目录
1.训练过程(即代码流程)
1. 准备训练样本集合: 包括正样本集合和负样本集合.
2. 对训练样本进行处理, 根据法国国家信息与自动化研究所行人数据库(INRIA Person DataBase)给出的样本集和图像信息, 进行样本采集.(Tools类中的 ImgCut() 函数)(这里进行处理的主要作用是对样本进行归一化, 将其归一到一个尺度(64*120))
3. 提取正样本的HOG特征.
4. 提取负样本的HOG特征.
5. 对正负样本进行标记, 正样本为1, 负样本为0.
6. 将正负样本的HOG特征及正负样本的标签输入 SVM 进行训练.
7. 训练后SVM 的结果保存在 Pedestrian.xml文件中.
8. 对得到的Pedestrian.xml文件输入进SVM得到行人检测分类器, 进行行人检测, 行人检测的主要会应用于智能交通, 此程序不仅可以对图片处理,还可以对视频进行处理, 并且是一个可视化的过程, 这里的视频数据来自加州理工行人检测基准数据(Caltech Pedestrian Detection Benchmark).
9. 对于难例的处理, 所谓的难例就是第一次训练出的分类器负样本原图中检测到的有行人的样本, 这些误报使得行人检测的分类器不是那么准确, 所以可以将误报的矩形框保存为新的负样本, 对新的负样本进行二次训练, 实现难例的处理.
注: 训练和测试数据集见附录, 结果见附件.
2.模型及结果优缺点分析
(1)此HOG + SVM进行行人检测的模型的分辨特征有以下几个:
1. 对于特征明显行人分辨能力强.
2. 目标单一时分辨能力强.
3. 干扰较少时分辨能力强.
(2)不足:
对于人群较多的图片和人物特征不明显的图片分辨能力较差.
(3)对于不足的改进:
1. 使用更多的样本进行训练.
2. 对于分辨错误的难例进行二次训练.
3.模型建立中发现的问题及改进方法
在进行HOG + SVM进行行人检测时, 时间消耗较长.对于训练的2416个正样本和12180个负样本进行两次训练共使用了595.919秒.
改进方法可以是进行CPU 并行优化, 可以分为三个线程, 确保每一个CPU核心都是满载.
1. 图像的预处理.
2. 提取HOG特征.
3. 使用SVM训练.
4.行人检测OpenCv 代码(C++)
1.ToolS类(处理负样本图片,把每张负样本随机裁剪十张没有人的图片并转换成jpg格式)#include "opencv2/core/core.hpp"
#include "opencv2/objdetect.hpp"
#include "opencv2/core/cuda.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/video/video.hpp"
#include "opencv2/ml.hpp"
#include "opencv2/opencv.hpp"
#include <opencv2/objdetect/objdetect.hpp>
#include <opencv2/imgcodecs.hpp>
#include <stdlib.h>
#include <time.h>
#include <algorithm>
#include <math.h>
#include <iostream>
#include <vector>
#include <fstream>
#include <cstdlib>
using namespace std;
using namespace cv;
using namespace cv::ml;
class Tools
{
public:
Tools();
int CropImageCount = 0; //裁剪出来的负样本图片个数
void ImgCut()
{
Mat src;
string ImgName;
char saveName[256];//裁剪出来的负样本图片文件名
ifstream fin("E:\\INRIAPerson\\Train\\neg.lst");//打开原始负样本图片文件列表
//一行一行读取文件列表
while (getline(fin, ImgName))
{
cout << "处理:" << ImgName << endl;
ImgName = "E:\\INRIAPerson\\" + ImgName;
src = imread(ImgName, 1);//读取图片
//cout<<"宽:"<<src.cols<<",高:"<<src.rows<<endl;
//图片大小应该能能至少包含一个64*128的窗口
if (src.cols >= 64 && src.rows >= 128)
{
srand(time(NULL));//设置随机数种子 time(NULL)表示当前系统时间
//从每张图片中随机采样10个64*128大小的不包含人的负样本
for (int i = 0; i<10; i++)
{
int x = (rand() % (src.cols - 64)); //左上角x坐标
int y = (rand() % (src.rows - 128)); //左上角y坐标
//cout<<x<<","<<y<<endl;
Mat imgROI = src(Rect(x, y, 64, 128));
sprintf_s(saveName, "E:\\INRIAPerson\\negphoto\\noperson%06d.jpg", ++CropImageCount);//生成裁剪出的负样本图片的文件名
imwrite(saveName, imgROI);//保存文件
}
}
}
}
~Tools();
};
2._Pedestrian类(行人检测)
主要包括以下函数:
(1) 取得SVM分类器
void get_svm_detector(const Ptr< SVM >& svm, vector< float > & hog_detector)
(2) 转化OpenCv机器学习算法所使用的训练和样本集
void convert_to_ml(const vector< Mat > & train_samples, Mat& trainData)
(3) 载入目录的图片样本
void load_images(const String &namefile,const String & dirname, vector< Mat > & img_lst, bool showImages = false)
