python3爬虫系列17之爬虫增速多进程,进程池的用法(白话解释)
1.前言
上一篇文章呢,
python3爬虫系列15之多线程爬取汽车之家批量下载图片,我们采用了多线程的方式来爬取,
在耗时环节呢,感觉并不是很快,才600多张图片花了近21秒。
至于原因呢,也在最后告诉了大家,
多线程下的 GIL 锁让python的多线程显得有点鸡肋, GIL锁 即全局排他锁,保护了数据安全性的同时,使得多线程提高效率的能力几乎丧失,在我们的多核CPU电脑上,Python 的多线程爬虫效率并不高。
所以想要充分利用 CPU,还是用多进程,这样我们就可以做到并行爬取,提高爬取的效率。
那么怎么创建进程呢?怎么创建多进程呢?怎么创建进程池呢?怎么并行爬取呢?
那还得从我们的搬砖说起。。。。

2.多进程—multiprocessing 模块的使用
python中,可以使用 multiprocessing 的模块 来实现多进程。
那还是以鼠标的工作为例。
2.1 使用 Process 类来创建进程
【任务:鼠标每天在工地搬砖,一天搬砖20块,每块1.5元,那么鼠标一天工资多少?】
让进程帮忙算算:
Process类也是属于multiprocessing 模块的一个方法。
# 使用 Process 类来创建进程
from multiprocessing import Process
import time
def job_time(name, delay, counter):
while counter<=20:
time.sleep(delay)
print("%s 搬%d块砖 %s" % (name,counter, time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())))
print('应得工资:', (counter * 1.5))
counter += 1
if __name__ == '__main__':
p = Process(target=job_time, args=('鼠标',1,1)) # 调用执行的方法和参数
p.start() # 启动进程
p.join() # 让进程执行完毕再结束
运行结果:

辛苦的鼠标一天搬砖挣30块钱~~~
使用 Process 类,就可以来创建进程,多组进程就使用 多条
p = Process(target=job_time, args=('鼠标',1,1)) # 调用执行的方法和参数
p2 = Process(target=job_time, args=('鼠标2',1,1)) # 调用执行的方法和参数
p3 = Process(target=job_time, args=('鼠标3',1,1)) # 调用执行的方法和参数
.....
语句,这样就形成多进程。
所以!
类比于线程,频繁的创建进程和销毁进程,也是要对浪费的,所以我们也有个管理的容器——线程池。
2.2 使用进程池Pool的方式来创建多进程
一个使用进程池multiprocessing.Pool来计算的小李子。。
# 使用进程池multiprocessing.Pool
from multiprocessing import Pool
import time
def func(fn):
# fn: 函数参数是数据列表的一个元素
time.sleep(0.5)
return fn * fn
if __name__ == '__main__':
with Pool(4) as p:
print(p.map(func, [1, 2, 3]))
运行结果:
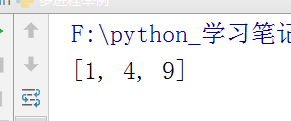
这样貌似也看不出来什么,所以补充一下,进程的执行方式还分为顺序执行和并行执行。
2.3 多进程的 【顺序执行】 和 【并行执行】
创建多个进程,来并发 与 顺序 执行,处理同一个数据,看看所用时间的差别。
多线程的串行方式 和 并行方式对比:
# 使用进程池multiprocessing.Pool
from multiprocessing import Pool
import time
def func(fn):
# fn: 函数参数是数据列表的一个元素
time.sleep(0.5)
return fn * fn
if __name__ == "__main__":
testFL = [1, 2, 3, 4, 5, 6]
print('============order===========') # 顺序执行(也就是串行执行,单进程))
s = time.time()
for fn in testFL:
func(fn)
e1 = time.time()
print("顺序执行时间:", (e1 - s),'秒')
print(func(fn))
print('=========concurrent=========') # 创建多个进程,并行执行
pool = Pool(4) # 创建拥有5个进程数量的进程池
# testFL:要处理的数据列表,run:处理testFL列表中数据的函数
rl = pool.map(func, testFL)
pool.close() # 关闭进程池,不再接受新的进程
pool.join() # 主进程阻塞等待子进程的退出
e2 = time.time()
print("并行执行时间:", (e2 - e1),'秒')
print(rl)
程序中的r1表示全部进程执行结束后全局的返回结果集,run函数有返回值,所以一个进程对应一个
返回结果,这个结果存在一个列表中,也就是一个结果堆中,实际上是用了队列的原理,等待所有进
程都执行完毕,就返回这个列表(列表的顺序不定)。
对Pool对象调用join() 方法会等待所有子进程执行完毕,调用join() 之前必须先调用close(),让其不再接受新的Process了。
运行:

从结果可以看出,并发执行的时间 明显 比 顺序执行要 快很多,但是进程是要耗资源的,所以平时工作中,进程数也不能开太大。所以一般根据电脑 CPU 的内核数量,来创建相应的进程池。
根据电脑 CPU 的内核数量来创建相应的进程池进程数:
pool = multiprocessing.Pool(multiprocessing.cpu_count())
记得我们的进程数不需要大于内核数。
总结:在 Python 里面推荐使【用多进程】而【不用多线程】吧。
你会发现速度翻了好几番了, 当然,下一次可以去爬取数据量大一些的数据,这样对比会更加明显一些。
通过例子来解释用法,是最好的方式了,我没有复制很多百度百科的解说语,当然也没有涉及非常全面和深的知识。我们只需要学会怎么把自己的爬虫代码改为多进程的方式就可以了。(解释都在代码里。)
下一篇,多进程爬虫实战。
( ^_ ^ )/~~拜拜
