视图:
定义:是一张虚拟的表,有字段和数据,只存放查询语句,视图基于源表
特点:
简单:视图构建了一个虚拟的表,表里的数据是来源于复杂的查询语句,我们将复杂的查询语句存入视图,使用时直接调用视图
安全:数据库有对库和表的权限管理,但是没有对字段权限,可以通过视图来实现权限的功能
数据的独立性:
视图基于源表,当源表的结构发生变化时,不会对视图产生影响
使用视图时,一般存的都是复杂的查询,如果存的是简单的查询,在使用视图时,会作为复杂查询来执行,会降低查询效率
会增加数据库的维护和管理成本,会对数据迁移造成很大影响
原students表
创建视图stu_view:create view 视图名 as(查询语句);

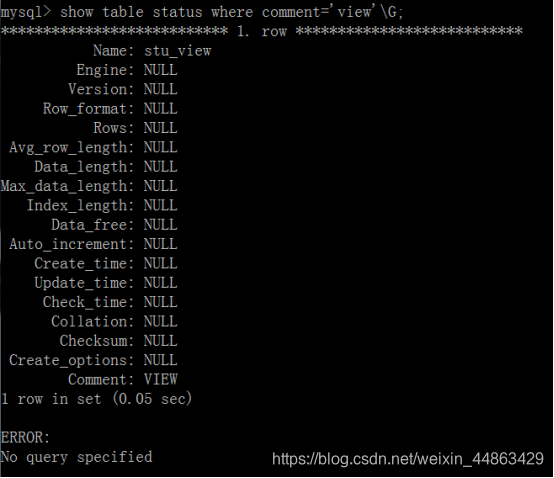
查看视图:show table status where comment=’view’\G;
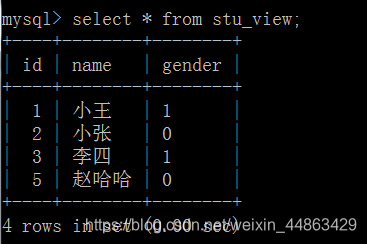
查询:select * from stu_view;
删除视图:drop view stu_view;

没了

触发器:
trigger
由谁触发:触发器是一个特殊的存储过程,不需要手动触发
什么时候触发:当我们在做添加、删除、修改操作时会自动触发触发器
修改结束符
数据备份:
原表
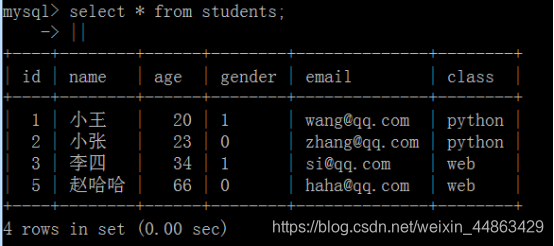
创建个新表存储要删除的内容

创建触发器

删除原表中的数据

删除后原表
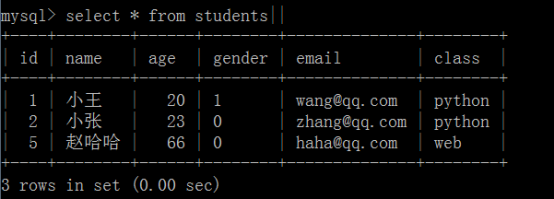
执行触发器后的stu
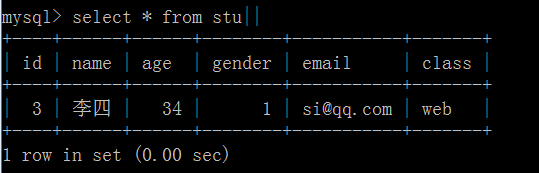
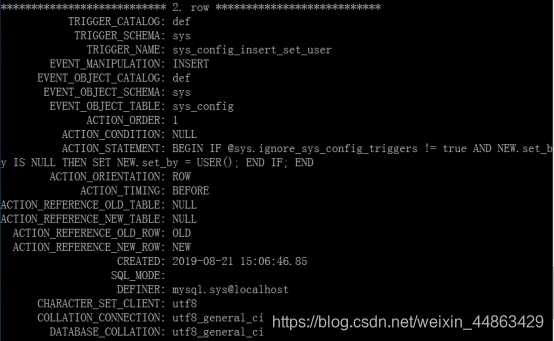
查询触发器

