概念:泛型编程是一种编程方式,它利用“参数化类型”将类型抽象化,从而实现更为灵活的服用,然后使用这些变量记录不同类型的数据,这样可以重复利用泛型来存储不同类型的数据。
泛型用于处理算法,数据结构的一种编程方法。泛型的目标采用广泛适用和可交互性的形式来表示算法和数据结构,以使他们能够直接用于软件构造。泛型类、结构、接口、委托和方法可以根据他们存储和操作的数据类型来进行参数化。泛型能在编译时提供强大的类型检查,减少数据类型之间的显示转换、装箱操作和运行时的类型检查等。泛型类和泛型方法同时具备可重用性、类型安全和效率高等特性。这是非泛型类和非泛型方法无法具备的。
语法格式如下:
类修饰符 class 类名<类型参数T>
{
类体
}
泛型类的声明比普通类多一个类型参数T,类型参数T乐意看作是一个占位符,他不是一种类型,它仅仅代表了某种可能的类型。在定义泛型类,T出现的位置可以在使用时,用任何类型来代替。类型参数T的命名规则如下:
- 使用描述名称命名泛型类型参数,除非单个字母名称完全可以让人了解它表示的含义,而面熟性名称不会有更多的意义。
- 将T作为面熟性类型参数名的前缀。
例:使用泛型存储不同类型的数据列表

namespace ExtensiveList
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
class Types<T>
{
public T Num; //声明编号字段
public T Name; //声明姓名字段
public T Sex; //声明性别字段
public T Age; //声明年龄字段
public T Birthday; //声明生日字段
public T Salary; //声明薪水字段
}
private void button1_Click(object sender, EventArgs e)
{
Types<object> Exte = new Types<object>();//实例化泛型类对象
//为泛型类中声明的字段进行赋值,存储不同类型的值
Exte.Num = 1;
Exte.Name = "王老师";
Exte.Sex = "男";
Exte.Age = 25;
Exte.Birthday = Convert.ToDateTime("1986-06-08");
Exte.Salary = 1500.45F;
//将泛型类中各字段的值显示在文本框中
textBox1.Text = Exte.Num.ToString();
textBox2.Text = Exte.Name.ToString();
textBox3.Text = Exte.Sex.ToString();
textBox4.Text = Exte.Age.ToString();
textBox5.Text = Exte.Birthday.ToString();
textBox6.Text = Exte.Salary.ToString();
}
}
}
例2:泛型的继承:泛型继承类与普通类是类似的,只是在继承的时候多个T,格式如下:
class DerivedClass<参数类型T>:BaseClass<参数类型T>
举例: class BStuInfo<T>
{
public T ID; //声明学生编号字段
public T Name; //声明姓名字段
public T Sex; //声明性别字段
public T Age; //声明年龄字段
public T Birthday; //声明生日字段
public T Grade; //声明班级字段
}
class HStuInfo<T> : BStuInfo<T>//继承自BStuInfo泛型类
{
public T Chinese; //声明语文成绩字段
public T Math; //声明数学成绩字段
public T English; //声明英语成绩字段
}
泛型方法是在声明中包括了类型参数T的方法。泛型方法可以在类、结构或接口中声明,这些类、结构或接口本身可以是泛型或非泛型。如果在泛型类型声明中声明泛型方法,则方法可以同时引用该方法的类型参数T和包含该方法声明的类型参数T。泛型方法的语法如下:
[修饰符] [返回值类型] [方法名] <参数类型T>()
{
方法体
}
例:通过泛型查找不同的值
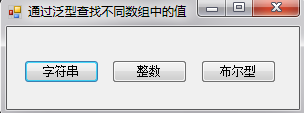
namespace ArrayInfo
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
public class Finder
{
// 定义一个泛型方法,用来查找指定值在数组中的索引
public static int Find<T>(T[] items, T item)
{
for (int i = 0; i < items.Length; i++)//遍历泛型数组
{
if (items[i].Equals(item))//判断是否找到了指定值
{
return i;//返回指定值在数组中的索引
}
}
return -1;//如果没有找到,返回-1
}
}
private void button1_Click(object sender, EventArgs e)
{
string[] Str = new string[] { "一", "二", "三", "四", "五", "六", "七", "八", "九" };//声明一个字符串类型的数组
MessageBox.Show(Finder.Find<string>(Str, "三").ToString());//查找字符串“三”在数组中的索引
}
private void button2_Click(object sender, EventArgs e)
{
