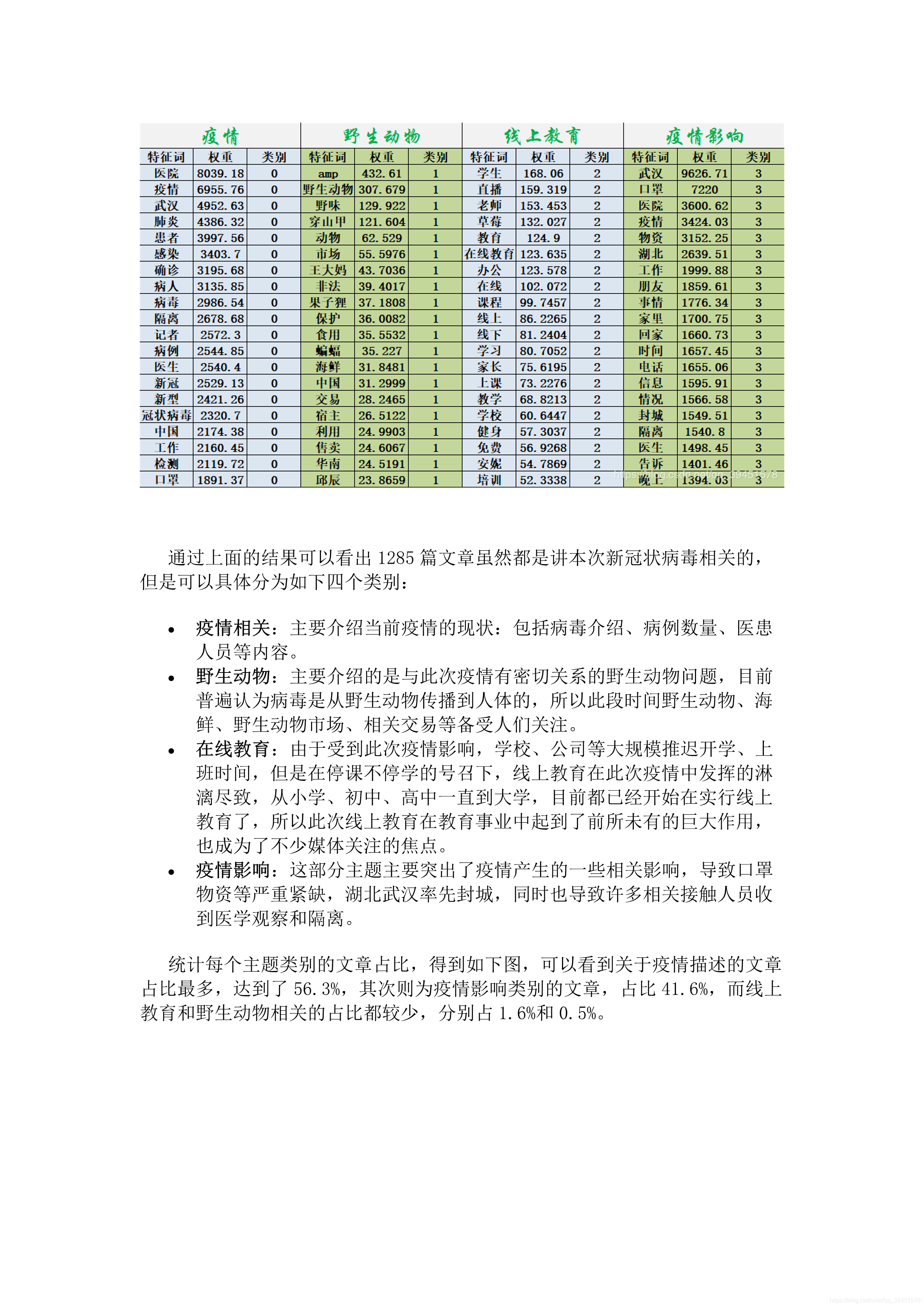
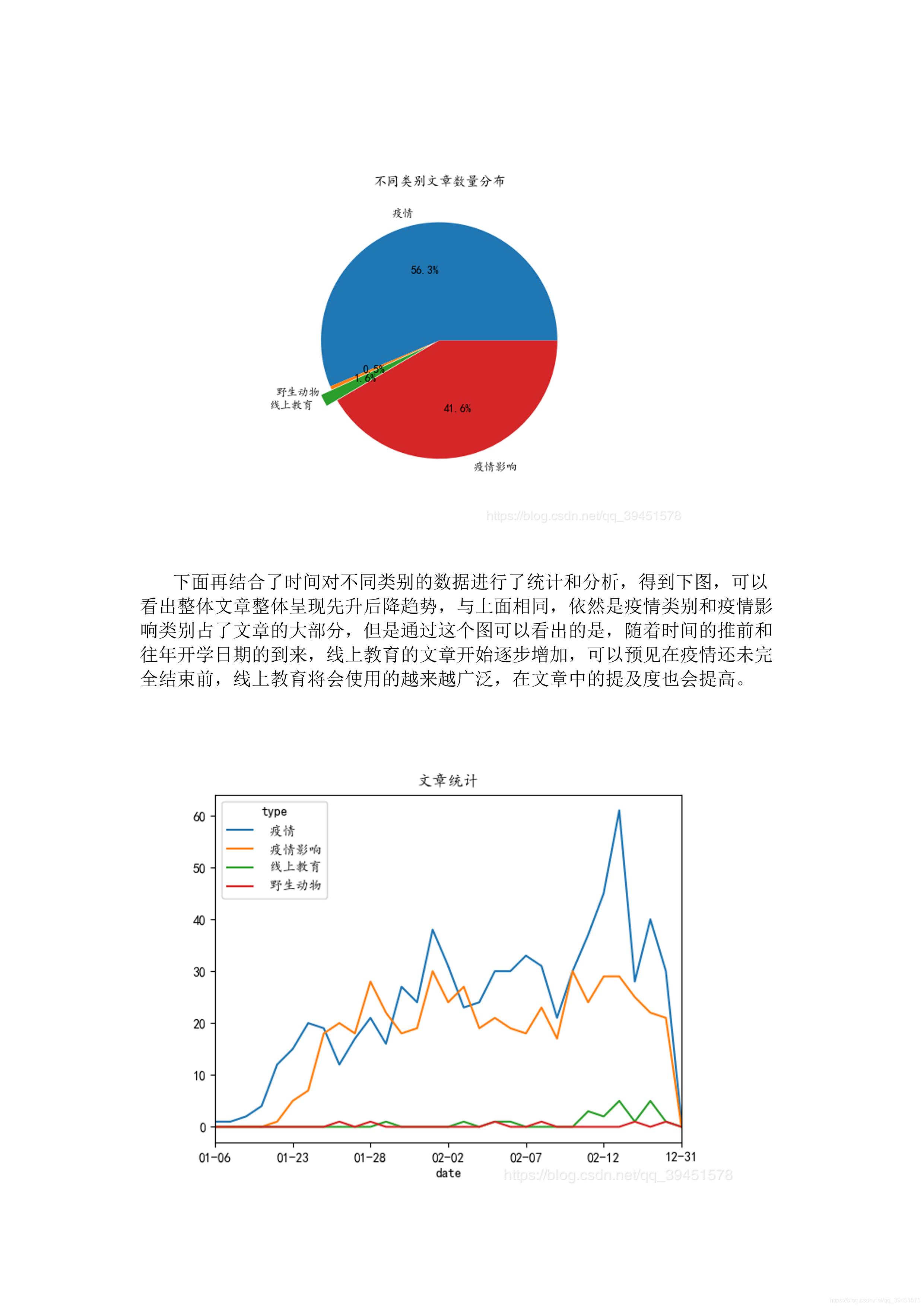
由于词汇敏感之类的原因,每次发布都审核失败,于是转为图片上传了!相关代码在文末附录中。








附录:
t1.py:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/2/12 13:02
# @Author : ystraw
# @Site :
# @File : t1.py
# @Software: PyCharm Community Edition
# @function: 从github指定链接中进行数据获取
# 获取链接后,根据链接的不同来源,进行不同网页的抓取文章内容
import requests
import time
import datetime
from bs4 import BeautifulSoup
from openpyxl import Workbook
import random
from lxml import etree
from openpyxl import load_workbook
import getIpPool
proxies = getIpPool.getproxies()
MAX_num = 15 # Ip取值范围
openFlag = 1 # 0关闭Ip代理,1开启Ip代理
outTime = 10 # 超时时间
# 写入文件:, 新建不追加:
def writeFile(filename, file):
with open(filename, 'w', encoding='utf-8') as f:
f.write(file)
print(filename, '已写入!')
f.close()
# 写入文件:, 新建追加:
def writeFile_add(filename, file):
with open(filename, 'a', encoding='utf-8') as f:
f.write(file)
print(filename, '已写入!')
f.close()
# 读入文件
def readFile(filename):
with open(filename, 'r', encoding='utf-8') as f:
str = f.read()
print(filename, '已读入!')
f.close()
return str
# 写入Excel
def write_excel_xls(path, sheet_name, value, bHead):
# 获取需要写入数据的行数
index = len(value)
# 获取需要写入数据的行数
index = len(value)
wb = Workbook()
# 激活 worksheet
ws = wb.active
# 第一行输入
ws.append(bHead)
# .cell(row=x, column=2, value=z.project)
for i in range(2, index+2):
for j in range(1, len(value[i-2]) + 1):
# ws.append(value[i])
ws.cell(row=i, column=j, value=value[i-2][j-1])
# 保存
wb.save(path)
print(path + '表格写入数据成功!')
