在上次的笔记OpenCV4学习笔记(42)中,使用OpenCV自带的HOG+SVM行人检测模型来对图像中的行人进行检测,而在实际应用中我们更多的是需要针对自定义对象进行检测,所以今天就来整理一下在OpenCV中如何基于HOG特征与SVM线性分类器来实现对我们自定义对象的检测。
首先我们需要训练针对自定义对象的SVM模型,通过提取样本图像的HOG特征描述子,来生成样本的特征数据,再通过SVM线性分类器对这些特征数据进行分类学习与训练,并且还可以将训练结果保存为 .xml 或 .yml 模型文件,这样以后就可以通过加载这些模型来实现对同一种对象的检测。
训练自定义对象的SVM模型,其步骤可以大致分为如下几步:
(1)读取我们用来训练的正负样本图像,并组织成为训练样本集;
(2)分别计算正负样本中每张图像的HOG特征描述子,并进行标注,从而生成样本数据的标签集;
(3)对训练样本集进行格式转化,变成SVM分类器所能接受的样本格式;
(4)通过OpenCV的SVM分类器进行模型的训练,并将训练好的模型保存下来。
在读取样本图像时,我们使用glob()这个API来对同一文件夹中的多张图像进行读取并转化为string类型,注意读取进来的是每张图像的路径。随后就可以通过imread()来循环读取所有图像,将string类型数据转化为Mat类型。
接着利用读取进来的Mat类型数据来制作正负样本图像数据集,注意这里可以把样本图像缩放为Size(64,128)的尺寸大小,刚好和计算HOG特征描述子时所默认采用的开窗尺寸大小一致。
接着我们就需要对每一张样本图像进行HOG特征描述子的计算,并且建立样本数据集的标签集。当我们获取到所有样本图像的HOG特征描述子后,再把这些特征数据按行来进行组织,生成我们进行SVM模型训练时所需要的包含样本图像HOG特征描述子的数据集。
经过上述步骤,我们就得到了训练所需的数据集和标签集,接下来就可以通过创建SVM分类器、设置训练参数,输入训练数据集和标签集进行训练。在进行参数设置时,如果手动设置则需要对很多参数进行调节,这个过程是相当麻烦的。还好在OpenCV中提供了一个自动寻找最优参数的方法,该方法通过测试参数C、 gamma、p、nu、coef0, degree等参数,寻找当测试集错误的交叉验证估计值最小时这些参数的取值,这些参数取值会被认为是最佳的参数设置,然后自动训练SVM模型。
下面看一下代码演示:
//定义加载正样本数据和负样本数据的文件路径
string positive_path = "D:\\opencv_c++\\opencv_tutorial\\data\\dataset\\elec_watch\\positive\\";
string negative_path = "D:\\opencv_c++\\opencv_tutorial\\data\\dataset\\elec_watch\\negative\\";
//通过glob()将路径下的所有图像文件以string类型读取进来
vector<string> positive_images_str, negative_images_str;
glob(positive_path, positive_images_str);
glob(negative_path, negative_images_str);