(4) 计算HOG特征
void computeHOGs(const Size wsize, const vector< Mat > & img_lst, vector< Mat > & gradient_lst)
(5) 测试已经训练的分类器
int test_trained_detector(String obj_det_filename, String test_dir, String test_name_file,String videofilename)#include "opencv2/core/core.hpp"
#include "opencv2/objdetect.hpp"
#include "opencv2/core/cuda.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/video/video.hpp"
#include "opencv2/ml.hpp"
#include "opencv2/opencv.hpp"
#include <opencv2/objdetect/objdetect.hpp>
#include <opencv2/imgcodecs.hpp>
#include <stdlib.h>
#include <time.h>
#include <algorithm>
#include <math.h>
#include <iostream>
#include <vector>
#include <fstream>
#include <cstdlib>
using namespace std;
using namespace cv;
using namespace cv::ml;
class _Pedestrain
{
public:
_Pedestrain();
//函数声明
void get_svm_detector(const Ptr< SVM >& svm, vector< float > & hog_detector)
{
// get the support vectors
Mat sv = svm->getSupportVectors();
const int sv_total = sv.rows;
// get the decision function
Mat alpha, svidx;
double rho = svm->getDecisionFunction(0, alpha, svidx);
CV_Assert(alpha.total() == 1 && svidx.total() == 1 && sv_total == 1); //括号中的条件不满足时,返回错误
CV_Assert((alpha.type() == CV_64F && alpha.at<double>(0) == 1.) ||
(alpha.type() == CV_32F && alpha.at<float>(0) == 1.f));
CV_Assert(sv.type() == CV_32F);
hog_detector.clear();
hog_detector.resize(sv.cols + 1);
memcpy(&hog_detector[0], sv.ptr(), sv.cols * sizeof(hog_detector[0])); //memcpy指的是c和c++使用的内存拷贝函数,memcpy函数的功能是从源src所指的内存地址的起始位置开始拷贝n个字节到目标dest所指的内存地址的起始位置中。
hog_detector[sv.cols] = (float)-rho;
}
/*
* Convert training/testing set to be used by OpenCV Machine Learning algorithms.
* TrainData is a matrix of size (#samples x max(#cols,#rows) per samples), in 32FC1.
* Transposition of samples are made if needed.
*/
void convert_to_ml(const vector< Mat > & train_samples, Mat& trainData)
{
//--Convert data
const int rows = (int)train_samples.size(); //行数等于训练样本个数
const int cols = (int)std::max(train_samples[0].cols, train_samples[0].rows); //列数取样本图片中宽度与高度中较大的那一个
Mat tmp(1, cols, CV_32FC1); //< used for transposition if needed
trainData = Mat(rows, cols, CV_32FC1);
for (size_t i = 0; i < train_samples.size(); ++i)
{
CV_Assert(train_samples[i].cols == 1 || train_samples[i].rows == 1);
if (train_samples[i].cols == 1)
{
transpose(train_samples[i], tmp);
tmp.copyTo(trainData.row((int)i));
}
else if (train_samples[i].rows == 1)
{
train_samples[i].copyTo(trainData.row((int)i));
}
}
}
void load_images(const String &namefile,const String & dirname, vector< Mat > & img_lst, bool showImages = false)
{ //载入目录下的图片样本
/*vector< String > files;
glob(dirname, files); //返回一个包含有匹配文件/目录的数组。出错则返回false
for (size_t i = 0; i < files.size(); ++i)
{
Mat img = imread(files[i]); // load the image
if (img.empty()) // invalid image, skip it.