# 采集github的文章链接
def getUrl(path, url):
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
]
agent = random.choice(ua_list)
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://piaofang.maoyan.com/dashboard?movieId=1211270&date=2011-01-02",
"User-Agent": agent,
}
# url = 'https://www.amazon.com/b/ref=AE_HP_leftnav_automotive?_encoding=UTF8&ie=UTF8&node=2562090011&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_t=101&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_i=17938598011'
print('请求地址:', url)
html = requests.get(url, headers=headers, verify=False).text
# writeFile('data/top250.html', html)
# xpath:提取信息(标题)
text =etree.HTML(html)
trs = text.xpath('//div[@class="Box-body"]//tbody/tr/td[2]/text()')
# bs4: 提取信息:
bs = BeautifulSoup(html, 'lxml')
div = bs.findAll('div', attrs={'class': 'Box-body'})[0]
# print(div)
trList = div.findAll('tr')
# print(len(trList))
cnt = 0
# 全部数据
alldata = []
for tr in trList:
tds = tr.findAll('td')
if tds != []:
# 提取:日期,标题
tempList = [tds[0].string, trs[cnt]]
# 提取:【原始URL,截图,翻译,Archive】的链接
for i in range(2, 6):
astring = ''
aList = tds[i].findAll('a')
for a in aList:
astring += a['href'] + ','
tempList.append(astring.strip(','))
print(tempList)
alldata.append(tempList)
cnt += 1
tableHead = ['日期', '标题', '原始URL', '截图', '翻译', 'Archive']
write_excel_xls(path, 'link', alldata, tableHead)
# 提取微信文章
def getdetailContent_1(url):
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
]
agent = random.choice(ua_list)
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://piaofang.maoyan.com/dashboard?movieId=1211270&date=2011-01-02",
"User-Agent": agent,
}
# url = 'https://www.amazon.com/b/ref=AE_HP_leftnav_automotive?_encoding=UTF8&ie=UTF8&node=2562090011&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_t=101&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_i=17938598011'
print('请求地址:', url)
# html = requests.get(url, timeout=10, headers=headers, verify=False).text
global proxies
global openFlag
ip = proxies[random.randint(0, MAX_num if len(proxies) > MAX_num else len(proxies)-1)]
if openFlag == 1:
html = requests.get(url, timeout=outTime, headers=headers, proxies={ip[0]: ip[1]}, verify=False).text
# print(ip)
else:
html = requests.get(url, timeout=outTime, headers = headers, verify=False).text
# print(html)
text = etree.HTML(html)
context = text.xpath('string(//div[@class="rich_media_content "])').replace(' ', '').replace('\n', '')
# print(context.replace(' ', '').replace('\n', ''))
return context
# 提取财经网
def getdetailContent_2(url):
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
]
agent = random.choice(ua_list)
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://piaofang.maoyan.com/dashboard?movieId=1211270&date=2011-01-02",
"User-Agent": agent,
}
# url = 'https://www.amazon.com/b/ref=AE_HP_leftnav_automotive?_encoding=UTF8&ie=UTF8&node=2562090011&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_t=101&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_i=17938598011'
print('请求地址:', url)
# html = requests.get(url, timeout=10, headers=headers, verify=False).text
global proxies
global openFlag
ip = proxies[random.randint(0, MAX_num if len(proxies) > MAX_num else len(proxies)-1)]
if openFlag == 1:
html = requests.get(url, timeout=outTime, headers=headers, proxies={ip[0]: ip[1]}, verify=False).text
# print(ip)
else:
html = requests.get(url, timeout=outTime, headers = headers, verify=False).text
# print(html)
text = etree.HTML(html)
context = text.xpath('string(//div[@id="Main_Content_Val"])')
# print(context.replace(' ', '').replace('\n', ''))
# print('===============')
return context
# 经济观察网
def getdetailContent_3(url):
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
]
agent = random.choice(ua_list)
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://piaofang.maoyan.com/dashboard?movieId=1211270&date=2011-01-02",
"User-Agent": agent,
}
# url = 'https://www.amazon.com/b/ref=AE_HP_leftnav_automotive?_encoding=UTF8&ie=UTF8&node=2562090011&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_t=101&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_i=17938598011'
print('请求地址:', url)
# 解决乱码
# html = requests.get(url, timeout=10, headers=headers, verify=False).text.encode('iso-8859-1')
global proxies
global openFlag
ip = proxies[random.randint(0, MAX_num if len(proxies) > MAX_num else len(proxies)-1)]
