1.数据
import pandas as pd
import jieba
#数据(一小部分的新闻数据)
df_news = pd.read_table('val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna() #直接丢弃包括NAN的整条数据
print(df_news.head())
2.分词:使用jieba库

import pandas as pd
import jieba #
#数据(一小部分的新闻数据)
df_news = pd.read_table('val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna() #直接丢弃包括NAN的整条数据
#print(df_news.head())
#分词
content = df_news.content.values.tolist() #因为jieba要列表格式
print(content[1000])
print("------------------------------------------------------")
content_S = [] #存储分完词之后结果
for line in content:
current_segment = jieba.lcut(line) #jieba分词
if len(current_segment) > 1 and current_segment != "\r\n":
content_S.append(current_segment)
print(content_S[1000])
3.#将分完词的结果转化成DataFrame格式

import pandas as pd
import jieba #
#数据(一小部分的新闻数据)
df_news = pd.read_table('val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna() #直接丢弃包括NAN的整条数据
#print(df_news.head())
#分词
content = df_news.content.values.tolist() #因为jieba要列表格式
#print(content[1000])
#print("------------------------------------------------------")
content_S = [] #存储分完词之后结果
for line in content:
current_segment = jieba.lcut(line) #jieba分词
if len(current_segment) > 1 and current_segment != "\r\n":
content_S.append(current_segment)
#print(content_S[1000])
#将分完词的结果转化成DataFrame格式
df_content = pd.DataFrame({"content_S":content_S})
print(df_content.head())
4.清洗数据(上面数据可以看到很乱),用停用词表清洗停用词
注:停用词(语料库中大量出现但是没什么用的词,比如“的”)
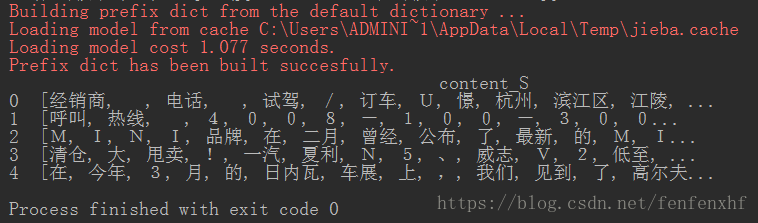
import pandas as pd
import jieba #分词
#去除停用词函数
def drop_stopwords(contents,stopwords):
contents_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word)) #所有的词组成一个列表
contents_clean.append(line_clean)
return contents_clean,all_words
#数据(一小部分的新闻数据)
df_news = pd.read_table('val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna() #直接丢弃包括NAN的整条数据
#print(df_news.head())
#分词
content = df_news.content.values.tolist() #因为jieba要列表格式
#print(content[1000])
#print("------------------------------------------------------")
content_S = [] #存储分完词之后结果
for line in content:
current_segment = jieba.lcut(line) #jieba分词
if len(current_segment) > 1 and current_segment != "\r\n":
content_S.append(current_segment)
#print(content_S[1000])
#将分完词的结果转化成DataFrame格式
df_content = pd.DataFrame({"content_S":content_S})
#print(df_content.head())
#清洗乱的数据,用停用词表去除停用词
stopwords = pd.read_csv('stopwords.txt',index_col=False,sep='\t',quoting=3,names=["stopword"],encoding="utf-8") #读入停用词
print(stopwords.head(20))
print("-------------------------------------------------")
#调用去除停用词函数
contents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
contents_clean,all_words = drop_stopwords(contents,stopwords)
#将清洗完的数据结果转化成DataFrame格式
df_content = pd.DataFrame({"contents_clean":contents_clean})
print(df_content.head())
5.用all_words统计词频
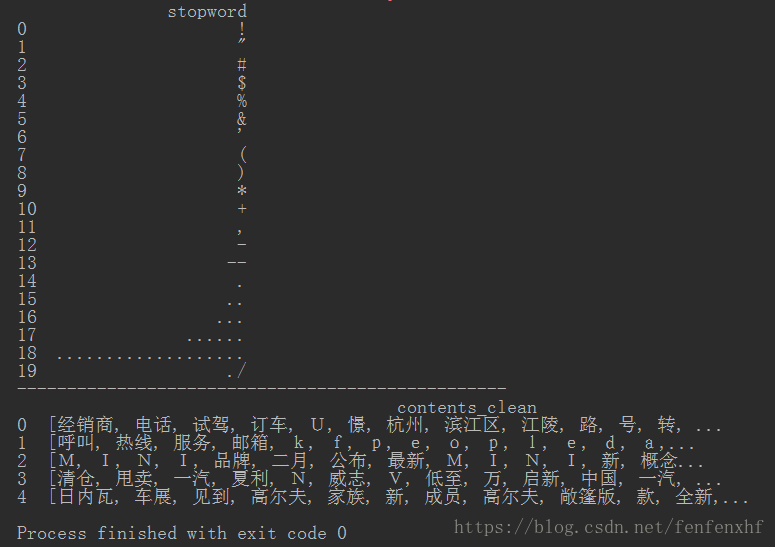
import numpy as np
import pandas as pd
import jieba #分词
#去除停用词函数
def drop_stopwords(contents,stopwords):
contents_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean,all_words
#数据(一小部分的新闻数据)
df_news = pd.read_table('val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna() #直接丢弃包括NAN的整条数据
