一 机器学习算法类别
1.1 按照学习方式分类
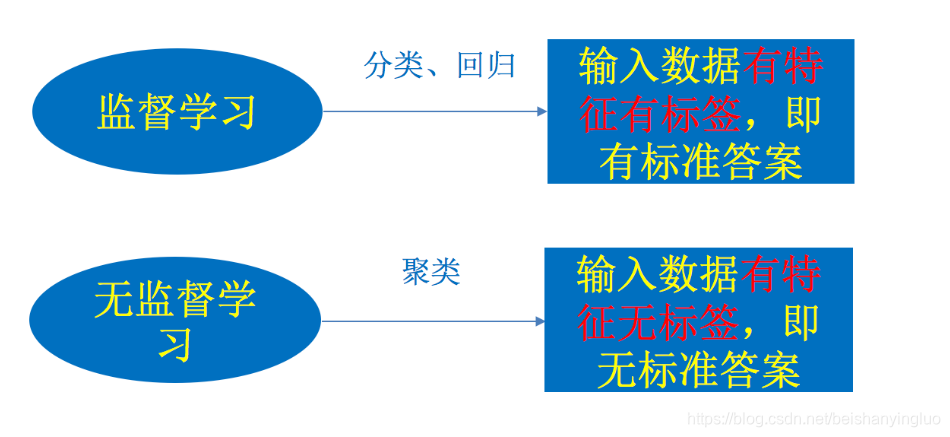
- 监督学习(supervised learning)(预测)
①定义:输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类)。
②分类 k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
③回归 线性回归、岭回归
④ 标注 隐马尔可夫模型 (不做要求) - 无监督学习(unsupervised learning)
①定义:输入数据是由输入特征值所组成。
②聚类 k-means
③半监督和强化学习
1.2 区别
1.3 理解监督无监督
1.4 关于监督学习中的分类与回归区别
1) 数据类型
-
离散型数据:由记录不同类别个体的数目所得到的数据,又称计数数据,所有这些数据全部都是整数,而且不能再细分,也不能进一步提高他们的精确度。
-
连续型数据:变量可以在某个范围内取任一数,即变量的取值可以是连续的,如,长度、时间、质量值等,这类整数通常是非整数,含有小数部分。
注:只要记住一点,离散型是区间内不可分,连续型是区间内可分
-
分类:目标值数据类型为离散型
分类是监督学习的一个核心问题,在监督学习中,当输出变量取有限个离散值时,预测问题变成为分类问题,最基础的便是二分类问题,即判断是非,从两个类别中选择一个作为预测结果; -
回归:目标值数据类型为连续型
回归是监督学习的另一个重要问题。回归用于预测输入变量和输出变量之间的关系,输出是连续型的值。
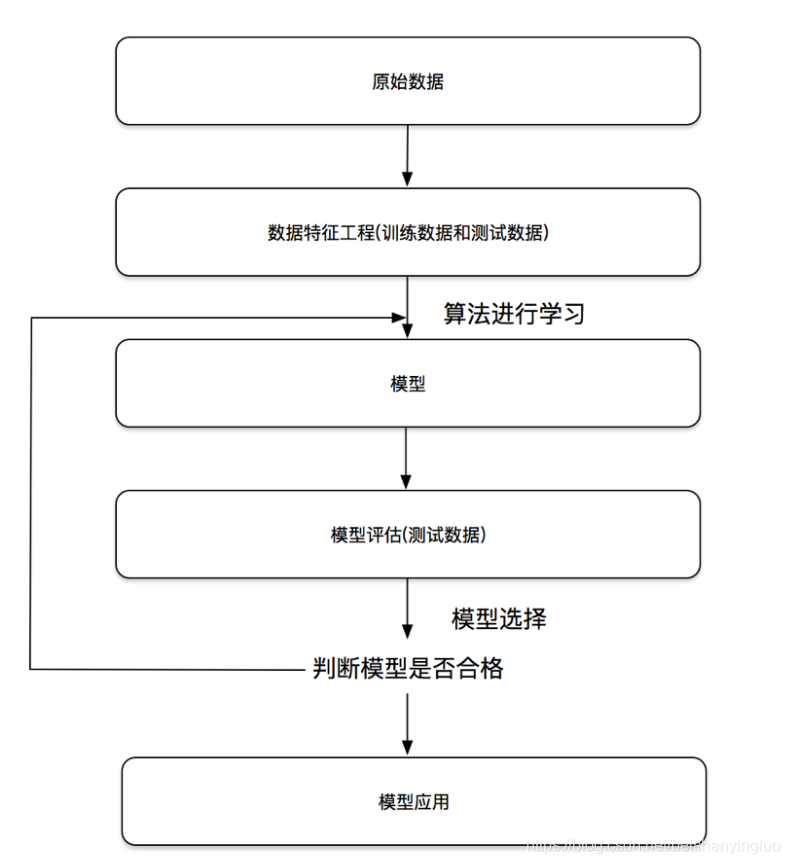
二 机器学习 开发流程
- 1.原始数据明确问题做什么;
- 2.数据的基本处理:pd去处理数据,缺失值,合并表等;
- 3.特征工程 (特征处理)
- 4.找到合适的算法进行预测
- 5.模型的评估,判定效果