//将string类型的图像数据转换为Mat类型
vector<Mat>positive_images, negative_images;
for (int i = 0; i < positive_images_str.size(); i++)
{
Mat positive_image = imread(positive_images_str[i]);
resize(positive_image, positive_image, Size(64, 128));
positive_images.push_back(positive_image);
}
for (int j = 0; j < negative_images_str.size(); j++)
{
Mat negative_image = imread(negative_images_str[j]);
resize(negative_image, negative_image, Size(64, 128));
negative_images.push_back(negative_image);
}
//分别获取正负样本中每张图像的HOG特征描述子,并进行标注
HOGDescriptor *hog_train = new HOGDescriptor;
vector<vector<float>> train_descriptors;
int positive_num = positive_images.size();
int negative_num = negative_images.size();
vector<int> labels;
for (int i = 0; i < positive_num; i++)
{
Mat gray;
cvtColor(positive_images[i], gray, COLOR_BGR2GRAY); //计算HOG描述子时需要使用灰度图像
vector<float> descriptor;
hog_train->compute(gray, descriptor, Size(8, 8), Size(0, 0));
train_descriptors.push_back(descriptor);
labels.push_back(1);
}
for (int j = 0; j < negative_num; j++)
{
Mat gray;
cvtColor(negative_images[j], gray, COLOR_BGR2GRAY);
vector<float> descriptor;
hog_train->compute(gray, descriptor, Size(8, 8), Size(0, 0));
train_descriptors.push_back(descriptor);
labels.push_back(-1);
}
//将训练数据vector转换为Mat对象,每一行为一个描述子,行数即为样本数
int width = train_descriptors[0].size();
int height = train_descriptors.size();
Mat train_data = Mat::zeros(Size(width, height), CV_32F);