#print(df_news.head())
#分词
content = df_news.content.values.tolist() #因为jieba要列表格式
#print(content[1000])
#print("------------------------------------------------------")
content_S = [] #存储分完词之后结果
for line in content:
current_segment = jieba.lcut(line) #jieba分词
if len(current_segment) > 1 and current_segment != "\r\n":
content_S.append(current_segment)
#print(content_S[1000])
#将分完词的结果转化成DataFrame格式
df_content = pd.DataFrame({"content_S":content_S})
#print(df_content.head())
#清洗乱的数据,用停用词表去除停用词
stopwords = pd.read_csv('stopwords.txt',index_col=False,sep='\t',quoting=3,names=["stopword"],encoding="utf-8") #读入停用词
#print(stopwords.head(20))
#print("-------------------------------------------------")
#调用去除停用词函数
contents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
contents_clean,all_words = drop_stopwords(contents,stopwords)
#将清洗完的数据结果转化成DataFrame格式
df_content = pd.DataFrame({"contents_clean":contents_clean})
df_all_words = pd.DataFrame({"all_words":all_words})
print(df_content.head())
print("-------------------------------------")
print(df_all_words.head())
#用保存的all_word统计一下词频
words_count = df_all_words.groupby(by=["all_words"])["all_words"].agg({"count":np.size}) #groupby就是按词分类
words_count = words_count.reset_index().sort_values(by=["count"],ascending=False) #降序
print(words_count.head())
6.#用jieba.analyse提取关键词(TF-IDF)
注:什么是TF-IDF(词频-逆文档频率)?
TF = 某个词在文章中出现的次数 / 文章的总词数
IDF = log (语料库中文档总数 / 包含该词的文档数+1)
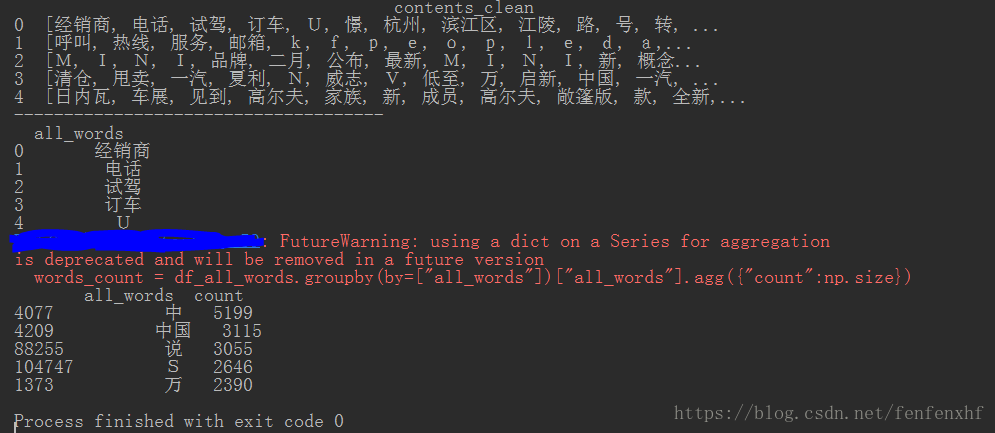
import numpy as np
import pandas as pd
import jieba #分词
from jieba import analyse
#数据(一小部分的新闻数据)
df_news = pd.read_table('val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna() #直接丢弃包括NAN的整条数据
#print(df_news.head())
#分词
content = df_news.content.values.tolist() #因为jieba要列表格式
#print(content[1000])
#print("------------------------------------------------------")
content_S = [] #存储分完词之后结果
for line in content:
current_segment = jieba.lcut(line) #jieba分词
if len(current_segment) > 1 and current_segment != "\r\n":
content_S.append(current_segment)
print(content_S[1000])
#用jieba.analyse提取关键词
index = 1000
print(df_news["content"][index]) #打印第1000数据的content
content_S_str = "".join(content_S[index]) #将单个词列表连接在一起
print(content_S_str)
print(" ".join(analyse.extract_tags(content_S_str,topK=5)))
7.LDA:主题模型
#要求格式:list of list格式,是将整个语料库分词好的list of list

import numpy as np
import pandas as pd
import jieba #分词
from jieba import analyse
import gensim #自然语言处理库
from gensim import corpora,models,similarities
#去除停用词函数
def drop_stopwords(contents,stopwords):
contents_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean,all_words
#数据(一小部分的新闻数据)
df_news = pd.read_table('val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna() #直接丢弃包括NAN的整条数据
#print(df_news.head())
#分词
content = df_news.content.values.tolist() #因为jieba要列表格式
#print(content[1000])
#print("------------------------------------------------------")
content_S = [] #存储分完词之后结果
for line in content:
current_segment = jieba.lcut(line) #jieba分词
if len(current_segment) > 1 and current_segment != "\r\n":
content_S.append(current_segment)