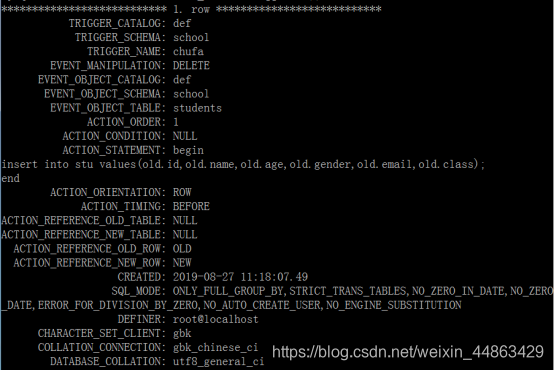
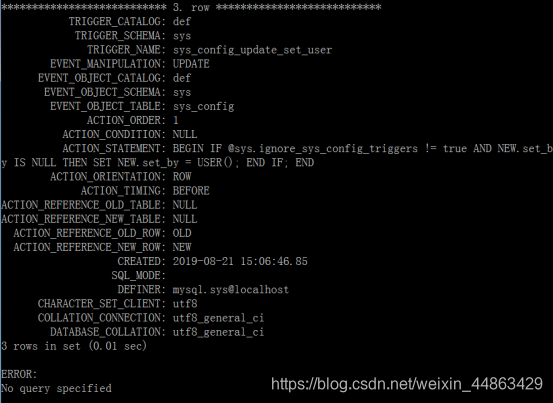
改回结束符
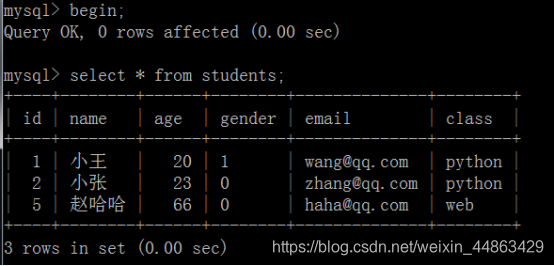
事务的基本操作:
begin 开启一个事务
commit 提交事务
rollback 回滚
Begin后原表
删除后
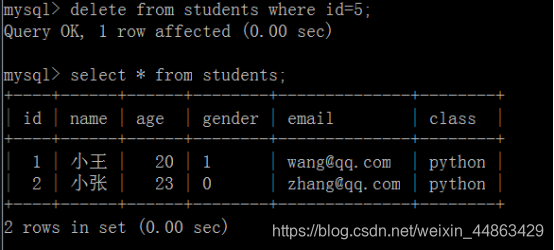
打开另一个mysql
查询students
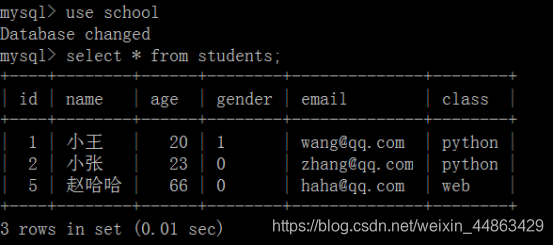
回滚rollback;