{
cout << files[i] << " is invalid!" << endl;
continue;
}
if (showImages)
{
imshow("image", img);
waitKey(1);
}
img_lst.push_back(img);//将Img压入img_lst
}*/
string ImgName;
ifstream fin(namefile);//打开原始负样本图片文件列表
//一行一行读取文件列表
while (getline(fin, ImgName))
{
ImgName = dirname + "\\" + ImgName;
Mat src = imread(ImgName);//读取图片
img_lst.push_back(src);//将Img压入img_lst
}
}
void sample_neg(const vector< Mat > & full_neg_lst, vector< Mat > & neg_lst, const Size & size)
{ //该函数对每一个负样本采样出一个随机的64*128尺寸的样本,由于之前已经采样过了,所以main函数中没有使用该函数
Rect box;
box.width = size.width; //等于检测器宽度
box.height = size.height; //等于检测器高度
const int size_x = box.width;
const int size_y = box.height;
srand((unsigned int)time(NULL)); //生成随机数种子
for (size_t i = 0; i < full_neg_lst.size(); i++)
{ //对每个负样本进行裁剪,随机指定x,y,裁剪一个尺寸为检测器大小的负样本
box.x = rand() % (full_neg_lst[i].cols - size_x);
box.y = rand() % (full_neg_lst[i].rows - size_y);
Mat roi = full_neg_lst[i](box);
neg_lst.push_back(roi.clone());
}
}
void computeHOGs(const Size wsize, const vector< Mat > & img_lst, vector< Mat > & gradient_lst)
{ //计算HOG特征
HOGDescriptor hog;
hog.winSize = wsize;
Rect r = Rect(0, 0, wsize.width, wsize.height);
r.x += (img_lst[0].cols - r.width) / 2; //正样本图片的尺寸减去检测器的尺寸,再除以2
r.y += (img_lst[0].rows - r.height) / 2;
Mat gray;
vector< float > descriptors;
for (size_t i = 0; i< img_lst.size(); i++)
{
cvtColor(img_lst[i](r), gray, COLOR_BGR2GRAY);
hog.compute(gray, descriptors, Size(8, 8), Size(0, 0)); //Size(8,8)为窗口移动步长,
gradient_lst.push_back(Mat(descriptors).clone());
}
}
int test_trained_detector(String obj_det_filename, String test_dir, String test_name_file,String videofilename)
{ //当videofilename为空,则只检测图片中的行人
cout << "Testing trained detector..." << endl;
HOGDescriptor hog;
hog.load(obj_det_filename);
//vector< String > files;
//glob(test_dir, files);
int delay = 0;
VideoCapture cap;
if (videofilename != "")
{
cap.open(videofilename);
}
obj_det_filename = "testing " + obj_det_filename;
namedWindow(obj_det_filename, WINDOW_NORMAL);
/*for (size_t i = 0;; i++)
{
Mat img;
if (cap.isOpened())
{
cap >> img;
delay = 1;
}
else if (i < files.size())
{
img = imread(files[i]);
}
if (img.empty())
{
return 0;
}
vector< Rect > detections;
vector< double > foundWeights;
hog.detectMultiScale(img, detections, foundWeights);
for (size_t j = 0; j < detections.size(); j++)
{
if (foundWeights[j] < 0.5) continue; //清楚权值较小的检测窗口
Scalar color = Scalar(0, foundWeights[j] * foundWeights[j] * 200, 0);
rectangle(img, detections[j], color, img.cols / 400 + 1);
}
imshow(obj_det_filename, img);
if (27 == waitKey(delay))
{
return 0;
}
}*/
Mat img;
string ImgName;
ifstream fin(test_name_file);//打开原始负样本图片文件列表
//一行一行读取文件列表