if openFlag == 1:
html = requests.get(url, timeout=outTime, headers=headers, proxies={ip[0]: ip[1]}, verify=False).text.encode('iso-8859-1')
# print(ip)
else:
html = requests.get(url, timeout=outTime, headers = headers, verify=False).text.encode('iso-8859-1')
# print(html)
text = etree.HTML(html)
context = text.xpath('string(//div[@class="xx_boxsing"])')
# print(context.replace(' ', '').replace('\n', ''))
# print('===============')
return context
# 方方博客
def getdetailContent_4(url):
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
]
agent = random.choice(ua_list)
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://piaofang.maoyan.com/dashboard?movieId=1211270&date=2011-01-02",
"User-Agent": agent,
}
# url = 'https://www.amazon.com/b/ref=AE_HP_leftnav_automotive?_encoding=UTF8&ie=UTF8&node=2562090011&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_t=101&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_i=17938598011'
print('请求地址:', url)
# 解决乱码
# html = requests.get(url, timeout=10, headers=headers, verify=False).text
global proxies
global openFlag
ip = proxies[random.randint(0, MAX_num if len(proxies) > MAX_num else len(proxies)-1)]
if openFlag == 1:
html = requests.get(url, timeout=outTime, headers=headers, proxies={ip[0]: ip[1]}, verify=False).text
# print(ip)
else:
html = requests.get(url, timeout=outTime, headers = headers, verify=False).text
# print(html)
text = etree.HTML(html)
context = text.xpath('string(//div[@class="blog_content"])')
# print(context.replace(' ', '').replace('\n', ''))
# print('===============')
return context
# 中国经营网专题
def getdetailContent_5(url):
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
]
agent = random.choice(ua_list)
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://piaofang.maoyan.com/dashboard?movieId=1211270&date=2011-01-02",
"User-Agent": agent,
}
# url = 'https://www.amazon.com/b/ref=AE_HP_leftnav_automotive?_encoding=UTF8&ie=UTF8&node=2562090011&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_t=101&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_i=17938598011'
print('请求地址:', url)
# 解决乱码
# html = requests.get(url, timeout=10, headers=headers, verify=False).text
global proxies
global openFlag
ip = proxies[random.randint(0, MAX_num if len(proxies) > MAX_num else len(proxies)-1)]
if openFlag == 1:
html = requests.get(url, timeout=outTime, headers=headers, proxies={ip[0]: ip[1]}, verify=False).text
# print(ip)
else:
html = requests.get(url, timeout=outTime, headers = headers, verify=False).text
# print(html)
text = etree.HTML(html)
context = text.xpath('string(//div[@class="contentleft auto"])')
# print(context.replace(' ', '').replace('\n', ''))
# print('===============')
return context
# 界面网
def getdetailContent_6(url):
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
]
agent = random.choice(ua_list)
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://piaofang.maoyan.com/dashboard?movieId=1211270&date=2011-01-02",
"User-Agent": agent,
}
# url = 'https://www.amazon.com/b/ref=AE_HP_leftnav_automotive?_encoding=UTF8&ie=UTF8&node=2562090011&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_t=101&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_i=17938598011'
print('请求地址:', url)
# 解决乱码
# html = requests.get(url, timeout=10, headers=headers, verify=False).text
global proxies
global openFlag
ip = proxies[random.randint(0, MAX_num if len(proxies) > MAX_num else len(proxies)-1)]
if openFlag == 1:
html = requests.get(url, timeout=outTime, headers=headers, proxies={ip[0]: ip[1]}, verify=False).text
# print(ip)
else:
html = requests.get(url, timeout=outTime, headers = headers, verify=False).text
# print(html)
text = etree.HTML(html)
context = text.xpath('string(//div[@class="article-content"])')
# print(context.replace(' ', '').replace('\n', ''))
# print('===============')
return context
# 从excel中获取
def getContent(path, savePath):
# 读取数据
wb = load_workbook(path)
sheet_names = wb.get_sheet_names()
table = wb.get_sheet_by_name(sheet_names[0]) # index为0为第一张表
nrows = table.max_row # 行
ncols = table.max_column # 列
print(nrows, ncols)
cnt = 0
alldata = []
for i in range(2, nrows+1):
templist = []
for j in range(1, ncols+1):
# print(table.cell(i, j).value)
templist.append(table.cell(i, j).value)
# 获取详情链接:
url = table.cell(i, 3).value.split(',')[0]
try:
if url[:24] == 'https://mp.weixin.qq.com':