回滚后的students
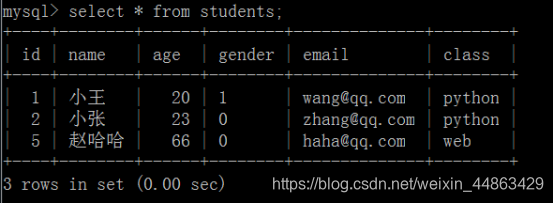
提交commit
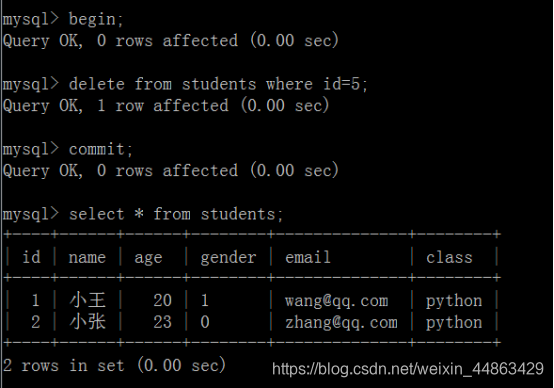
开始后修改数据
另一个mysql无法提交:

当我提交后,另一个数据库立马执行:

两个都是修改后的数据:

ORM:
Pymysql:是一个第三方的模块,并且要求你的python版本为3.5以上
Python2中使用的是 mysqldb
安装: pip install pymysql
使用:
1.连接数据库
2.创建游标
3.定义sql语句
4.执行sql语句
5.关闭连接
获取返回内容的方法:
fetchone() 获取一条数据
fetchall() 获取返回的所有的数据
rowcount 属性 获取操作影响的行数
查询所有的数据session.query(类名).all()
条件查询
session.query(类名).filter_by(name='').all()
session.query(类名).filter_by(name='').first()
session.query(类名).filter(类名.name=='').all()
根据主键查询session.query(类名).get(主键的值)
删除session.delete(数据对象)

