所谓的消息可靠性指的是Kafka 对生产者和消费者提出的一种保证。常见的有三种。
- 最多一次: 有可能少 意思是有可能出现消息丢失的现象
- 最少一次:有可能多 意思是有可能出现重复消费
- 精准一次: 不多不少 不会丢也不会重复消费
目前生产者默认提供的是最少一次的策略,为什么呢。发送消息并且收到Broker应答即一次消息发送成功。假设消息发送成功了但是由于网络的原因没有收到Broker 的答复此时生产者会重试再一次发送这个消息。这个导致了最少一次的情况出现。
我们也可以禁止Kafka的重试机制来达到 最多一次的策略。
但是无论是最多一次还是最少一次都不如精准一次来的那么有吸引力本篇就来介绍两种方法来实现Kafka 的精准一次。
一. 事务
相信学过mysql 一类的关系型数据库大概都清楚事务是个什么东西。事务型的生产者能保证一批数据原子性的写入多个分区要么全部写入成功,要么全部写入失败。那么怎么设置呢像下面这样的,但是还不够哦需要在代码里面手动的去编写事务。
开启 enable.idempotence =true。
设置 Producer 端参数 transctional. id。
代码如下
Map map=new HashMap<String,Object>();
map.put("bootstrap.servers","localhost:9092");
map.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
map.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
map.put("transactional.id","TransscationDemo");
KafkaProducer kafkaProducer=new KafkaProducer(map);
kafkaProducer.initTransactions();
try {
kafkaProducer.beginTransaction();
kafkaProducer.send(new ProducerRecord("test-topic","id1","1"));
kafkaProducer.send(new ProducerRecord("test-topic","id2","2"));
kafkaProducer.commitTransaction();
}catch (KafkaException e){
kafkaProducer.abortTransaction();
e.printStackTrace();
}
kafkaProducer.close();
通过这样的方式,两条记录要么同时发送成功要么同时失败被回滚。实际上即使写入失败,Kafka 也会把它们写入到底层的日志中,也就是说 Consumer 还是会看到这些消息。因此在 Consumer 端,读取事务型 Producer 发送的消息也是需要一些变更的。修改起来也很简单,设置 isolation.level参数的值即可。当前这个参数有两个取值。
- read_uncommitted:这是默认值,表明 Consumer 能够读取到 Kafka 写入的任何消息,不论事务型 Producer提交事务还是终止事务,其写入的消息都可以读取。很显然,如果你用了事务型 Producer,那么对应的Consumer 就不要使用这个值。
- read_committed:表明 Consumer 只会读取事务型Producer 成功提交事务写入的消息。当然了,它也能看到非事务型 Producer 写入的所有消息。
二. 幂等
幂等这个词源自于数学指的是函数就算被执行多次也不会影响结果。
幂等性有很多好处,其最大的优势在于我们可以安全地重试任何幂等性操作,它们也不会破坏我们的系统状态。在Kafka中只需要一个配置就可以实现幂等。
为了实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。
- PID。每个新的Producer在初始化的时候会被分配一个唯一的PID,这个PID对用户是不可见的。
- Sequence Numbler。(对于每个PID,该Producer发送数据的每个<Topic, Partition>都对应一个从0开始单调递增的Sequence Number。Broker端在缓存中保存了这seq number,对于接收的每条消息,如果其序号比Broker缓存中序号大于1则接受它,否则将其丢弃。这样就可以实现了消息重复提交了。
它只能保证单分区上的幂等性,即一个幂等性Producer 能够保证某个主题的一个分区上不出现重复消息,它无法实现多个分区的幂等性。其次,它只能实现单会
话上的幂等性,不能实现跨会话的幂等性。这里的会话,你可以理解为 Producer 进程的一次运行。当你重启了Producer 进程之后,这种幂等性保证就丧失了用个图描述一下:
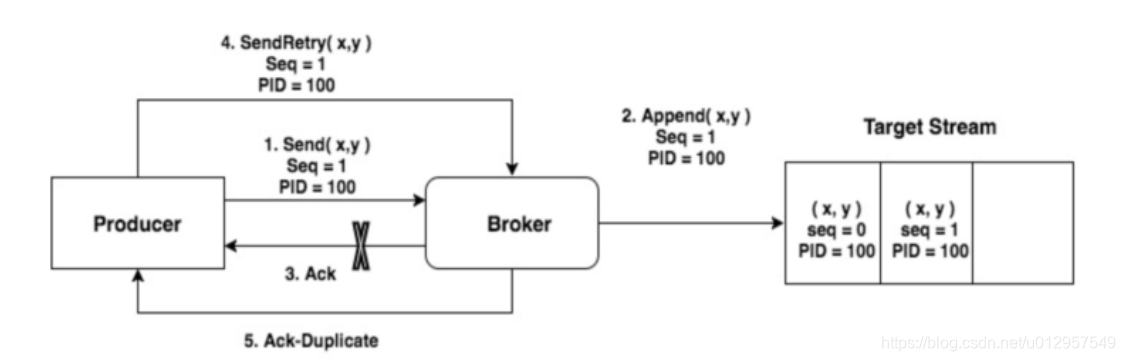
那怎么保证多个分区的幂等呢 可以使用事务。
三. 两者关系
事务属性实现前提是幂等性,即在配置事务属性transaction id时,必须还得配置幂等性;但是幂等性是可以独立使用的,不需要依赖事务属性。
幂等性引入了Porducer ID
事务属性引入了Transaction Id属性。、
设置
enable.idempotence = true,transactional.id不设置:只支持幂等性。
enable.idempotence = true,transactional.id设置:支持事务属性和幂等性
enable.idempotence = false,transactional.id不设置:没有事务属性和幂等性的kafka
enable.idempotence = false,transactional.id设置:无法获取到PID,此时会报错
四 总结
幂等性 Producer 和事务型 Producer 都是Kafka 社区力图为 Kafka 实现精确一次处理语义所提供的工具,只是它们的作用范围是不同的。幂等性 Producer 只能保证单分区、单会话上的消息幂等性;而事务能够保证跨分区、跨会话间的幂等性。但事务型 比幂等性 性能要差很多所以选择可靠性还是要根据业务的逻辑去判定不要盲目的去选择精确最高级的。
