1.创建数据库
标准语法:
CREATE DATABASE [IF NOT EXISTS] db_name [create _specification]
create _specification:
[DEFAULT] CHARACTER SET=charset_name
[DEFAULT] COLLATE collation_name
说明:
- 大写的表示关键字,关键字可大写可小写。
- [ ]表示可选项,里面的内容可写可不写。
- CHARACTER SET :指定数据库采用的字符集。
- COLLATE:指定数据库字符集的校验规则。
使用案例
- 创建一个数据库
create database db1;
当创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,默认校验规则utf8_general_ci
- 创建一个utf8字符集,并带校验规则的db2数据库
create database db2 charset=utf8 collate utf8_general_ci;
2.字符集和校验规则
2.1 字符集和校验规则是什么?
字符集:
字符的二进制编码方式
二进制编码到一套字符的映射
二进制->编码->字
UTF-8:不一定是3字节,前面是0-1字节,10-2字节,110-3字节。在中文里,全设置为3字节,即在数据库里一个UTF-8占了3字节。
说白了字符集可以控制是用什么语言,utf8,就可以使用中文。
校验规则:
是在字符集内用于比较字符的一套规则,即字符集的排序规则。
不区分的大小写:utf8_general_ci
区分大小写:utf8_bin
MySQL可以使用对种字符集和检验规则来组织字符。
2.2 查看系统默认字符集以及校验规则
show variables like 'character_set_database';
show variables like 'collation_dadatbse';
这里为了方面,接下来我都以我的helloworld库为例,查找结果如下:


2.3 查看数据库支持的字符集
show charset;
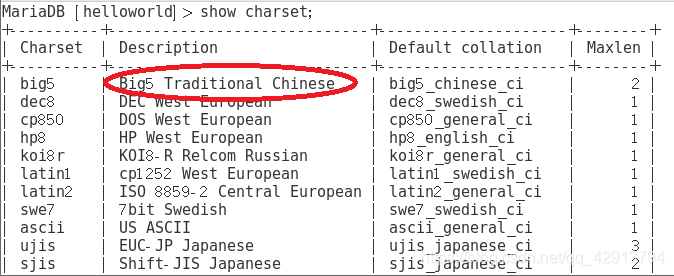
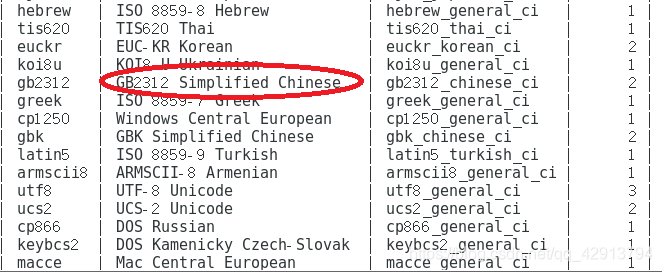
说明:圈出来的两个字符集:BIG5,这个是汉字编码的繁体字符集。还有一个GB是简体的字符集。
2.4 查看数据库支持的校验规则
show collation;
这里就不一一截图了,我们可以找到utf8_general_ci规则:
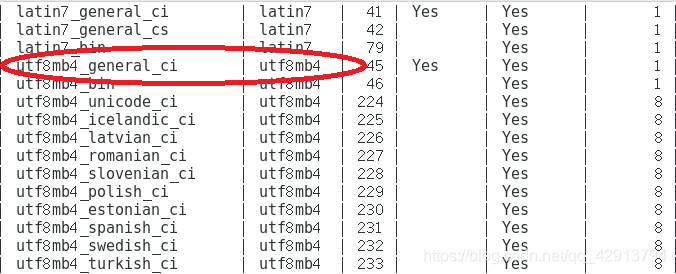
2.5 校验规则对数据库的影响

- utf8_general_ci:不区分大小写
创建一个数据库test1,校验规则使用utf8_general_ci,然后往里面插入一些大写小写字母。操作如下:
create database test1 collate utf8_general_ci;
use test1;
create table person(name varchar(20));
insert into person values('a');
insert into person values('A');
insert into person values('b');
insert into person values('B');
插入后结果如下:
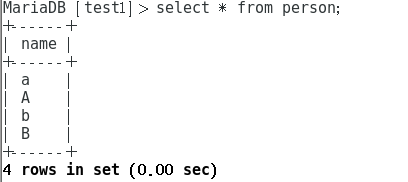
- 区分大小写:uft8_bin
创建一个数据库test2,校验规则使用utf8_bin,插入上述同样的字母。
create database test2
use test2;
create table person(name varchar(20));
insert into person values('a');
insert into person values('A');
insert into person values('b');
insert into person values('B');
插入后结果如下:
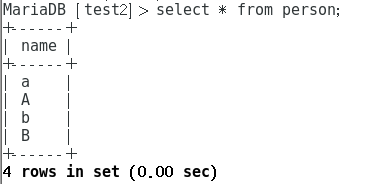
- 对于两个不同校验规则数据库的查询结果
对于test1:

对于test2:
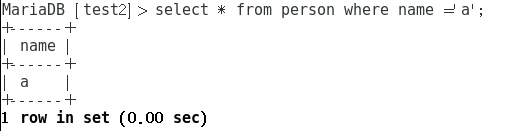
3.操作数据库
3.1 查看数据库
show databases;
不管你此时身在那个库里,都可以直接使用这条语句查看所有的库。

3.2 显示创建语句
show create database +数据库名;
这个语句可以使你查看到你原来创建这个库的方式(数据库名与字符集)。那么我就来展示一下刚刚创建的test1库的创建过程:

说明
- 数据库名的反引号’ ',是为了数据库的名字刚与关键字相同。
- /*40100 DEFAULT… */ 表示如果当前mysql版本大于4.01版本,就执行这句话。不是注释功能。
3.3 修改数据库
对数据库的修改主要指的是修改数据库的字符集和校验规则。
标准语法:
alter database db_name [alter_spacification];
alter_spacification:
[DEFAULT] CHARACTER SET=charset_name
[DEFAULT] COLLATE collation_name
使用案例:
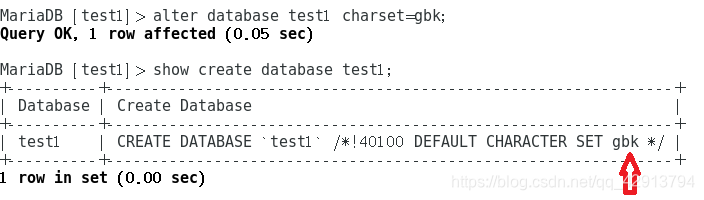
- 将test1数据库的字符集改成gbk
alter database test1 charset=gbk;
我们可以很明显地看到,此时test1的字符集已经变成了gbk。
- 将test1的字符校验规则改成区分大小写的字符集:utf8_bin
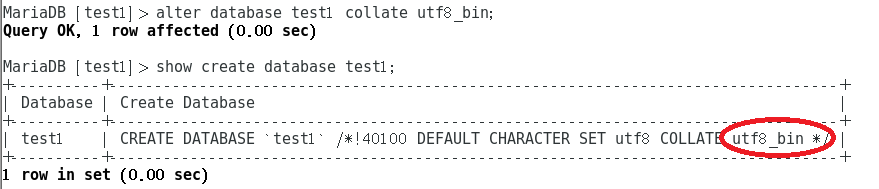
alter database test1 collate utf8_bin;
结果也显而见之。
- 一些探索
那么我想回过头来看看test1库修改校验规则后,之前创建的表person里面的select结果会不会不一样呢?我们来测试一下。

结果竟然是没有,所以person表所使用的校验规则并没有改变。那么试试创建一个新表看看它的校验规则是怎样?
在这里我创建了一张新表person1,并插入和person相同的四组元素。

显而易见,在test1修改为区分大小写的校验规则后,新创建的person1表才开始使用这个新的校验规则。
结论:当修改数据库的校验规则时,对之前已经建立的表没有影响,只对后面重新建立的表才有影响。
3.3 删除数据库
drop database[IF_EXITS]db_name;
删除结果:
- 数据库内看不到对应的数据库。
- 对应的数据库文件、级联、里面的数据都将全部删除。
所以不要随意删库跑路:)
3.4 备份和恢复
备份(前提是退出MariDB连接)
mysqldump -p3306 -u root -p +密码 -B +数据库名称 > 数据库备份存储的文件路径//-p3306可省略
实例:将test1库备份到文件
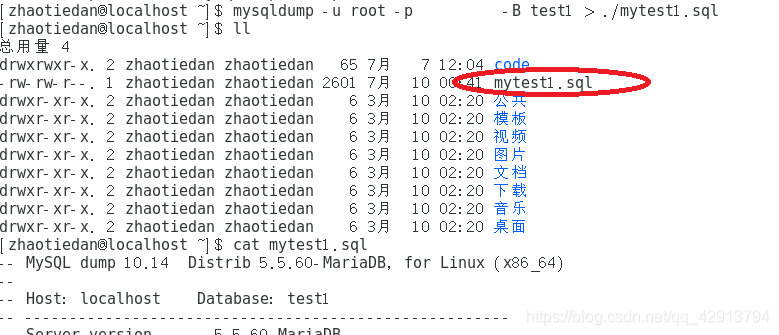
mysqldump -u root -p******* -B test1 > ./mytest1.sql
我们可以看到在目录下已经生成了备份的mytest.sql文件,可以使用cat 查看内容(包含了整个创建数据库,建表,导入数据的所有语句)。
还原
mysql> source mytest1.sql;
3.5 查看连接情况
show processlist;
这个语句的作用是可以告诉我当前有哪些用户连接到了我的MySQL,如果有不认识的用户,那么我的数据库就有可能被入侵了。当数据库运行比较慢时,可以试试用用这招。