int[] IntArray = new int[] { 1, 2, 3, 4, 5, 6, 7, 8, 9 };//声明一个整数类型的数组
MessageBox.Show(Finder.Find<int>(IntArray, 5).ToString());//查找数字5在数组中的索引
}
private void button3_Click(object sender, EventArgs e)
{
bool[] IntArray = new bool[] { true, false};//声明一个布尔类型的数组
MessageBox.Show(Finder.Find<bool>(IntArray, false).ToString());//查找false在数组中的索引
}
}
}
例2: 泛型作为返回值,例如Spring.Net中获取类的方法
public static T GetObject(string name)
{
try
{
IApplicationContext ctx = ContextRegistry.GetContext();
return ctx.GetObject(name) as T;
}
catch (Exception ex)
{
logger.Error(ex.Message);
return default(T);
}
}
}
泛型方法的重载:与普通的方法类似,只是声明时,添加了一个类型参数T
例:通过泛型实现子窗体的不同的操作。
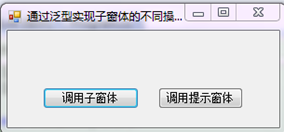
 转存失败重新上传取消 namespace FormDisOperate
转存失败重新上传取消 namespace FormDisOperate
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
public void FormOperate<T>()
{
Form2 Frm_2 = new Form2();//实例化Form2窗体对象
Frm_2.ShowDialog();//以对话框形式显示Form2窗体
}
public void FormOperate<T>(string strError)
{//实例化提示框中显示图标对象
MessageBoxIcon messIcon = MessageBoxIcon.Error; MessageBox.Show(strError, "提示", MessageBoxButtons.OK, messIcon);//显示错误提示框
}
private void button1_Click(object sender, EventArgs e)
{
FormOperate<object>();//调用FormOperate方法的第一种重载形式对窗体操作
}
private void button2_Click(object sender, EventArgs e)
{
FormOperate<object>("数据库连接失败。");//调用FormOperate方法的第二种重载形式对窗体操作
}
}
}
使用泛型集合:通常情况下,建议开发人员使用泛型集合,因为这样可以获得类型安全的直接优点,而不需要从基集合类型派生并实现类型特定的成员。此外,如果集合元素为值类型,泛型集合类型的性能通常优于对应的非泛型集合类型,并优于从非泛型基集合类型派生的类型,因为使用泛型时不必对元素进行封装。
常用的集合:ArrayList、Hashtable、Stack、Queue。需要添加命名空间using System.Collections
ArrayList使用举例:添加单个元素
static void Main(string[] args)
{
ArrayList list=new ArrayList();
list.Add(12);
list.Add("ASsa");
list.Add(false);
foreach(var i in list)
{
Console.WriteLine(i.ToString());
}
}
输出结果:
12
ASsa
False
添加数组:
static void Main(string[] args)
{
int[] arr = { 1, 2, 3 };//第一种添加数组的方法
ArrayList list=new ArrayList();
list.AddRange(arr);
int[] arr1 = { 4, 5, 6 };//第二种添加数组的方法
ArrayList list1 = new ArrayList(arr1);
}
ArrayList常用的一些方法:
static void Main(string[] args)
{
int[] arr = { 1, 2, 3 };
ArrayList list=new ArrayList();
list.AddRange(arr);
list.Clear();//清除所有数据
list.Contains(2);//判断是否包含这个数据,包含输出true,不包含输出false
int cap = list.Capacity;//得到目前最大容量
int num = list.Count;//得到实际元素的个数
int b = list.Count;//返回元素的下标,从左向右查
list.Insert(0, 12);//在下边为0处插入12,其后面的,后移一位,下标不能超过list的最大长度
list.Remove(2);//删除一个元素,存在则删除,不存在就不执行。
list.RemoveAt(0);//删除下标的元素,括号为下标
}
HashTable常用的方法:
static void Main(string[] args)
{
Hashtable table = new Hashtable();
table.Add("1", 10);
