最近全国高考结束,考生都在等分当中,鉴于自己之前一直有个想法,爬取各高校的信息,方便考生选择,因此完成了一下代码,爬取了全国2822所高校,包括本科和高职院校,在各省的分数线。
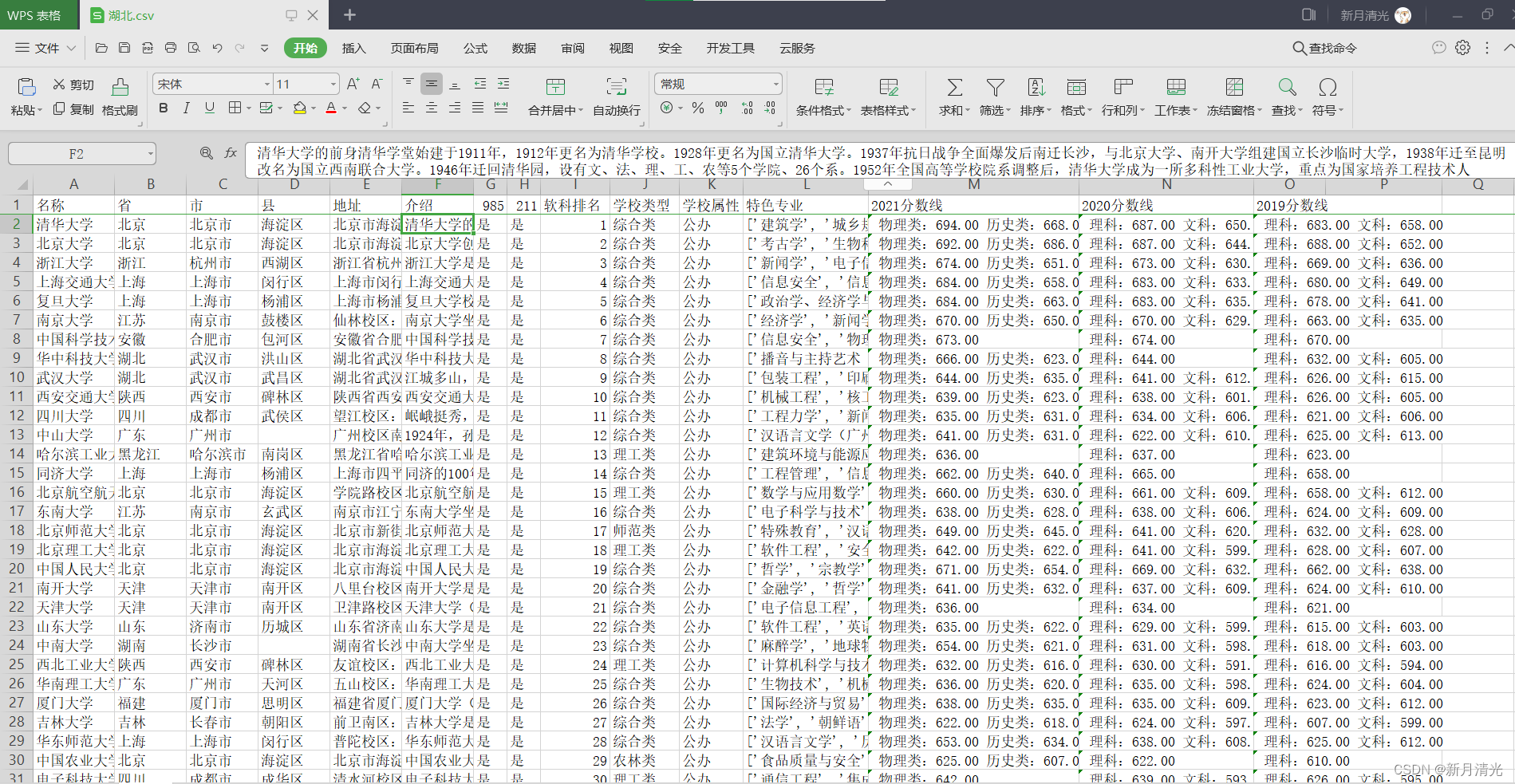
下图是各高校在湖北省的,经过高校软科排名排序后的近3年录取分数情况:
完整的数据下载地址:
链接:https://pan.baidu.com/s/1uohDZQk2SPSjI0htZBJd1g
提取码:z1db
数据中分数栏,空白部分,说明该学校在该省不招生。
部分代码如下,未优化…
from ast import Str
from time import sleep
import requests
import json
import csv
from sqlalchemy import null
def save_data(s,data):
with open('./'+s+'.csv', encoding='UTF-8', mode='a+',newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(data)
f.close()
print("#########"
" 版权所有:殷宗敏 & 数据接口来源-https://www.gaokao.cn/school/search & 在此表示感谢!"