# 微信公共号获取文章'
content = getdetailContent_1(url)
templist.append('微信公共号')
templist.append(content)
# print(content)
# pass
elif url[:24] == 'http://china.caixin.com/' or url[:22] == 'http://www.caixin.com/' or url[:25] == 'http://weekly.caixin.com/':
# 财新网获取文章
content = getdetailContent_2(url)
templist.append('财新网')
templist.append(content)
# print(content)
# pass
elif url[:22] == 'http://www.eeo.com.cn/':
# 经济观察网
# # print('经济观察网', table.cell(i, 3).value)
content = getdetailContent_3(url)
templist.append('经济观察网')
templist.append(content)
# print(content)
# pass
elif url[:32] == 'http://fangfang.blog.caixin.com/':
# 方方博客
content = getdetailContent_4(url)
templist.append('方方博客')
templist.append(content)
# print(content)
# pass
elif url[:21] == 'http://www.cb.com.cn/':
# # 中国经营网专题
content = getdetailContent_5(url)
templist.append('中国经营网')
templist.append(content)
# # print(content)
pass
elif url[:24] == 'https://www.jiemian.com/':
# 界面网
content = getdetailContent_6(url)
templist.append('界面网')
templist.append(content)
# print(content)
# pass
else:
# print('else', table.cell(i, 3).value, '===', table.cell(i, 2).value)
cnt += 1
# print(table.cell(i, 3).value, table.cell(i, 5).value)
alldata.append(templist)
except Exception as ex:
print('异常:', ex)
# if i >= 10:
# break
# time.sleep(random.randint(0, 2))
print('剔除的:', cnt)
tableHead = ['日期', '标题', '原始URL', '截图', '翻译', 'Archive','文章来源', '文章内容']
write_excel_xls(savePath, 'link', alldata, tableHead)
if __name__ == '__main__':
'''
第一步:获取链接
'''
# 数据地址
# url = 'https://github.com/2019ncovmemory/nCovMemory#%E7%AC%AC%E4%B8%80%E8%B4%A2%E7%BB%8Fyimagazine'
# # 保存文件路径:
# path = './data/all_text_2.xlsx'
# getUrl(path, url)
'''
第二步:通过链接提取文章内容
'''
# url = 'https://web.archive.org/web/20200204084331/http://www.caixin.com/2020-02-04/101511377.html'
# 读取链接文件地址:
path = './data/all_text_link_2.xlsx'
# 保存路径:
savePath = './data/text_0.xlsx'
getContent(path, savePath)t2.py:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/2/13 13:46
# @Author : ystraw
# @Site :
# @File : t2.py
# @Software: PyCharm Community Edition
# @function: 对t1获得的 alltext.xlsx 进行必要的处理
# 1、删除空行
import numpy
import pandas as pd
import jieba
# 读入文件
def readFile(filename):
with open(filename, 'r', encoding='utf-8') as f:
str = f.read()
print(filename, '已读入!')
f.close()
return str
# 删除空行
def dealNull(path, savepath):
data = pd.read_excel(path, sheet_name=0)
df = pd.DataFrame(data)
# print(data.head()) # 无参时默认读前五行
# print(data.tail()) # 无参时默认读后五行
print(data.shape) # 查看数据大小
print(data.columns) # 查看数据的列索引
# 数据表基本信息(维度、列名称、数据格式、所占空间等)
print(data.info())
# 每一列数据的格式
print('格式:\n', df.dtypes)
# 读取某列的某行数据
# df['文章内容'].astype('str')
# df['文章内容'] = df['文章内容'].map(str.strip)
# print(data['文章内容'].at[123])
# 读取表格数据内容(不包括标题)
# print(data.values)
# 判断每一行的文章内容是否为空
data_notnull = data['文章内容'].notnull()
# print(data_notnull)
# 删除空行
data_new = data[data_notnull]
# print(data_new)
print('删除空行之后的大小:\n', data_new.shape)
# 保存文件
data_new.to_excel(savepath, index=False, header=True)
# 分词并统计词频
def fenci(content):
# 读入停留词文件:
sword = readFile('./data/stopword.txt')
# 构建停留词词典:
sword = sword.split('\n')
worddict = {}
wordlist = []
for w in jieba.cut(content, cut_all=False): # cut_all=False为精确模式,=True为全模式
# print(w)
if (w not in sword) and w != '' and w != ' ' and w != None and w != '\n' and len(w) >= 2:
# print(w + '-')
wordlist.append(w)
try:
worddict[w] = worddict[w] + 1
except:
worddict[w] = 1
# print(worddict)
return [worddict, wordlist]
# 数据预处理
def preDeal(path, savepath):
# 读取数据
data = pd.read_excel(path, sheet_name=0)
df = pd.DataFrame(data)
# 加一列
df['文章内容分词'] = None
for i in range(df.shape[0]):
# 进行分词
rt = fenci(df['文章内容'].at[i])
df['文章内容分词'].at[i] = ' '.join(rt[1])
# 保存文件
df.to_excel(savepath, index=False, header=True)
if __name__ == '__main__':
'''
数据清洗
'''
# # 删除空行
# path = './data/text_0.xlsx'
# savepath = './data/text_1.xlsx'
# dealNull(path, savepath)
'''
数据预处理
'''
path = './data/text_1.xlsx'
savepath = './data/text_2.xlsx'
preDeal(path, savepath)t3.py:
# 导入Geo包,注意1.x版本的导入跟0.x版本的导入差别
# 更新方法:pip install --upgrade pyecharts
from pyecharts.charts import Geo
# 导入配置项
from pyecharts import options as opts
# ChartType:图标类型,SymbolType:标记点类型
from pyecharts .globals import ChartType, SymbolType
# 读入文件
def readFile(filename):
with open(filename, 'r', encoding='utf-8') as f:
str = f.read()
print(filename, '已读入!')
