用过kafka的可能或多或少了解一些kafka的分partition. 本篇来介绍一下生产者怎么来进行消息分区的机制和意义
我们在使用Kafka 一个比较希望的事情就是数据能够很均匀的将数据分配到所有的服务器上面,这样不仅可以更高效的去利用集群的资源也能是服务的可用性和稳定性变得更好。
本文就来聊聊kafka是怎么实现的. 。在前面我说过 Kafka 有Topic的概念,它是承载真实数据的逻辑容器,而在主题之下还分为若干个分区,也就是说 Kafka 的消息组织方式实际上是三级结构:主题 - 分区 - 消息。主题下的每条消息只会保存在某一个分区中,而不会在多个分区中被保存多份这样避免重复消费这里要区别于副本的概念。
这里那一个官网的图来坐镇这里注意这里的0,1,2,3 不是消息的内容而是偏移量。
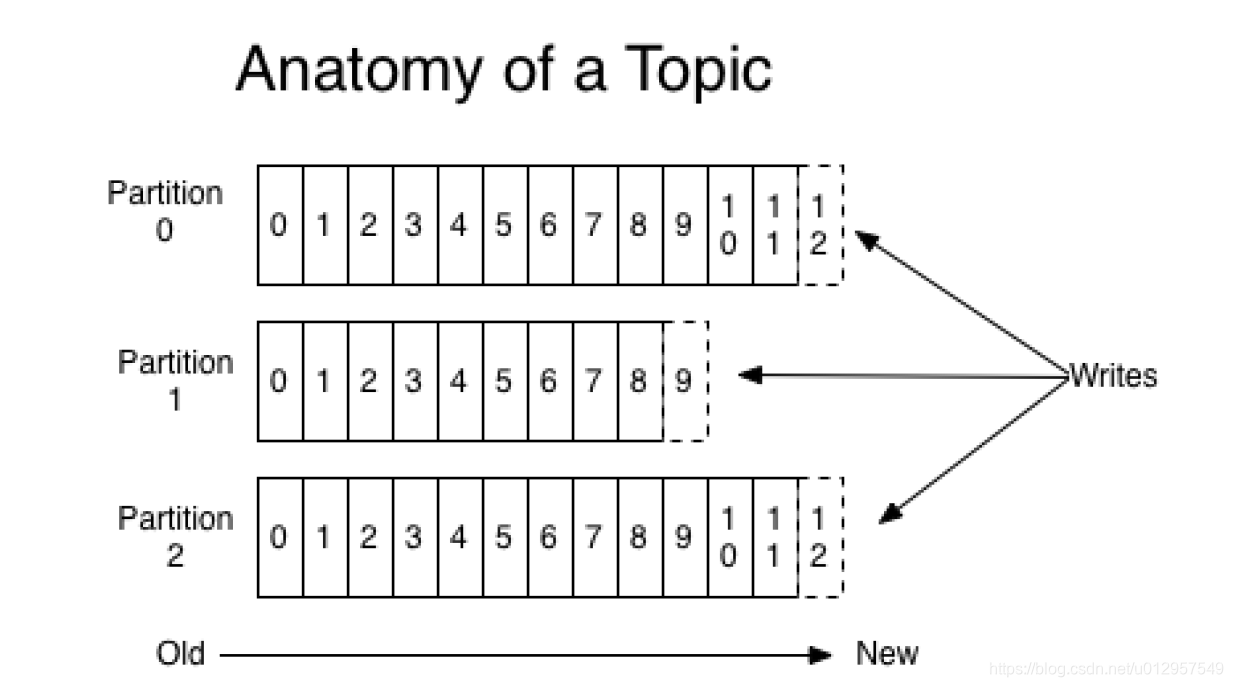
其实要实现这样的也可以通过创建多个topic 来做那为什么要提出分区这个概念呢。其实主要为了实现系统的高伸缩性提供负载均衡的能力。
不同的分区能够被放置到不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的,这样每个节点的机器都能独立地执行各自分区的读写请求处
理。并且,我们还可以通过添加新的节点机器来增加整体系统的吞吐量。
分区的概念在很早就被提出来了,也有不少的商业案例中应用到了。比如熟悉的TD teradata,HBase等等.
那么Kafka 支持那些分区策略呢比如下面这两种比较常见得了。
-
轮询策略
也称 Round-robin 策略,即顺序分配。比如一个主题下有3 个分区,那么第一条消息被发送到分区 0,第二条被发送到分区 1,第三条被发送到分区 2,以此类推。当生产第 4条消息时又会重新开始,即将其分配到分区 0,就像下面这张图展示的那样

这就是所谓的轮询策略。轮询策略是 Kafka Java 生产者API 默认提供的分区策略。如果你未指定partitioner.class参数,那么你的生产者程序会按照轮询的方式在主题的所有分区间均匀地“码放”消息。轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是我们最常用的分区策略之一。 -
随机策略
也称 Randomness 策略。所谓随机就是我们随意地将消息放置到任意一个分区上,如下面这张图所示。
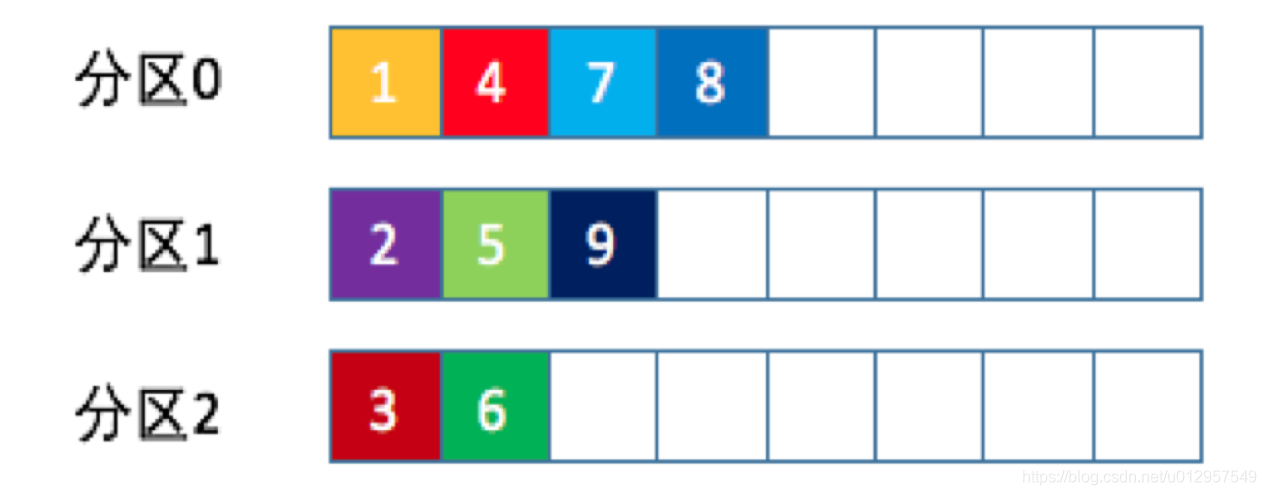
本质上看随机策略也是力求将数据均匀地打散到各个分区,但从实际表现来看,它要逊于轮询策略,所以如果追求数据的均匀分布,还是使用轮询策略比较好。事实上,随机策略是老版本生产者使用的分区策略,在新版本中已经改为轮询了。
下面做一个小结
分区是实现负载均衡以及高吞吐量的关键,故在生产者这一端就要仔细盘算合适的分区策略,避免造成消息数据的“倾斜”,使得某些分区成为性能瓶颈,这样极易引发下游数据消费的性能下降。