table.Add("2", 20);
table.Add("3", 30);//添加数据
object i = table["1"];//根据Key,获取对应的Value
table.Clear();//删除表
bool key = table.Contains("1");//是否包含某个键,若包含则返回true
bool key1 = table.ContainsKey("1");//是否包含某个键,若包含则返回true
bool val = table.ContainsValue(10);//是否存在10.存在返回true
int ct = table.Count;//返回元素的个数
ICollection ic = table.Keys;//获取所有的键值
foreach (object o in ic)
{
Console.WriteLine(0);//结果:1,2,3
}
ic = table.Values;
foreach (object o in ic)
{
Console.WriteLine(o);//结果:10、20、30
}
foreach (DictionaryEntry d in table)
{
Console.WriteLine("{0},{1}",d.Key,d.Value);
}
}
//结果:
//1,10
//2,20
//3,30
栈是一种先进后出的一种数据结构,类似口向上的井
栈举例:
Stack st = new Stack();
st.Push(1);
st.Push(2);//压栈
object o = st.Pop();//出栈,并把栈顶删除
object ob = st.Peek();//出栈,并不删除栈顶元素
队列是一种先进先出的数据结构
队列举例: Queue q = new Queue();
q.Enqueue(1);
q.Enqueue(2);//添加数据
object o = q.Dequeue();//出队,并把队顶元素删除
object ob = q.Peek();//出队,并不删除队顶元素
常用的泛型:
- List<数据类型>
格式:List<s数据类型> list=new List<数据类型>();取代了集合中的ArrayList
- Dictionary<数据类型,数据类型>
格式:Dictionary<数据类型,数据类型> dic=new Dictionary<数据类型,数据类型>();取代了集合中的HashTable
- Stack<数据类型>
格式Stack<数据类型> s=new Stack<数据类型>();取代了集合中Stack
- Queue<数据类型>
格式Queue <数据类型> s=new Queue <数据类型>();取代了集合中Queue
举例:从字典中同时取出,key和对应的value
Dictionary<int, string> dic = new Dictionary<int, string>();
dic.Add(1, "10");
dic.Add(2, "20");
string s = dic[1];//取出key为1的值。
Dictionary<int, string>.KeyCollection keys = dic.Keys;//获取所有的键值
foreach (int i in keys)//遍历Key
{
Console.WriteLine(i);
}
Dictionary<int, string>.ValueCollection vals = dic.Values;//获取所有的Value值
foreach (string t in vals)//遍历Value
{
Console.WriteLine(t);
}
foreach (KeyValuePair<int, string> k in dic)//遍历键值对
{
Console.WriteLine(k.Key+"....."+k.Value);
}
字典和List嵌套综合应用:字典中嵌套List,按字典的key进行分类放入List中。比如按照名字进行分类
private void BindGrid()
{
List<MemberInfo> memberList=_bll.getList();//获取数据放入列表
Dictionary<string,List<MemberInfo>> memberNameDic=new Dictionary<string,List<MemberInfo>>();//建立嵌套List
Foreach(Member memberInfo in memberList)
{
if(memberNameDic.ContainsKey(memberInfo.MemberName)==false)
{
memberNameDic.Add(memberInfo.MemberName , new List<MemberInfo>())
}
memberNameDic[memberInfo.MemberName].Add(memberInfo);//向字典中按姓名相同进行分类
}
Foreach( string key in memberNameDic.Keys)
{
GroupNameSame(key , memberNameDic[key]);
}
}
Private void GroupNameSame(string name,IList<MemberInfo> memberNameList)
{
Foreach(MemberInfo memberInfo in memberNameList)
{}//读取List
}
泛型排序列表,SortList<Tkey,TValue> 表示按照键进行的排序的键/值对的集合,键/值对是KeyValuePair<TKey,TValue>类型。泛型排序列表具有以下3个特点:
- 、将添加到泛型排序的表的元素自动按照键进行排序。
- 、泛型排序列表中的键不能修改,不能为空,不能重复。
- 、泛型排序列表的值乐意修改,可以为空,可以重复。
public class UserInfo
{
public int UserCode { get; set; }
public string UserName { get; set; }
public string PassWord { get; set; }
public UserInfo(int userCode, string userName, string passWord)
{
UserCode = userCode;
UserName = userName;
PassWord = passWord;
}
}
class Program
{
static void Main(string[] args)
{
SortedList<int, UserInfo> uses = new SortedList<int, UserInfo>();
uses.Add(2, new UserInfo(2, "User02", "02"));
uses.Add(3, new UserInfo(3, "User03", "03"));
uses.Add(1, new UserInfo(1, "User01", "01"));
foreach (var item in uses)
{
Console.WriteLine("{0},{1}",item.Key,item.Value.UserName);
}//按照key的顺序从小到大排序
}
}
输出结果:
1,User01
2,User02
3,User03
利用比较器来定义排序规则,将排序规则改为大到小顺序:
public class ListComparer : IComparer<int>
{
#region IComparer<int> 成员
public int Compare(int x, int y)
{
if (x > y)
{
return -1;
}
else
{
return 1;
}
}
#endregion
}
public class UserInfo
{
public int UserCode { get; set; }
public string UserName { get; set; }
public string PassWord { get; set; }
public UserInfo(int userCode, string userName, string passWord)
{
UserCode = userCode;
UserName = userName;
PassWord = passWord;
}
}
class Program
{
static void Main(string[] args)
{
SortedList<int, UserInfo> uses = new SortedList<int, UserInfo>(new ListComparer());
uses.Add(2, new UserInfo(2, "User02", "02"));
uses.Add(3, new UserInfo(3, "User03", "03"));
uses.Add(1, new UserInfo(1, "User01", "01"));
foreach (var item in uses)
{
Console.WriteLine("{0},{1}",item.Key,item.Value.UserName);
}
}
}
输出结果:
3,User03
2,User02
1,User01
泛型排序字典
SortedDictionary<string, string> sortDic = new SortedDictionary<string, string>();
sortDic.Add("qw", "1qwa");
sortDic.Add("as", "sdfsa");
foreach (var i in sortDic.Keys)
{
Console.WriteLine(i.ToString());
}//默认按照字典序排序、
输出结果:
as
qw
- IList和List的区别
首先IList 泛型接口是 ICollection 泛型接口的子代,并且是所有泛型列表的基接口。它仅仅是所有泛型类型的接口,并没有太多方法可以方便实用,如果仅仅是作为集合数据的承载体,确实,IList可以胜任。
其次, IList <> 是在 .net framework 2.0里面才支持的
1. 不过,更多的时候,我们要对集合数据进行处理,从中筛选数据或者排序。这个时候IList就不太好使了。因为他的效率要慢。后面会一一讲到。
2、IList <>是个接口,定义了一些操作方法这些方法要你自己去实现,List <>是泛型类,它已经实现了IList <>定义的那些方法
IList IList11 =new List ();
List List11 =new List ();
这两行代码,从操作上来看,实际上都是创建了一个List对象的实例,也就是说,他们的操作没有区别。只是用于保存这个操作的返回值变量类型不一样而已。
那么,我们可以这么理解,这两行代码的目的不一样。
List List11 =new List ();
是想创建一个List,而且需要使用到List的功能,进行相关操作。
而IList IList11 =new List ();
只是想创建一个基于接口IList的对象的实例,只是这个接口是由List实现的。所以它只是希望使用到IList接口规定的功能而已。
3.接口实现松耦合...有利于系统的维护与重构...优化系统流程...鼓励使用接口,这样可以实现功能和具体实现的分离.
