kafka 可靠性保证
存储机制
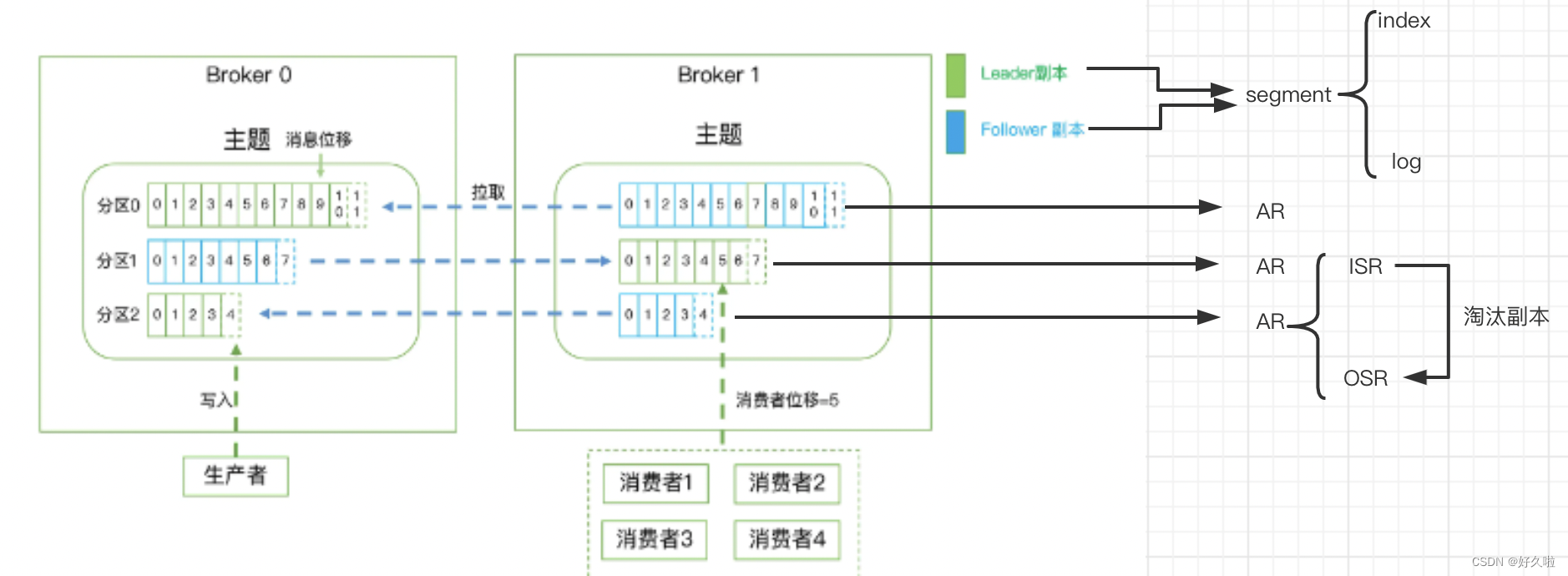
- 服务器由多个broker组成,broker下多个topic
- topic下多个partition,每个partition为一个目录,里面是存储不同消息的segment,相当于一个巨型文件被平均分配到多个大小相等的segment(段)数据文件中,每个segment 文件中消息数量不一定相等
- segment文件由两部分组成,分别为“.index”文件和“.log”文件,分别表示为索引文件和数据文件。这两个文件的命令规则为:partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值,“.index”索引文件存储对应".log"数据文件中message的偏移地址
- 消费者读取消息的步骤可以理解为:先于index文件的名字相比较,定位到具体的index文件之后,通过index文件定位到具体消息的物理偏移量
复制与同步
新名词:
- AR(Assigned Replicas):所有副本构成的集合,即leader副本+follower副本
- ISR(In-Sync Replicas):leader副本+必须要与leader副本保持一定程度同步的follower副本
- OSR(Out Sync Replicas):与leader副本同步滞后过多的follower副本
每个分区的leader负责维护和跟踪ISR中所有follower滞后的状态。当producer发送一条消息到broker后,leader写入消息并复制到ISR中所有follower。消息复制延迟受最慢的follower限制,重要的是快速检测慢副本,follower从leader同步数据有一些延迟时间,任意一个超过阈值
replica.lag.time.max.ms都会把follower剔除出ISR,移入OSR。
- 以上三个集合满足一个等式:
AR = ISR + OSR - HW(HighWatermark):在分区层级上看,指consumer能够看到的此partition的位置;从分区的副本层级上看,是当前副本同步的消息offset
- LEO(LogEndOffset):标识当前日志文件中最后一条消息的offset
每个分区副本都要维护自己的
HW,取partition维护的ISR(leader副本+follower副本)最小的LEO作为HW,consumer最多只能消费到HW所在的位置。分区所有副本各自负责更新自己的HW的状态。
对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。
图片来源于转载处
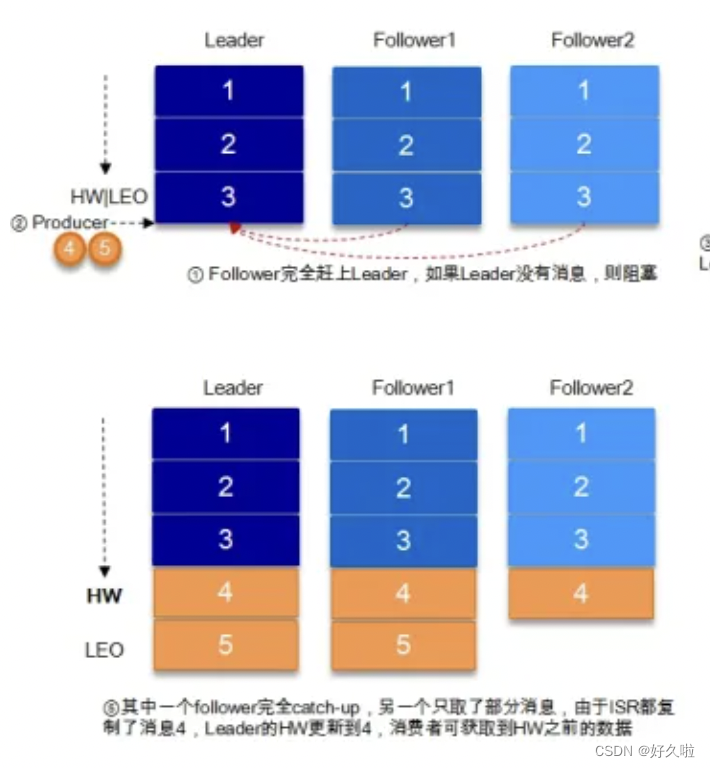
- kafka既不是完全的同步复制也不是完全的异步复制
- 同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据
实际应用中,producer配置信息中acks参数实际也与以上信息有所关联
acks
- acks = 0:生产者发送消息之后就不管了,也不论消息是否正确被接收到
- acks = 1:leader副本会将数据写入到本地日志
- acks = -1:ISR中的所有副本都需同步到消息
- 这种情况下还不能完全保证可靠性,min.insync.replicas最小同步副本数,即ISR能容忍的最小个数