for (int r = 0; r < height; r++)
{
for (int c = 0; c < width; c++)
{
train_data.at<float>(r, c) = train_descriptors[r][c];
}
}
//使用最优参数训练SVM分类器,并保存到与代码同目录下
auto train_svm = ml::SVM::create();
train_svm->trainAuto(train_data, ml::ROW_SAMPLE, labels);
train_svm->save("model.xml");
hog_train->~HOGDescriptor();
train_svm->clear();
至此,我们就针对自定义对象训练出了我们所需的SVM分类器模型,接下来我们就通过加载这个 .xml类型的模型来对测试图像进行自定义对象检测。
进行自定义对象检测的思路如下:
(1)首先加载我们的测试图像,并对其进行缩放、转灰度图像等相关的预处理操作;
(2)加载训练好的自定义对象检测模型;
(3)对测试图像进行开窗操作,以尺寸大小为(64,128)的窗口来对图像进行遍历开窗。注意在开窗时可以使窗口重叠,这样做优点是提高检测的准确度,但缺点是会带来多个检测框同时存在而降低运算速度。
在对测试图像进行开窗操作、寻找匹配的窗口区域时,开窗移动步长可以选择计算HOG特征描述子时的窗口步长,这样可以避免因为步长太小而导致检测框的数目过多而降低运行速度的情况发生,同时还可以避免步长太大而导致漏检的情况发生。
(4)最后求取多个检测框的平均值即可得到最终的检测框,也即对象所在区域,从而实现自定义对象检测。
下面来看一下代码演示:
//测试分类器
Mat test_image = imread("D:\\opencv_c++\\opencv_tutorial\\data\\dataset\\elec_watch\\test\\scene_02.jpg");
resize(test_image, test_image, Size(0,0), 0.2,0.2);
Mat test_gray_image;
cvtColor(test_image, test_gray_image, COLOR_BGR2GRAY);
HOGDescriptor* hog_test = new HOGDescriptor;
//加载训练好的SVM分类器
auto test_svm = ml::SVM::load("model.xml");
Rect winRect;
vector<float> descriptors;
vector<int>winRect_x, winRect_y;
for (int row = 64; row < test_image.rows -64; row += 8)
{
for (int col = 32; col < test_image.cols - 32; col += 8)
{
winRect.width = 64;
winRect.height = 128;
winRect.x = col - 32;
winRect.y = row - 64;
//计算当前窗口区域的HOG描述子,并转换为Mat对象
hog_test->compute(test_gray_image(winRect), descriptors);