f.close()
return str
geo = Geo()
# 新增坐标点,添加名称跟经纬度
# 读入城市坐标数据:
zb_city = readFile('./data/1-5LineCity_2.txt')
# geo.add_coordinate(name="China",longitude=104.195,latitude=35.675)
cityList = zb_city.split('\n')
for cy in cityList:
if cy == '' or cy == None:
continue
temp = cy.split(',')
geo.add_coordinate(name=temp[0], longitude=temp[2], latitude=temp[1])
# 地图类型,世界地图可换为world
geo.add_schema(maptype="china")
# 获取权重:
cityList = readFile('./data/city_node.csv').split('\n')
data = []
for i in range(len(cityList)):
city = cityList[i]
if i == 0 or city == '' or city == None:
continue
data.append((city.split(' ')[0], int(city.split(' ')[2])))
# print(data)
# 获取流向
cityList = readFile('./data/city_edge.csv').split('\n')
data2 = []
for i in range(len(cityList)):
city = cityList[i]
if i == 0 or city == '' or city == None:
continue
# 共现次数较少的不展示:
if int(city.split(' ')[2]) < 200:
continue
data2.append((city.split(' ')[0], city.split(' ')[1]))
# print(data2)
# 添加数据点
# geo.add("",[("北京",10),("上海",20),("广州",30),("成都",40),("哈尔滨",50)],type_=ChartType.EFFECT_SCATTER)
geo.add("", data, type_=ChartType.EFFECT_SCATTER)
# 添加流向,type_设置为LINES,涟漪配置为箭头,提供的标记类型包括 'circle', 'rect', 'roundRect', 'triangle',
#'diamond', 'pin', 'arrow', 'none'
geo.add("geo-lines",
data2,
type_=ChartType.LINES,
effect_opts=opts.EffectOpts(symbol=SymbolType.ARROW,symbol_size=10,color="yellow"),
linestyle_opts=opts.LineStyleOpts(curve=0.2),
is_large=True)
# 不显示标签
geo.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
# 设置图标标题,visualmap_opts=opts.VisualMapOpts()为左下角的视觉映射配置项
geo.set_global_opts(visualmap_opts=opts.VisualMapOpts(),title_opts=opts.TitleOpts(title="城市动态流向图"))
# 直接在notebook里显示图表
geo.render_notebook()
# 生成html文件,可传入位置参数
geo.render("城市动态流向图.html")
dataAnalysis.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/2/17 18:42
# @Author : ystraw
# @Site :
# @File : dataAnalysis.py
# @Software: PyCharm Community Edition
# @function: 进行数据分析
import folium
import codecs
from folium.plugins import HeatMap
from pyecharts.charts import Geo
from pyecharts.charts import Map
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 读入文件
def readFile(filename):
with open(filename, 'r', encoding='utf-8') as f:
str = f.read()
print(filename, '已读入!')
f.close()
return str
# 描述性分析
def ms_analysis(filepath):
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['font.serif'] = ['KaiTi']
# 读入数据
data = pd.read_excel(filepath)
'''
发文数量、来源和发文日期
'''
# 绘制文章发布量与日期及来源关系图:
# data.groupby('日期')['文章来源'].value_counts().unstack().fillna(value=0).plot(kind='bar', title='文章发布量分日统计')
# plt.show()
# return
'''
城市提及分析
'''
# 读入城市数据,构建城市字典:
city = readFile('./data/1-5LineCity_2.txt')
cityList = city.split('\n')
# print(cityList)
# 构建城市频率:
cityDict = {}
for cy in cityList:
if cy == '' or cy == None:
continue
temp = cy.split(',')
cityDict[temp[0][:-1]] = 0
# print(cityDict)
print(data.shape[0], data.shape[1])
# 进行统计
for i in range(data.shape[0]):
wordList = data['文章内容分词'].at[i].split(' ')
for word in wordList:
try:
cityDict[word] += 1
except:
pass
# break
print(cityDict)
# 绘制地图:
# 取字典中的值
# provice = list(cityDict.keys())
# values = list(cityDict.values())
# 填充数据
data = []
for cy in cityList:
if cy == '' or cy == None:
continue
temp = cy.split(',')
data.append([float(temp[1]), float(temp[2]), cityDict[temp[0][:-1]]])
# data=[[ 31.235929,121.480539, 1500 ]] #
print(data)
map_osm = folium.Map([33., 113.], zoom_start=12) #绘制Map,开始缩放程度是5倍
HeatMap(data).add_to(map_osm) # 将热力图添加到前面建立的map里
