
将
drop_prob1, drop_prob2 = 0.2, 0.5
改为
drop_prob1, drop_prob2 = 0.5, 0.2
结果为

结论思路:因为增大了输入层的丢弃率,考虑模型收敛情况。
(提示:输入层的丢弃率设置要低)
(2)增大迭代周期数,比较使用丢弃法与不使用丢弃法的结果。
1.不使用丢弃法即将
nn.Dropout(drop_prob1)
改为
nn.Dropout(0)
如果有多个,则其他也进行更改
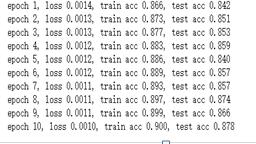
2.接着将num_epochs改为一个更大的值,小编将num_epochs改为10
没使用丢弃法
使用了丢弃法
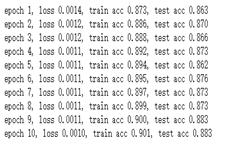
结论:从在周期较小时进行分析,同时也就随着周期的增加进行分析。
(3)如果将模型改得更加复杂,如增加隐藏层单元,使用丢弃法应对过拟合的效果会更加明显吗?
将num_hiddens1, num_hiddens2改为更大的数

结论思路:增加了隐藏层单元后,从模型复杂程度,收敛速度,但是收敛效果进行分析
(4)比较使用丢弃法与权重衰减的效果。如果同时使用丢弃法和权重衰减,效果会如何?
添加weight-decay参数,可在SGD中使用权重衰减

解题思路:
将以下方案相应的超参数进行更改即可。
1.只使用丢弃法,不使用权重衰减(是否使用weight-decay参数)
2.只使用权重衰减,不使用丢弃法(上文提及)
3.两者同时使用(同时使用)
即可将这三者进行分析比较。