while (getline(fin, ImgName))
{
ImgName = test_dir + "\\" + ImgName;
img = imread(ImgName);//读取图片
vector< Rect > detections;
vector< double > foundWeights;
hog.detectMultiScale(img, detections, foundWeights);
for (size_t j = 0; j < detections.size(); j++)
{
if (foundWeights[j] < 0.5) continue; //清楚权值较小的检测窗口
Scalar color = Scalar(0, foundWeights[j] * foundWeights[j] * 200, 0);
rectangle(img, detections[j], color, img.cols / 400 + 1);
}
imshow(obj_det_filename, img);
if (27 == waitKey(delay))
{
return 0;
}
}
return 0;
}
int trainAndTest(int argc, char** argv, const char* keys)
{
CommandLineParser parser(argc, argv, keys); //命令行函数,读取keys中的字符, 其中key的格式为:名字 简称| 内容 |提示字符。
if (parser.has("help"))
{
parser.printMessage();
exit(0);
}
String pos_dir = parser.get< String >("pd"); //正样本目录
String pos_name_file = parser.get< String >("pdlst"); //正样本文件名列表
String neg_dir = parser.get< String >("nd"); //负样本目录
String neg_name_file = parser.get< String >("ndlst"); //负样本文件名列表
String test_dir = parser.get< String >("td"); //测试样本目录
String test_name_file = parser.get< String >("tdlst"); //测试样本文件列表
String obj_det_filename = parser.get< String >("fn"); //训练好的SVM检测器文件名
String videofilename = parser.get< String >("tv"); //测试视频
int detector_width = parser.get< int >("dw"); //检测器宽度
int detector_height = parser.get< int >("dh"); //检测器高度
bool test_detector = parser.get< bool >("t"); //测试训练好的检测器
bool train_twice = parser.get< bool >("d"); //训练两次
bool visualization = parser.get< bool >("v"); //训练过程可视化(建议false,不然爆炸)
if (test_detector) //若为true,测对测试集进行测试
{
test_trained_detector(obj_det_filename, test_dir, test_name_file, videofilename);
exit(0);
}
if (pos_dir.empty() || neg_dir.empty()) //检测非空
{
parser.printMessage();
cout << "Wrong number of parameters.\n\n"
<< "Example command line:\n" << argv[0] << " -pd=/INRIAPerson/96X160H96/Train/pos -nd=/INRIAPerson/neg -td=/INRIAPerson/Test/pos -fn=HOGpedestrian96x160.xml -d\n"
<< "\nExample command line for testing trained detector:\n" << argv[0] << " -t -dw=96 -dh=160 -fn=HOGpedestrian96x160.xml -td=/INRIAPerson/Test/pos";
exit(1);
}
vector< Mat > pos_lst, //正样本图片向量
full_neg_lst, //负样本图片向量
neg_lst, //采样后的负样本图片向量
gradient_lst; //HOG描述符存入到该梯度信息里面
vector< int > labels; //标签向量
clog << "Positive images are being loaded...";
load_images(pos_name_file,pos_dir, pos_lst, visualization); //加载图片 pos正样本的尺寸为96*160
if (pos_lst.size() > 0)
{
clog << "...[done]" << endl;
}
else
{
clog << "no image in " << pos_dir << endl;
return 1;
}
Size pos_image_size = pos_lst[0].size(); //令尺寸变量pos_image_size=正样本尺寸
cout << "pis = " << pos_image_size << endl;
//检测所有正样本是否具有相同尺寸
/*for (size_t i = 0; i < pos_lst.size(); ++i)
{
if (pos_lst[i].size() != pos_image_size)