"##########")
url = 'https://static-data.gaokao.cn/www/2.0/school/name.json'
html = requests.get(url).text
unicodestr=json.loads(html) #将string转化为dict
dat = unicodestr["data"]
province_id=[{"name":11,"value":"北京"},{"name":12,"value":"天津"},{"name":13,"value":"河北"},{"name":14,"value":"山西"},{"name":15,"value":"内蒙古"},{"name":21,"value":"辽宁"},{"name":22,"value":"吉林"},{"name":23,"value":"黑龙江"},{"name":31,"value":"上海"},{"name":32,"value":"江苏"},{"name":33,"value":"浙江"},{"name":34,"value":"安徽"},{"name":35,"value":"福建"},{"name":36,"value":"江西"},{"name":37,"value":"山东"},{"name":41,"value":"河南"},{"name":42,"value":"湖北"},{"name":43,"value":"湖南"},{"name":44,"value":"广东"},{"name":45,"value":"广西"},{"name":46,"value":"海南"},{"name":50,"value":"重庆"},{"name":51,"value":"四川"},{"name":52,"value":"贵州"},{"name":53,"value":"云南"},{"name":54,"value":"西藏"},{"name":61,"value":"陕西"},{"name":62,"value":"甘肃"},{"name":63,"value":"青海"},{"name":64,"value":"宁夏"},{"name":65,"value":"新疆"}]
for l in province_id:
header = ['名称', '省', '市', '县', '地址','介绍' ,'985','211','软科排名','学校类型','学校属性','特色专业',"2021分数线","2020分数线","2019分数线"]
with open('./'+l["value"]+'.csv', encoding='utf-8-sig', mode='w',newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(header)
f.close()
for i in dat:
schoolid = i['school_id']
schoolname = i['name']
url1 = 'https://static-data.gaokao.cn/www/2.0/school/'+schoolid+'/info.json'
print("正在下载"+schoolname)
html1 = requests.get(url1).text
unicodestr1=json.loads(html1) #将string转化为dict
if len(unicodestr1) !=0:
dat1 = unicodestr1["data"]
name = dat1["name"]
content = dat1["content"]
f985 = dat1["f985"]
if f985 =="1":
f985 = "是"
else:
f985 = "否"
f211 = dat1["f211"]
if f211 =="1":
f211 = "是"
else:
f211 = "否"
ruanke_rank = dat1["ruanke_rank"]
if ruanke_rank=='0':
ruanke_rank =''
type_name= dat1["type_name"]
school_nature_name = dat1["school_nature_name"]
province_name = dat1["province_name"]
city_name = dat1["city_name"]
town_name = dat1["town_name"]
address = dat1["address"]
special =[]
for j in dat1["special"]:
special.append(j["special_name"])
pro_type_min=dat1["pro_type_min"]
fen2021=''
fen2020=''
fen2019=''
for k in pro_type_min.keys():
# print(k)
# print(l["name"])
if int(k) == l["name"]:
print(pro_type_min[k])
for m in pro_type_min[k]:
if m['year'] == 2021:
s = ' '
for j in m['type'].keys():
if j == '2073':
s = s+'物理类:'+m['type'][j] +' '
if j == '2074':
s = s+'历史类:'+m['type'][j] +' '
if j == '1':
s = s+'理科:'+m['type'][j] +' '
if j == '2':
s = s+'文科:'+m['type'][j] +' '
if j == '3':
s = s+'综合类:'+m['type'][j] +' '
fen2021 = s
elif m['year'] == 2020:
s = ' '
for j in m['type'].keys():
if j == '2073':
s = s+'物理类:'+m['type'][j] +' '
if j == '2074':
s = s+'历史类:'+m['type'][j] +' '
if j == '1':
s = s+'理科:'+m['type'][j] +' '
if j == '2':
s = s+'文科:'+m['type'][j] +' '
if j == '3':
s = s+'综合类:'+m['type'][j] +' '
fen2020 = s
else:
s = ' '
for j in m['type'].keys():
if j == '2073':
s = s+'物理类:'+m['type'][j] +' '
if j == '2074':
s = s+'历史类:'+m['type'][j] +' '
if j == '1':
s = s+'理科:'+m['type'][j] +' '
if j == '2':
s = s+'文科:'+m['type'][j] +' '
if j == '3':
s = s+'综合类:'+m['type'][j] +' '
fen2019 = s
tap = (name,province_name,city_name,town_name,address,content,f985,f211,ruanke_rank,type_name,school_nature_name,special,fen2021,fen2020,fen2019)
save_data(l["value"],tap)