#print(content_S[1000])
#将分完词的结果转化成DataFrame格式
df_content = pd.DataFrame({"content_S":content_S})
#print(df_content.head())
#清洗乱的数据,用停用词表去除停用词
stopwords = pd.read_csv('stopwords.txt',index_col=False,sep='\t',quoting=3,names=["stopword"],encoding="utf-8") #读入停用词
#print(stopwords.head(20))
#print("-------------------------------------------------")
#调用去除停用词函数
contents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
contents_clean,all_words = drop_stopwords(contents,stopwords)
#将清洗完的数据结果转化成DataFrame格式
df_content = pd.DataFrame({"contents_clean":contents_clean})
df_all_words = pd.DataFrame({"all_words":all_words})
#print(df_content.head())
#print("-------------------------------------")
#print(df_all_words.head())
#LDA:主题模型
#要求格式:list of list格式,是将整个语料库分词好的list of list
#做映射,相当于词袋
dictionary = corpora.Dictionary(contents_clean) #将清洗完的数据生成字典形式
corpus = [dictionary.doc2bow(sentence) for sentence in contents_clean]
print(dictionary)
print("---------------------")
print(corpus)
print("---------------------")
lda = gensim.models.LdaModel(corpus=corpus,id2word=dictionary,num_topics=20)
#打印1号分类结果
print(lda.print_topic(1,topn=5))
8.新闻分类
第一步:现将数据集的标签转换成sklearn可以识别的数值型格式

import numpy as np
import pandas as pd
import jieba #分词
from jieba import analyse
import gensim #自然语言处理库
from gensim import corpora,models,similarities
#去除停用词函数
def drop_stopwords(contents,stopwords):
contents_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean,all_words
#数据(一小部分的新闻数据)
df_news = pd.read_table('val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna() #直接丢弃包括NAN的整条数据
#print(df_news.head())
#分词
content = df_news.content.values.tolist() #因为jieba要列表格式
#print(content[1000])
#print("------------------------------------------------------")
content_S = [] #存储分完词之后结果
for line in content:
current_segment = jieba.lcut(line) #jieba分词
if len(current_segment) > 1 and current_segment != "\r\n":
content_S.append(current_segment)
#print(content_S[1000])
#将分完词的结果转化成DataFrame格式
df_content = pd.DataFrame({"content_S":content_S})
#print(df_content.head())
#清洗乱的数据,用停用词表去除停用词
stopwords = pd.read_csv('stopwords.txt',index_col=False,sep='\t',quoting=3,names=["stopword"],encoding="utf-8") #读入停用词
#print(stopwords.head(20))
#print("-------------------------------------------------")
#调用去除停用词函数
contents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
contents_clean,all_words = drop_stopwords(contents,stopwords)
#将清洗完的数据结果转化成DataFrame格式
df_content = pd.DataFrame({"contents_clean":contents_clean})
df_all_words = pd.DataFrame({"all_words":all_words})
#print(df_content.head())
#print("-------------------------------------")
#print(df_all_words.head())
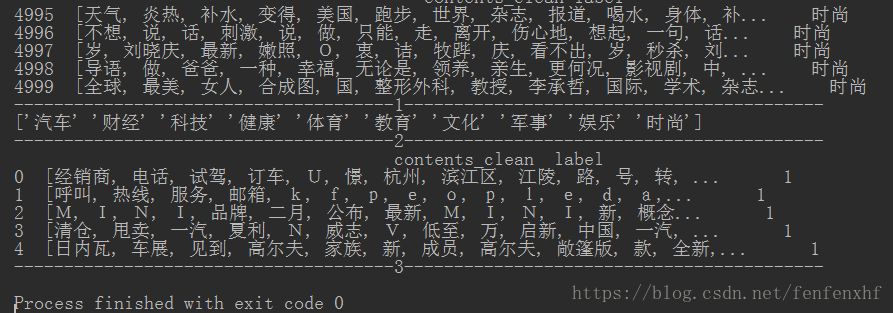
#新闻分类
#打印DataFreme格式的内容和标签
df_train = pd.DataFrame({"contents_clean":contents_clean,"label":df_news["category"]})
print(df_train.tail()) #打印最后几个数据
print("--------------------------------------1------------------------------------------")
print(df_train.label.unique()) #打印标签的种类
print("--------------------------------------2------------------------------------------")
#因为sklearn只识别数值型标签,所以将字符型标签转换成数值型