这些说的都是有道理的,那么接刚才第一点的话题说,为什么说用到数据处理,或者排序IList就不太好使了呢。这个也是要根据数据量来的。我做了如下测试
public class TestClass
{
public int Id
{ get; set; }
public string Name
{ get; set;}
}
static void Main(string[] args)
{
ListTest();
}
private static void ListTest()
{
Stopwatch timer = new Stopwatch();
timer.Start();
List<TestClass> list1 = new List<TestClass>();
for (int i = 0; i < 10000000; i++)
{
TestClass tc = new TestClass();
tc.Id = i;
tc.Name = "Test Data" + i;
list1.Add(tc);
}
int count = 0;
foreach (var tc in list1)
{
if (tc.Id >= 1 && tc.Id < 1000)
{
count++;
}
}
//list1.OrderBy(i => i.Id);
timer.Stop();
Console.Write("Count:" + count + ", List time:");
Console.WriteLine(timer.Elapsed.Ticks);
timer = new Stopwatch();
timer.Start();
IList<TestClass> list2 = new List<TestClass>();
for (int i = 0; i < 10000000; i++)
{
TestClass tc = new TestClass();
tc.Id = i;
tc.Name = "Test Data" + i;
list2.Add(tc);
}
int count2 = 0;
foreach (var tc in list2)
{
if (tc.Id >= 1 && tc.Id < 1000)
{
count2++;
}
}
//list2.OrderBy(i => i.Id);
timer.Stop();
Console.Write("Count:" + count2 + ", IList time:");
Console.WriteLine(timer.Elapsed.Ticks);
Console.Read();
}
当我们都去遍历IList和List的时候,注意我取的数据是1~1000之间,经过反复测试,IList的效率确实是要低一些。那就更不用说数据量更大的时候,请看输出框:

但是,当我取的数据是1~500的时候, IList似乎效率还是要慢一些。
另外,可能有的朋友会说,你把前面的for循环放在外面比较呢,这个我也做过测试,结果还是一样,List效率要好于IList
同样的方法,我测试了,IList和List的OrderBy的效率,List均有胜面,高效一筹。所以,什么时候用IList和List自己去斟酌,当你用到设计的时候当然是IList合理一些。用做数据容器遍历或者排序,还是选择List好一点。
数组、ArrayList、List区别:
数组
数组在C#中最早出现的。在内存中是连续存储的,所以它的索引速度非常快,而且赋值与修改元素也很简单。
但是数组存在一些不足的地方。在数组的两个数据间插入数据是很麻烦的,而且在声明数组的时候必须指定数组的长度,数组的长度过长,会造成内存浪费,过段会造成数据溢出的错误。如果在声明数组时我们不清楚数组的长度,就会变得很麻烦。
针对数组的这些缺点,C#中最先提供了ArrayList对象来克服这些缺点。
ArrayList
ArrayList是命名空间System.Collections下的一部分,在使用该类时必须进行引用,同时继承了IList接口,提供了数据存储和检索。ArrayList对象的大小是按照其中存储的数据来动态扩充与收缩的。所以,在声明ArrayList对象时并不需要指定它的长度。
ArrayList中插入不同类型的数据是允许的。因为ArrayList会把所有插入其中的数据当作为object类型来处理,在我们使用ArrayList处理数据时,很可能会报类型不匹配的错误,也就是ArrayList不是类型安全的。在存储或检索值类型时通常发生装箱和取消装箱操作,带来很大的性能耗损。
泛型List
因为ArrayList存在不安全类型与装箱拆箱的缺点,所以出现了泛型的概念。List类是ArrayList类的泛型等效类,它的大部分用法都与ArrayList相似,因为List类也继承了IList接口。最关键的区别在于,在声明List集合时,我们同时需要为其声明List集合内数据的对象类型。
比如:
List<string> list = new List<string>();
list.Add(“abc”); //新增数据
list[0] = “def”; //修改数据
list.RemoveAt(0); //移除数据
上例中,如果我们往List集合中插入int数组123,IDE就会报错,且不能通过编译。这样就避免了前面讲的类型安全问题与装箱拆箱的性能问题了。
总结:
数组的容量是固定的,您只能一次获取或设置一个元素的值,而ArrayList或List<T>的容量可根据需要自动扩充、修改、删除或插入数据。
数组可以具有多个维度,而 ArrayList或 List< T> 始终只具有一个维度。但是,您可以轻松创建数组列表或列表的列表。特定类型(Object 除外)的数组 的性能优于 ArrayList的性能。 这是因为 ArrayList的元素属于 Object 类型;所以在存储或检索值类型时通常发生装箱和取消装箱操作。不过,在不需要重新分配时(即最初的容量十分接近列表的最大容量),List< T> 的性能与同类型的数组十分相近。
在决定使用 List<T> 还是使用ArrayList 类(两者具有类似的功能)时,记住List<T> 类在大多数情况下执行得更好并且是类型安全的。如果对List< T> 类的类型T 使用引用类型,则两个类的行为是完全相同的。但是,如果对类型T使用值类型,则需要考虑实现和装箱问题。
C# 集合性能 总结 标记说明:
- O(1) 表示无论集合中有多少项,这个操作需要的时间都不变,例如,ArraryLIst的Add(方法就O(1),无论集合中有多少元素,在列表尾部添加一个新的元素的时间都是相同的.