{
cout << "All positive images should be same size!" << endl;
exit(1);
}
}*/
pos_image_size = pos_image_size / 8 * 8;
//令pos_image_size的尺寸为检测器的尺寸
if (detector_width && detector_height)
{
pos_image_size = Size(detector_width, detector_height);
}
labels.assign(pos_lst.size(), +1); //assign()为labels分配pos_lst.size()大小的容器,用+1填充 表示为正样本
const unsigned int old = (unsigned int)labels.size(); //旧标签大小
clog << "Negative images are being loaded...";
load_images(neg_name_file,neg_dir, neg_lst, false); //加载负样本图片
//sample_neg(full_neg_lst, neg_lst, pos_image_size);
clog << "...[done]" << endl;
labels.insert(labels.end(), neg_lst.size(), -1); //在labels向量的尾部添加neg_lst.size()大小的容器,用-1填充 表示为负样本
CV_Assert(old < labels.size()); //CV_Assert()作用:CV_Assert()若括号中的表达式值为false,则返回一个错误信息。
clog << "Histogram of Gradients are being calculated for positive images...";
computeHOGs(pos_image_size, pos_lst, gradient_lst); //计算正样本图片的HOG特征
clog << "...[done]" << endl;
clog << "Histogram of Gradients are being calculated for negative images...";
computeHOGs(pos_image_size, neg_lst, gradient_lst); //计算负样本图片的HOG特征
clog << "...[done]" << endl;
Mat train_data;
convert_to_ml(gradient_lst, train_data); //转化为ml所需的训练数据形式
clog << "Training SVM...";
Ptr< SVM > svm = SVM::create();
/* Default values to train SVM */
svm->setCoef0(0.0);
svm->setDegree(3);
svm->setTermCriteria(TermCriteria(CV_TERMCRIT_ITER + CV_TERMCRIT_EPS, 1000, 1e-3));
svm->setGamma(0);
svm->setKernel(SVM::LINEAR); //采用线性核函,其他的sigmoid 和RBF 可自行设置,其值由0-5。
svm->setNu(0.5);
svm->setP(0.1); // for EPSILON_SVR, epsilon in loss function?
svm->setC(0.01); // From paper, soft classifier
svm->setType(SVM::EPS_SVR); // C_SVC; // EPSILON_SVR; // may be also NU_SVR; // do regression task
svm->train(train_data, ROW_SAMPLE, Mat(labels));
clog << "...[done]" << endl;
//训练两次
if (train_twice)
{
clog << "Testing trained detector on negative images. This may take a few minutes...";
HOGDescriptor my_hog;
my_hog.winSize = pos_image_size;
// Set the trained svm to my_hog
vector< float > hog_detector;
get_svm_detector(svm, hog_detector);
my_hog.setSVMDetector(hog_detector);
vector< Rect > detections;
vector< double > foundWeights;
for (size_t i = 0; i < full_neg_lst.size(); i++)
{
my_hog.detectMultiScale(full_neg_lst[i], detections, foundWeights);
for (size_t j = 0; j < detections.size(); j++)
{
Mat detection = full_neg_lst[i](detections[j]).clone();
resize(detection, detection, pos_image_size);
neg_lst.push_back(detection);
}
if (visualization)
{
for (size_t j = 0; j < detections.size(); j++)
{
rectangle(full_neg_lst[i], detections[j], Scalar(0, 255, 0), 2);
}
imshow("testing trained detector on negative images", full_neg_lst[i]);