label_mappping = {'汽车':1,'财经':2, '科技':3, '健康':4, '体育':5, '教育':6, '文化':7, '军事':8, '娱乐':9, '时尚':0}
df_train["label"] = df_train["label"].map(label_mappping)
print(df_train.head())
print("--------------------------------------3------------------------------------------")
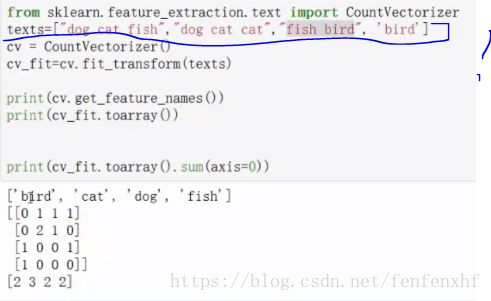
第二步:将清洗过的文章分词转化成朴素贝叶斯的矩阵形式[[],[],[],[]…]
如:注意标注的格式,下面需要将数据转化成这种格式
import numpy as np
import pandas as pd
import jieba #分词
from jieba import analyse
import gensim #自然语言处理库
from gensim import corpora,models,similarities
from sklearn.feature_extraction.text import CountVectorizer #词集转换成向量
from sklearn.model_selection import train_test_split
#去除停用词函数
def drop_stopwords(contents,stopwords):
contents_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean,all_words
def format_transform(x): #x是数据集(训练集或者测试集)
words =[]
for line_index in range(len(x)):
try:
words.append(" ".join(x[line_index]))
except:
print("数据格式有问题")
return words
def vec_transform(words):
vec = CountVectorizer(analyzer="word",max_features=4000,lowercase=False)
return vec.fit(words)
#数据(一小部分的新闻数据)
df_news = pd.read_table('val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna() #直接丢弃包括NAN的整条数据
#print(df_news.head())
#分词
content = df_news.content.values.tolist() #因为jieba要列表格式
#print(content[1000])
#print("------------------------------------------------------")
content_S = [] #存储分完词之后结果
for line in content:
current_segment = jieba.lcut(line) #jieba分词
if len(current_segment) > 1 and current_segment != "\r\n":
content_S.append(current_segment)
#print(content_S[1000])
#将分完词的结果转化成DataFrame格式
df_content = pd.DataFrame({"content_S":content_S})
#print(df_content.head())
#清洗乱的数据,用停用词表去除停用词
stopwords = pd.read_csv('stopwords.txt',index_col=False,sep='\t',quoting=3,names=["stopword"],encoding="utf-8") #读入停用词
#print(stopwords.head(20))
#print("-------------------------------------------------")
#调用去除停用词函数
contents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
contents_clean,all_words = drop_stopwords(contents,stopwords)
#将清洗完的数据结果转化成DataFrame格式
df_content = pd.DataFrame({"contents_clean":contents_clean})
df_all_words = pd.DataFrame({"all_words":all_words})
#print(df_content.head())
#print("-------------------------------------")
#print(df_all_words.head())
#新闻分类
#打印DataFreme格式的内容和标签
df_train = pd.DataFrame({"contents_clean":contents_clean,"label":df_news["category"]})
#print(df_train.tail()) #打印最后几个数据
#print("--------------------------------------1------------------------------------------")
#print(df_train.label.unique()) #打印标签的种类
#print("--------------------------------------2------------------------------------------")
#因为sklearn只识别数值型标签,所以将字符型标签转换成数值型
label_mappping = {'汽车':1,'财经':2, '科技':3, '健康':4, '体育':5, '教育':6, '文化':7, '军事':8, '娱乐':9, '时尚':0}
df_train["label"] = df_train["label"].map(label_mappping)
#print(df_train.head())
#print("--------------------------------------3------------------------------------------")
#切分数据集
x_train,x_test,y_train,y_test = train_test_split(df_train["contents_clean"].values,df_train["label"].values)
#将清洗过的文章分词转化成朴素贝叶斯的矩阵形式[[],[],[],[]...]