- O(n)表示对于集合中的每个元素,需要增加的时间量都是相同的,如果需要重新给
- O(log n)表示操作需要的时间随着集合中元素的增加和增加,但每个元素增加的时间不是线性的.而是呈对数曲线,在集合中插入操作时,SortedDictionary<Tkey,Tvalue>就是O(log n),而SortedList<Tkey,Tvalue> 就是O(n),这里SortedDictionary<Tkey,Tvalue>要快的多.因为它在树形结构中插入元素的效率比列表高的多.下表显示各种集合的操作时间:
| 集合 |
Add |
Insert |
Remove |
Item |
Sort |
Find |
| List<T> |
如果集合必须重置大小就是O(1)或O(n) |
O(n) |
O(n) |
O(1) |
O(n log n)最坏情况O(n^2) |
O(n) |
| Stack<T>(栈) |
Push(),如果栈必须重置大小,就是O(1)或O(n) |
no |
Pop(),O(1) |
no |
no |
no |
| Queue<T>(列队) |
Enqueue(),如果栈必须重置大小,就是O(1)或O(n) |
no |
Dequeu(),O(1) |
no |
no |
no |
| HastSet<T>(无序列表) |
如果栈必须重置大小,就是O(1)或O(n) |
Add() O(1)或O(n) |
O(1) |
no |
no |
no |
| LinkedList<T>(链表) |
AddLast(),O(1) |
AddAfter(),O(1) |
O(1) |
no |
no |
O(n) |
| Dictionary<Tkey,TValue> |
O(1) 或 O(n) |
no |
O(1) |
O(1) |
no |
no |
| SortedDictionary<Tkey,Tvalue> |
O(log n) |
no |
O(log n) |
O(log n) |
no |
no |
| SortedList<Tkey,Tvalue> |
无序数据为O(n),如果必选重置大小,到列表的尾部就是 O(log n) |
no |
O(n) |
读写是O(log n),如果键在列表中,就是O(log n),如果键不在列表中就是O(n). |
no |
no |
注:如果单元格中有多个大O值,表示集合需要重置大小,该操作需要一定的时间
如果单元格内容是no,就表示不支持这种操作.
小结:
数组的大小是固定的,但可以使用列表作为动态增长集合,列队以先进先出的方式访问元素,栈以后进先出的方式访问元素,
链表可以快速的插入和删除元素,但搜索比较慢,通过键和值可以使用字典,它的搜索和插入操作比较快,集(Hashset<T>) 是用于无序的唯一项.
可观察集合
如果需要集合中的元素合适删除或添加的信息,就可以使用ObserVableCollection<T>类。这样UI就可以知集合的变化。这个类的名命空间SystemCollections.ObjectModel.
ObserableCollection<T>类派生自Collection<T>积累。该基类可以用于创建自定义集合,并在内部使用List<T>类。重写了基类中的虚方法SetITem()和RemoveItem(),以出发CollectionChanged事件。这个类的用户可以使用InotifyCollectionChanged接口注册事件。
using System.Collections.ObjectModel;
namespace Wrox.ProCSharp.Collections
{
class Program
{
static void Main()
{
var data = new ObservableCollection<string>();
data.CollectionChanged += Data_CollectionChanged;
data.Add("One");
data.Add("Two");
data.Insert(1, "Three");
data.Remove("One");
}
static void Data_CollectionChanged(object sender, System.Collections.Specialized.NotifyCollectionChangedEventArgs e)
{
Console.WriteLine("action: {0}", e.Action.ToString());
if (e.OldItems != null)
{
Console.WriteLine("starting index for old item(s): {0}", e.OldStartingIndex);
Console.WriteLine("old item(s):");
foreach (var item in e.OldItems)
{
Console.WriteLine(item);
}
}
if (e.NewItems != null)
{
Console.WriteLine("starting index for new item(s): {0}", e.NewStartingIndex);
Console.WriteLine("new item(s): ");
foreach (var item in e.NewItems)
{
Console.WriteLine(item);
}
}
Console.WriteLine();
}
}
}
输出结果:
action: Add
starting index for new item(s): 0
new item(s):
One
action: Add
starting index for new item(s): 1
new item(s):
Two
action: Add
starting index for new item(s): 1
new item(s):
Three
action: Remove
starting index for old item(s): 0
old item(s):
One