waitKey(5);
}
}
clog << "...[done]" << endl;
labels.clear();
labels.assign(pos_lst.size(), +1);
labels.insert(labels.end(), neg_lst.size(), -1);
gradient_lst.clear();
clog << "Histogram of Gradients are being calculated for positive images...";
computeHOGs(pos_image_size, pos_lst, gradient_lst);
clog << "...[done]" << endl;
clog << "Histogram of Gradients are being calculated for negative images...";
computeHOGs(pos_image_size, neg_lst, gradient_lst);
clog << "...[done]" << endl;
clog << "Training SVM again...";
convert_to_ml(gradient_lst, train_data);
svm->train(train_data, ROW_SAMPLE, Mat(labels));
clog << "...[done]" << endl;
}
//-------------------------------------------------------------------
vector< float > hog_detector; //定义hog检测器
get_svm_detector(svm, hog_detector); //得到训练好的检测器
HOGDescriptor hog;
hog.winSize = pos_image_size; //窗口大小
hog.setSVMDetector(hog_detector);
hog.save(obj_det_filename); //保存分类器
test_trained_detector(obj_det_filename, test_dir, test_name_file, videofilename); //检测训练集
return 0;
}
~_Pedestrain();
};3.主类#include "Tools.h"
#include "_Pedestrain.h"
using namespace std;
using namespace cv;
using namespace cv::ml;
//vedio_dir | J:\\Download\\SEQ\\set01\\V003.seq
const char* keys =
{
"{help h| | show help message}"
"{pd | E:\\INRIAPerson\\96X160H96\\Train\\pos | path of directory contains possitive images}"
"{pdlst | E:\\INRIAPerson\\96X160H96\\Train\\pos.lst | possitive images name }"
"{nd | E:\\INRIAPerson\\negphoto | path of directory contains negative images}"
"{ndlst | E:\\INRIAPerson\\negphoto.lst | negative images name }"
"{td | E:\\INRIAPerson\\Test\\pos | path of directory contains test images}"
"{tdlst | E:\\INRIAPerson\\Test\\pos\\pos.lst | test images name }"
"{tv | | test video file name}"
"{dw | 64 | width of the detector}"
"{dh | 128 | height of the detector}"
"{d |true| train twice}"
"{t |false| test a trained detector}"
"{v |false| visualize training steps}"
"{fn |E:\\Pedestrain.xml| file name of trained SVM}"
};
string obj_det_filename = "E:\\Pedestrain.xml";
string test_dir = "E:\\INRIAPerson\\Test\\pos";
string vediofilename = "";
int main(int argc, char** argv)
{
//数据预处理
Tools tool;
tool.ImgCut();
cout << tool.CropImageCount << endl;
//训练并测试数据
_Pedestrain pt;
pt.trainAndTest(argc, argv, keys);
//测试数据
//pt.test_trained_detector(obj_det_filename, test_dir, vediofilename);
return 0;
}5.训练训练结果
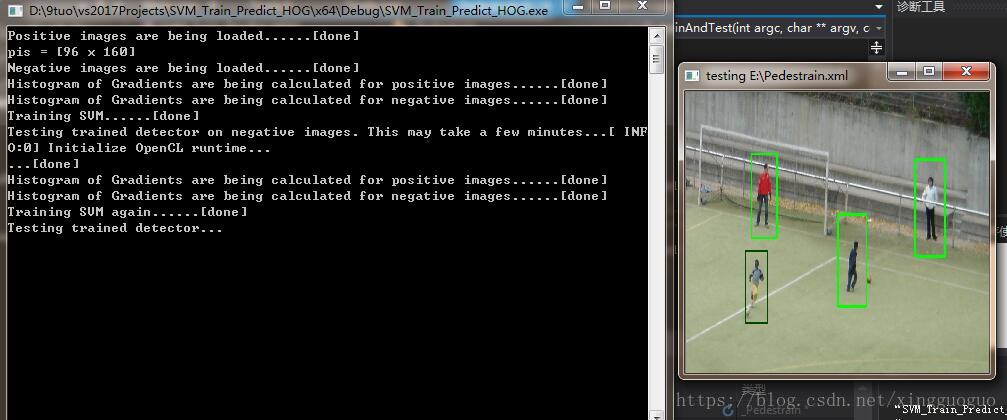
6.注意事项
1.训练集图片最好采用jpg格式,png格式会报错,需要使用png格式可以自行引入zlib,libpng库,或者是用格式工厂把png转换成jpg.
2.代码中的图片路径自己对应
3.项目要配置opencv库
参考文章:https://blog.csdn.net/qq_37753409/article/details/79047063
INRIAPerson训练集下载:ftp://ftp.inrialpes.fr/pub/lear/douze/data/INRIAPerson.tar