#首先将数据的分词(list of list)转换成["a b c","a b c",...]这种格式,因为调用的包只识别这种格式
#调用函数format_transform()函数
words_train = format_transform(x_train)
words_test = format_transform(x_test)
#转化成向量格式,调用函数vec_transform()
vec_trian = vec_transform(words_train)
vec_test = vec_transform(words_test)
print(vec_trian.transform(words_train))
print("------------------------------------------------")
print(vec_test)
第三步:训练数据,并给出测试的效果
import numpy as np
import pandas as pd
import jieba #分词
from jieba import analyse
import gensim #自然语言处理库
from gensim import corpora,models,similarities
from sklearn.feature_extraction.text import CountVectorizer #词集转换成向量
from sklearn.feature_extraction.text import TfidfVectorizer #另一个转换成向量的库
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB #朴素贝叶斯多分类
#去除停用词函数
def drop_stopwords(contents,stopwords):
contents_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean,all_words
def format_transform(x): #x是数据集(训练集或者测试集)
words =[]
for line_index in range(len(x)):
try:
words.append(" ".join(x[line_index]))
except:
print("数据格式有问题")
return words
def vec_transform(words):
vec = CountVectorizer(analyzer="word",max_features=4000,lowercase=False)
return vec.fit(words)
#数据(一小部分的新闻数据)
df_news = pd.read_table('val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna() #直接丢弃包括NAN的整条数据
#print(df_news.head())
#分词
content = df_news.content.values.tolist() #因为jieba要列表格式
#print(content[1000])
#print("------------------------------------------------------")
content_S = [] #存储分完词之后结果
for line in content:
current_segment = jieba.lcut(line) #jieba分词
if len(current_segment) > 1 and current_segment != "\r\n":
content_S.append(current_segment)
#print(content_S[1000])
#将分完词的结果转化成DataFrame格式
df_content = pd.DataFrame({"content_S":content_S})
#print(df_content.head())
#清洗乱的数据,用停用词表去除停用词
stopwords = pd.read_csv('stopwords.txt',index_col=False,sep='\t',quoting=3,names=["stopword"],encoding="utf-8") #读入停用词
#print(stopwords.head(20))
#print("-------------------------------------------------")
#调用去除停用词函数
contents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
contents_clean,all_words = drop_stopwords(contents,stopwords)
#将清洗完的数据结果转化成DataFrame格式
df_content = pd.DataFrame({"contents_clean":contents_clean})
df_all_words = pd.DataFrame({"all_words":all_words})
#print(df_content.head())
#print("-------------------------------------")
#print(df_all_words.head())
#新闻分类
#打印DataFreme格式的内容和标签
df_train = pd.DataFrame({"contents_clean":contents_clean,"label":df_news["category"]})
#print(df_train.tail()) #打印最后几个数据
#print("--------------------------------------1------------------------------------------")
#print(df_train.label.unique()) #打印标签的种类
#print("--------------------------------------2------------------------------------------")
#因为sklearn只识别数值型标签,所以将字符型标签转换成数值型
label_mappping = {'汽车':1,'财经':2, '科技':3, '健康':4, '体育':5, '教育':6, '文化':7, '军事':8, '娱乐':9, '时尚':0}
df_train["label"] = df_train["label"].map(label_mappping)
#print(df_train.head())
#print("--------------------------------------3------------------------------------------")
#切分数据集
x_train,x_test,y_train,y_test = train_test_split(df_train["contents_clean"].values,df_train["label"].values)
#将清洗过的文章分词转化成朴素贝叶斯的矩阵形式[[],[],[],[]...]
#首先将数据的分词(list of list)转换成["a b c","a b c",...]这种格式,因为调用的包只识别这种格式
#调用函数format_transform()函数
words_train = format_transform(x_train)
words_test = format_transform(x_test)
#转化成向量格式,调用函数vec_transform()
vec_trian = vec_transform(words_train)
#vec_test = vec_transform(words_test)
#print(vec_trian.transform(words_train))
#print("------------------------------------------------")
#print(vec_test)
#训练
nbm = MultinomialNB()
nbm.fit(vec_trian.transform(words_train),y_train)
#测试
score = nbm.score(vec_trian.transform(words_test),y_test)
print(score) #0.8016