Mat descriptor_mat = Mat::zeros(Size(descriptors.size(), 1), CV_32FC1);
for (int i = 0; i < descriptors.size(); i++)
{
descriptor_mat.at<float>(0, i) = descriptors[i];
}
//对当前窗口的描述子使用SVM模型进行预测,结果是1或-1
float result;
result = test_svm->predict(descriptor_mat);
if (result > 0)
{
//保存当前窗口左上角坐标
winRect_x.push_back(col - 32);
winRect_y.push_back(row - 64);
}
}
}
//如果存在检测出的对象框,则计算平均坐标点并绘制目标框
if (winRect_x.size() != 0)
{
int x = 0, y = 0;
for (int k = 0; k < winRect_x.size(); k++)
{
x += winRect_x[k];
y += winRect_y[k];
}
x = x / winRect_x.size();
y = y / winRect_y.size();
Rect dected_rect(x, y, 64, 128);
rectangle(test_image, dected_rect, Scalar(0, 255, 0), 1, 8, 0);
}
imshow("test_image", test_image);
hog_test->~HOGDescriptor();
test_svm->clear();
接下来看一下我们实现的自定义对象检测的效果怎样,这里使用的自定义对象是:

下面是在测试图像中的检测效果:
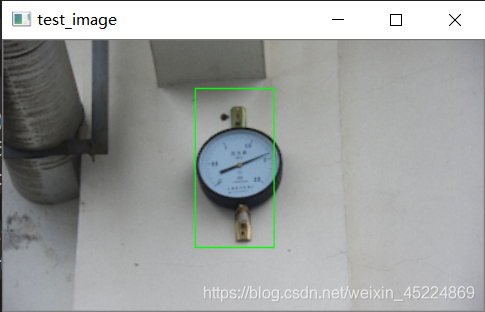
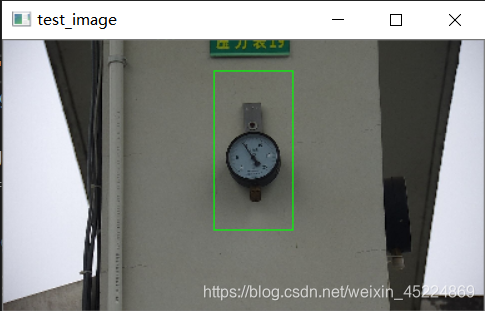
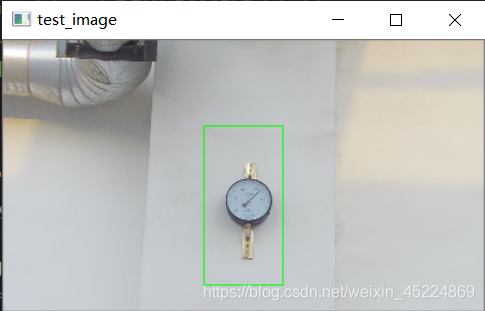
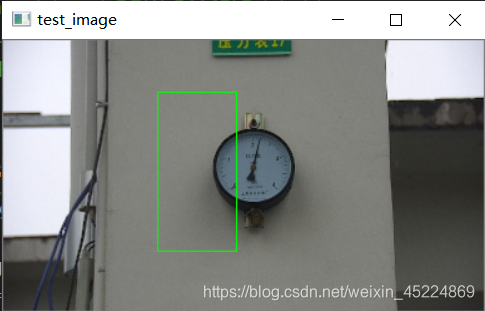
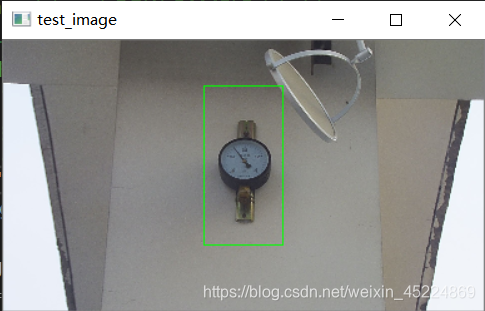
再来看另一个演示,所针对对象是“满月”,如下图(PS: 这里面用的月亮照片都是我自己拍的~):

下面是效果图:


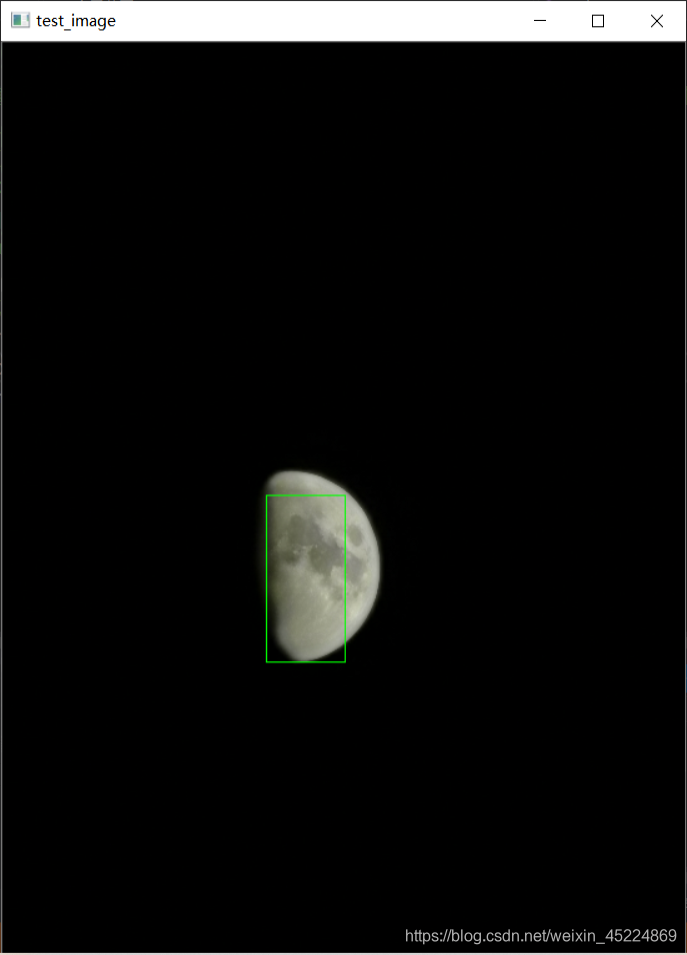

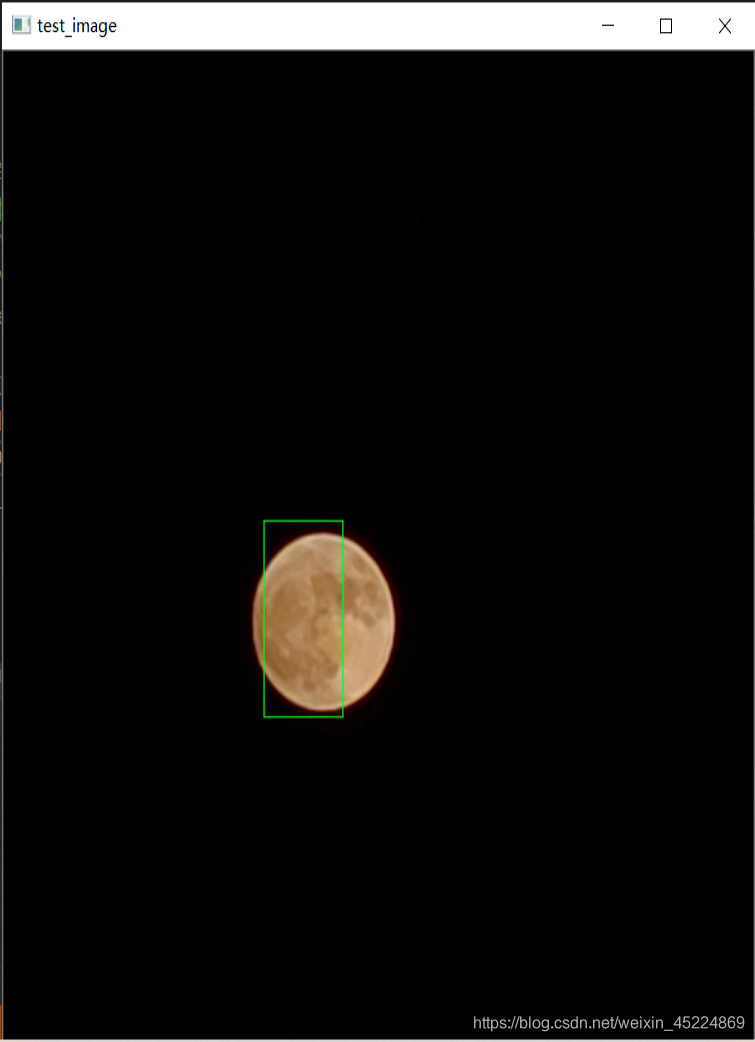
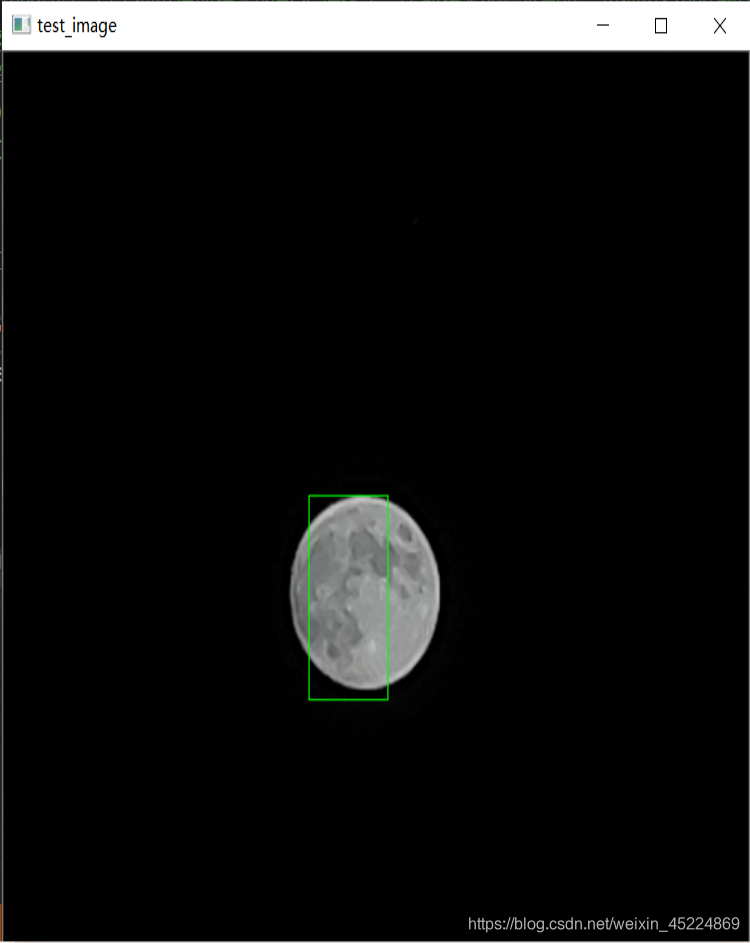
从测试结果可以看出,对于我们自定义对象的检测效果还是可以接受的,但还是会有些许偏差,仍然需要继续完善。如果对这个演示感兴趣的朋友可以在我的资源里下载完整代码以及测试图像哦~
好的,今天的笔记就整理到此为止啦,谢谢阅读~
PS:本人的注释比较杂,既有自己的心得体会也有网上查阅资料时摘抄下的知识内容,所以如有雷同,纯属我向前辈学习的致敬,如果有前辈觉得我的笔记内容侵犯了您的知识产权,请和我联系,我会将涉及到的博文内容删除,谢谢!