map_osm.save('./image/文章提及城市分布.html')#将绘制好的地图保存为html文件
# 得到城市共现矩阵文件
def city_gx_analysis(filepath):
citys = {} # 城市字典
relationships = {} # 关系字典
lineCitys = [] # 每篇城市关系
# 构建城市集合:
cityList = readFile('./data/1-5LineCity.txt').split('\n')
citySet = set()
for city in cityList:
citySet.add(city.replace('市', ''))
# 读入分词数据
data = pd.read_excel(filepath)
# 填充邻接矩阵
for i in range(data.shape[0]):
wordList = data['文章内容分词'].at[i].split(' ')
lineCitys.append([])
for word in wordList:
if word not in citySet:
continue
lineCitys[-1].append(word)
if citys.get(word) is None:
citys[word] = 0
relationships[word] = {}
# 出现次数加1
citys[word] += 1
# explore relationships
for line in lineCitys: # 对于每一段
for city1 in line:
for city2 in line: # 每段中的任意两个城市
if city1 == city2:
continue
if relationships[city1].get(city2) is None: # 若两个城市尚未同时出现则新建项
relationships[city1][city2]= 1
else:
relationships[city1][city2] = relationships[city1][city2]+ 1 # 两个城市共同出现次数加 1
# output
with codecs.open("./data/city_node.csv", "w", "utf-8") as f:
f.write("Id Label Weight\r\n")
for city, times in citys.items():
f.write(city + " " + city + " " + str(times) + "\r\n")
with codecs.open("./data/city_edge.csv", "w", "utf-8") as f:
f.write("Source Target Weight\r\n")
for city, edges in relationships.items():
for v, w in edges.items():
if w > 3:
f.write(city + " " + v + " " + str(w) + "\r\n")
if __name__ == '__main__':
filepath = './data/text_2.xlsx'
# 描述性分析
# ms_analysis(filepath)
# 分析城市间的共现关系
city_gx_analysis(filepath)
TF-IDF.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/2/23 22:20
# @Author : ystraw
# @Site :
# @File : TF-IDF.py
# @Software: PyCharm Community Edition
# @function: 对文本内容进行关键词提取
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
from openpyxl import Workbook
# 写入Excel
def write_excel_xls(path, sheet_name, value, bHead):
# 获取需要写入数据的行数
index = len(value)
# 获取需要写入数据的行数
index = len(value)
wb = Workbook()
# 激活 worksheet
ws = wb.active
# 第一行输入
ws.append(bHead)
# .cell(row=x, column=2, value=z.project)
for i in range(2, index+2):
for j in range(1, len(value[i-2]) + 1):
# ws.append(value[i])
ws.cell(row=i, column=j, value=value[i-2][j-1])
# 保存
wb.save(path)
print(path + '表格写入数据成功!')
def TQ():
# 读入数据
filepath = './data/text_2.xlsx'
data = pd.read_excel(filepath)
document = list(data['文章内容分词'])
# print(document)
# print(len(document))
# min_df: 当构建词汇表时,严格忽略低于给出阈值的文档频率的词条,语料指定的停用词。如果是浮点值,该参数代表文档的比例,整型绝对计数值,如果词汇表不为None,此参数被忽略。
tfidf_model = TfidfVectorizer(min_df=0.023).fit(document)
# 得到语料库所有不重复的词
feature = tfidf_model.get_feature_names()
# print(feature)
# print(len(feature))
# ['一切', '一条', '便是', '全宇宙', '天狗', '日来', '星球']
# 得到每个特征对应的id值:即上面数组的下标
# print(tfidf_model.vocabulary_)
# {'一条': 1, '天狗': 4, '日来': 5, '一切': 0, '星球': 6, '全宇宙': 3, '便是': 2}
# 每一行中的指定特征的tf-idf值:
sparse_result = tfidf_model.transform(document)
# print(sparse_result)
# 每一个语料中包含的各个特征值的tf-idf值:
# 每一行代表一个预料,每一列代表这一行代表的语料中包含这个词的tf-idf值,不包含则为空
weight = sparse_result.toarray()
# 构建词与tf-idf的字典:
feature_TFIDF = {}
for i in range(len(weight)):
for j in range(len(feature)):
# print(feature[j], weight[i][j])
if feature[j] not in feature_TFIDF:
feature_TFIDF[feature[j]] = weight[i][j]
else:
feature_TFIDF[feature[j]] = max(feature_TFIDF[feature[j]], weight[i][j])
# print(feature_TFIDF)
# 按值排序:
print('TF-IDF 排名前十的:')
alldata = []
featureList = sorted(feature_TFIDF.items(), key=lambda kv: (kv[1], kv[0]), reverse=True)
for i in range(1, 600 if len(featureList) > 600 else len(featureList)):