添加数据
user = User(name=,age=)
session.add(user)
session.commit()
session.add_all([
user1,user2,user3,User(name=,age=)
])
session.commit()
#导包
import pymysql
#1.连接数据库
db=pymysql.connect(host='localhost', user='root', password="123456",database='lianxi',cursorclass=pymysql.cursors.DictCursor)
# 2.创建游标对象
cursor=db.cursor()
# 3.定义sql语句
# sql='select version()'
#定义查询语句
# sql='select * from user'
# 定义添加数据数据
# sql = 'insert into user(id,name) values(12,"哈哈")'
# 删除数据
sql = "delete from user where name='明明'"
# 4.执行sql语句
cursor.execute(sql)
#获取返回结果
print(cursor.fetchone())
print(cursor.fetchall())
print(cursor.rowcount)
# 如果操作对数据中的数据产生了影响必须提交
db.commit()
# 5.断开连接
cursor.close()
db.close()
import pymysql
class MyDB:
def __init__(self,h='localhost',u='root',p=None,db=None):
# 连接数据库 创建游标对象
# host 主机的ip地址
# user 数据库的用户名
# password 数据库的密码
# database 是定要操作的数据库
# cursorclass 指定返回的数据格式,默认返回元组
self.db = pymysql.connect(host=h,user=u,password=p,database=db,cursorclass=pymysql.cursors.DictCursor)
# 创建游标,所有的操作都要通过此对象
self.cursor = self.db.cursor()
# 查询
def query(self,sql):
# 调用游标对象中的execute 执行sql语句
self.cursor.execute(sql)
# 将查询到的数据进行返回
return self.cursor.fetchall()
# 添加、删除、修改
def change(self,sql):
self.cursor.execute(sql)
# 如果对数据的数据做修改,必须commit
self.db.commit()
# 返回数据操作影响的行
return self.cursor.rowcount
def __del__(self):
# 关闭数据库连接
self.cursor.close()
self.db.close()
if __name__ == '__main__': # 主进程的入口,一般用于测试
# 实例化对象
database = MyDB()
res = database.query('select * from user')
print(res)
from mydb import MyDB
# 实例化数据库对象
database = MyDB(h='localhost', u='root',p='123456',db='school')
# 插入数据
sql = 'insert into students(id,name) values(20,"佳佳")'
print(database.change(sql))
# 定义sql语句
sql = 'select * from students'
print(database.query(sql))
import sqlalchemy
from sqlalchemy.ext.declarative import declarative_base
# 类似于mymysql中的游标
from sqlalchemy.orm import sessionmaker
# 1.创建连接
# 数据库类型+数据库操作的包://用户名:密码@主机地址/你要操作的数据库
#mysql://scott:tiger@hostname/dbname
db =sqlalchemy.create_engine('mysql://root:123456@localhost/sqlorm')
# 2.创建基类
base = declarative_base(db)
# 3.创建类,必须继承基类,创建模型
class User(base):
# 表名
__tablename__='user'
id = sqlalchemy.Column(sqlalchemy.Integer,primary_key=True)
name = sqlalchemy.Column(sqlalchemy.String(32))#varchar()
age = sqlalchemy.Column(sqlalchemy.Integer)
class Userinfo(base):
__tablename__ = 'userinfo'
id = sqlalchemy.Column(sqlalchemy.Integer,primary_key=True)
phone = sqlalchemy.Column(sqlalchemy.String(20))
class Shop(base):
__tablename__='shop'
id = sqlalchemy.Column(sqlalchemy.Integer,primary_key=True)
name = sqlalchemy.Column(sqlalchemy.String(32))
if __name__ == '__main__':
# 执行数据库迁移,创建表
base.metadata.create_all(db)
# 绑定一个实例
s = sessionmaker(bind=db)
# 创建回话对象,类似于游标
session = s()
# # 添加
# user = User(name='hello',age=16)
# session.add(user)
# session.commit()
# session.add_all([
# User(name='world',age=1),
# User(name='python',age=28),
# User(name='PHP', age=30),
# ])
# session.commit()
# 查询
# 查询所有的数据 返回一个列表
# res = session.query(User).all()
# for i in res:
# print(i.name,i.age)
# 通过主键查询一条数据 返回一个对象
# res = session.query(User).get(2) # get(值),通过主键对应的值进行查询
# print(res.name,res.age)
# 条件查询 返回的是一个列表
# res = session.query(User).filter_by(name='world').all()
# print(res)
# res = session.query(User).filter(User.name=='hello').all()
# print(res)
# 修改数据
res = session.query(User).get(2)
print(res.name)
res.name='HELLO'
session.commit()
# 删除数据
# res = session.query(User).get(1)
# session.delete(res)
# session.commit()
数据库分类
关系型数据库的三大范式
- 第一范式(1NF):要求数据库表的每一列都是不可分割的原子数据项
- 第二范式(2NF):在1NF的基础上,非码属性(非主键)必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖)
- 第三范式(3NF):在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
反三范式:允许部分字段冗余
三范式:只是设计表时的一个参考规则,实际表的设计要根据实际业务设计
数据库优化
库和表结构化
分库分表:当单个库或者表中的数据量大时,数据库的性能会变慢
垂直拆分
- 垂直拆分表:当一个表中 的数据量比较大字段,比较多时,创建一个附属表,将表中不常用的字段存入附属表,同过创建外键进行关联
- 垂直拆分库:根据不同的业务需求,将不同的表放入不同的库中,一般会放到多个服务器上
水平拆分
- 水平分库分表:单表数据量太大,将数据水平拆分成多个表,多个表组合在一起才能组成一个完成的数据
- 将拆分的表放到不同的库中
水平拆分面临的问题:主键如何保证唯一性
- 指定每张比表的id取值范围
- 通过时间或者地理位置
- 通过趋势递增
架构优化:主从复制(读写分离),添加缓存,一般使用非关系数据库作为缓存数据库,将数据存到内存中
sql语句的优化:允许部分字段冗余,使用逻辑外键,避免使用物理外键
添加索引:给查询频繁的条件添加缩影,使用索引最左原则
查询时select后面不使用*
减少数据库的查询次数
sql关键字尽量大写
使用关联查询替代嵌套子查询
使用where条件过滤,避免全表查询
update修改时,避免修改索引字段所在的列
避免修改where后面字段