- 假设只有一个leader副本,min.insync.replicas = 1,如果此时leader副本宕机,生产者无法写入消息,消费者无法正常消费消息
- 假设有一个leader副本 + follower副本,如果min.insync.replicas = 1,无法保证有其他follower副本与leader副本同步数据的程度是在消费者可见范围,仍然存在不可靠性
- 假设有一个leader副本 + follower副本,如果min.insync.replicas = 2,如果此时leader副本宕机,就算follower副本通过leader选举成为了leader副本,但此时ISR列表只剩下一个副本,不满足设置的最小副本数,客户端会返回异常:org.apache.kafka.common.errors.NotEnoughReplicasExceptoin: Messages are rejected since there are fewer in-sync replicas than required;可以通过更改参数配置等于1去恢复写服务
- 这种情况下还不能完全保证可靠性,min.insync.replicas最小同步副本数,即ISR能容忍的最小个数
消息传输的保障
- At most once: 消息可能会丢,但绝不会重复传输
- At least once:消息绝不会丢,但可能会重复传输
- Exactly once:每条消息肯定会被传输一次且仅传输一次
从生产者发送消息角度
- 当producer向broker发送消息时,一旦消息被commit,由于副本机制的存在,它就不会丢失。但如果producer发送数据给broker后,遇到的网络问题而造成类似于producer没有及时收到broker返回的消息确认ack等通信问题,producer就无法判断该条消息是否已经提交,导致producer重新发送,确保消息已经正确传输到broker中,也就是at least once
从消费者读取消息角度
- consumer从broker中读取消息后,可以选择commit,该操作会在Zookeeper中存储consumer在该partition的读取进度offset。如未commit,下一次读取的开始位置会跟上一次commit之后的开始位置相同。也可以将consumer设置为auto commit,即consumer一旦读取到数据立即自动commit。单单读取消息的过程,Kafka确保了
exactly once, 但如果由于前面producer与broker之间的某种原因导致消息发送重复,那就是at least once - 当consumer读完消息之后先commit再处理消息,如果consumer在commit后还没来得及处理消息就宕机了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,就对应于
at most once,即可能存在消息没有消费的情形 - 读完消息先处理再commit,如果处理完了消息在commit之前consumer crash了,下次重新开始工作时还会处理刚刚未commit的消息,实际上该消息已经被处理过了,这就对应于
at least once,即消息被重复消费 - 要做到
exactly once就要引入消息去重机制,即先生产者发送消息时为消息指定一个全局唯一的id,就算重复发送了消息,消费者消费信息时可以通过判断id对应的消息是否被消费过了 && 消息消费之后保存该全局id,从而来保证消息只被消费一次