print(featureList[i][0], featureList[i][1])
alldata.append([featureList[i][0], featureList[i][1]])
# 写入文件:
tableHead = ['关键词', 'TF-IDF']
import datetime
filetime = str(datetime.datetime.now()).replace('-', '').replace(' ', '_').replace(':', '_')[:17]
write_excel_xls('./data/关键词_' + filetime + '.xlsx', 'link', alldata, tableHead)
def drawWordCloud():
from wordcloud import WordCloud
from scipy.misc import imread
# 读入数据
filepath = './data/text_2.xlsx'
data = pd.read_excel(filepath)
document = list(data['文章内容分词'])
# 整理文本:
# words = '一切 一条 便是 全宇宙 天狗 日来 星球' # 样例
words = ''.join(document)
# print(words)
# 设置背景图片:
b_mask = imread('./image/ciyun.webp')
# 绘制词图:
wc = WordCloud(
background_color="white", #背景颜色
max_words=2000, #显示最大词数
font_path="./image/simkai.ttf", #使用字体
# min_font_size=5,
# max_font_size=80,
# width=400, #图幅宽度
mask=b_mask
)
wc.generate(words)
# 准备一个写入的背景图片
wc.to_file("./image/beijing_2.jpg")
if __name__ == '__main__':
'''
提取关键词
'''
# TQ()
'''
绘制词云图片
'''
drawWordCloud()LDA_主题模型.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/2/26 14:10
# @Author : ystraw
# @Site :
# @File : LDA_主题模型.py
# @Software: PyCharm Community Edition
# @function:
import pandas as pd
import numpy as np
def LDA():
# 读入数据
filepath = './data/text_2.xlsx'
data = pd.read_excel(filepath)
document = list(data['文章内容分词'])
# 获取词频向量:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
corpus = document
cntVector = CountVectorizer()
cntTf = cntVector.fit_transform(corpus)
# 输出选取词特征
vocs = cntVector.get_feature_names()
print('主题词袋:', len(vocs))
# print(vocs)
# 输出即为所有文档中各个词的词频向量
# print(cntTf)
# LDA主题模型
lda = LatentDirichletAllocation(n_components=4, # 主题个数
max_iter=5, # EM算法的最大迭代次数
learning_method='online',
learning_offset=20., # 仅仅在算法使用online时有意义,取值要大于1。用来减小前面训练样本批次对最终模型的影响
random_state=0)
docres = lda.fit_transform(cntTf)
# 类别所属概率
LDA_corpus = np.array(docres)
print('类别所属概率:\n', LDA_corpus)
# 每篇文章中对每个特征词的所属概率矩阵:list长度等于分类数量
# print('主题词所属矩阵:\n', lda.components_)
# 找到最大值所在列,确定属于的类别:
arr = pd.DataFrame(LDA_corpus)
data['主题类别'] = np.argmax(LDA_corpus, axis=1) # 求最大值所在索引
data['主题出现概率']=arr.max(axis=1) # 求行最大值
print('所属类别:\n', data.head())
data.to_excel('./data/LDA_主题分布_类别.xlsx', index=False)
# return
# 打印每个单词的主题的权重值
tt_matrix = lda.components_
# 类别id
id = 0
# 存储数据
datalist = []
for tt_m in tt_matrix:
# 元组形式
tt_dict = [(name, tt) for name, tt in zip(vocs, tt_m)]
tt_dict = sorted(tt_dict, key=lambda x: x[1], reverse=True)
# 打印权重值大于0.6的主题词:
# tt_dict = [tt_threshold for tt_threshold in tt_dict if tt_threshold[1] > 0.6]
# 打印每个类别的前20个主题词:
tt_dict = tt_dict[:20]
print('主题%d:' % id, tt_dict)
# 存储:
datalist += [[tt_dict[i][0], tt_dict[i][1], id]for i in range(len(tt_dict))]
id += 1
# 存入excel:
# df = pd.DataFrame(datalist, columns=['特征词', '权重', '类别'])
# df.to_excel('./data/LDA_主题分布3.xlsx', index=False)
if __name__ == '__main__':
'''
利用LDA主题模型进行主题提取:
'''
LDA()Snownlp情感分析.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/2/27 12:54
# @Author : ystraw
# @Site :
# @File : Snownlp情感分析.py
# @Software: PyCharm Community Edition
# @function: 进行情感分析
import pandas as pd
from snownlp import SnowNLP
def qgjs():
# 读入数据
data = pd.read_excel('./data/LDA_主题分布_类别.xlsx')
# print(data.shape)
# 进行情感打分
score = []
for i in range(0, data.shape[0]):
s = SnowNLP(data['标题'].at[i])
score.append(s.sentiments)
data['情绪得分'] = score
print(data.head())
data.to_excel('./data/情绪得分.xlsx', index=False)
if __name__ == '__main__':
qgjs()