一、数据库的基本操作
- 查看当前所有存在的数据库
show databases; //mysql 中不区分大小写。(databank 是之前创建的)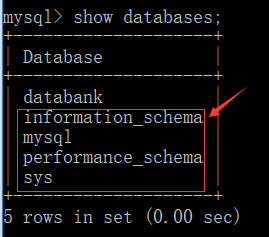
- 创建数据库
create database database_name; //database_name 为新建的数据库的名称,该名称不能与已经存在的数据库重名如:创建一个名为 test_db 的数据库

查看数据库 test_db 的定义:
show create database test_db\G //将会显示数据库的创建信息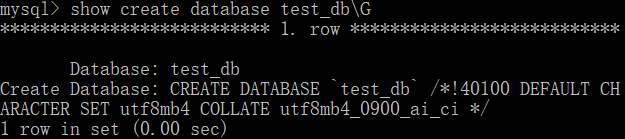
- 使用数据库
use database_name;如:使用数据库 test_db

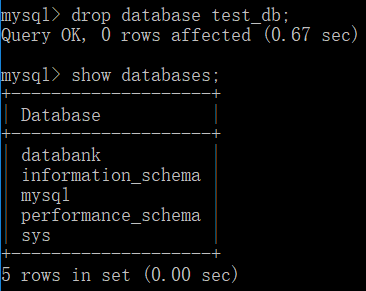
- 删除数据库
如:删除数据库 test_db
drop database database_name;
二、数据表的基本操作(以 stu 表为例)
- 创建数据表
create table stu( id int(11) primary key auto_increment, //主键 id, id 值自动增加 name varchar(22) not null, //非空 salary float default 1000.00); //默认值为 1000.00 - 查看数据表结构
desc table_name; //describle table_name; 查看表的基本结构
show create table table_name\G //查看表的详细结构
-
修改数据表
alter table table_oldname rename [to] table_newname; //修改表名。 to 为可选参数,使用与否均不影响结果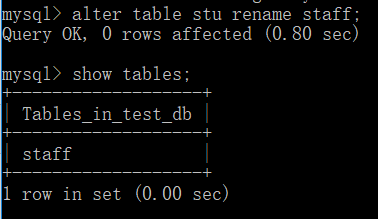
alter table table_name modify <字段名> <数据类型>; //修改字段的数据类型。 '表名' 是当前所在表, '字段名' 是目标修改字段, '数据类型' 是新数据类型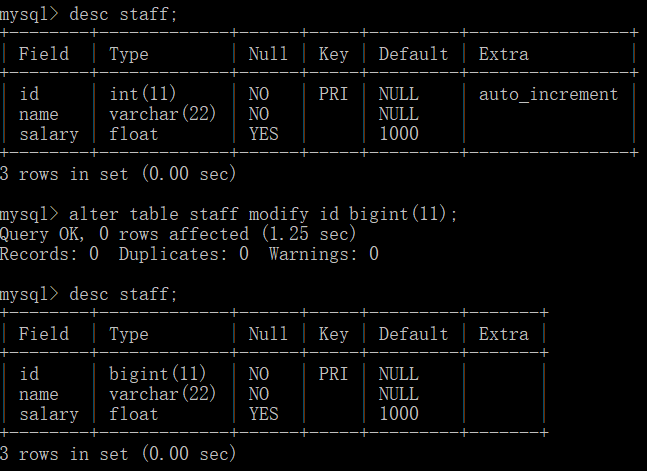
修改字段名
alter table table_name change <旧字段名> <新字段名> <新数据类型>; //修改字段名。 如不需要修改字段的数据类型,须将新数据类型设置成和原来一样。添加字段
alter table table_name add <新字段名> <数据类型> [约束条件] [first | after 已存在的字段名]; //添加字段 如: alter table staff add address varchar(55); //无约束条件 alter table staff add address varchar(55) not null; //有约束条件(要求非空) alter table staff add address varchar(55) first; //成为表的第一列 alter table staff add address varchar(55) after name; //在表的某一列之后删除字段
alter table table_name drop <字段名>; //删除字段修改字段的排列位置
alter table table_name modify <字段1> <数据类型> first | after <字段2>; //修改字段的排列位置。 '数据类型' 是指 '字段1' 的数据类型 如: alter table staff modify adress varchar(55) first; //修改字段为表的第一个字段 alter table staff modify adress varchar(55) after id; // 'adress' 字段将移至表的 'id' 字段之后 - 删除数据表
drop table table_name; //无关联的表
三、插入、更新与删除数据
- 表中插入数据
insert into table_name (column_list) values (value_list); 如: //建表 create table staff( id int(11) primary key auto_increment, name varchar(22) not null, salary float default 1000); //为所有字段插入数据 insert into staff(id,name,salary) values(1,'Joan',2000),values(2,'Qwe',900);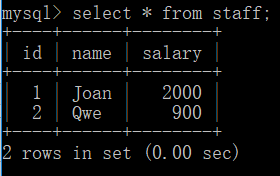
//为表的指定字段插入数据 insert into staff(id,name) values(3,'Wer'),(4,'于玉'); //salary 取默认值 insert into staff(name,salary) values('Tin',2048),('Jimy',1024); //id 值自动增加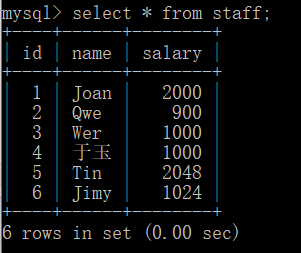
-
复制表
create table table_new select * from table_old; //全部复制(表的结构会改变) create table table_new select (column_list) from table_old; //部分复制 如: create table newstaff select * from staff; create table newstaff select id,salary from staff;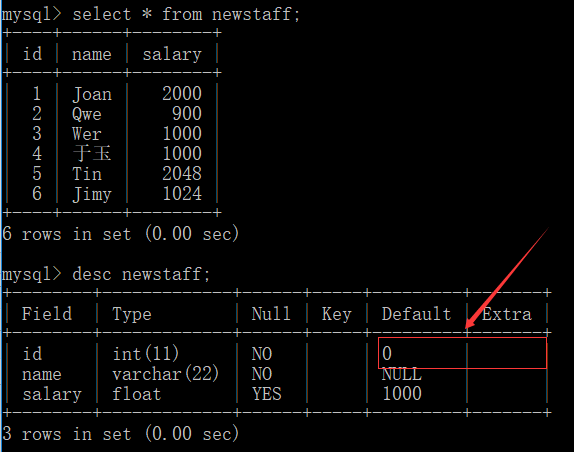
-
表中删除数据
delete from table_name [where <condition>]; //删除指定记录 delete from table_name; //删除表中所有记录 - 表中更新数据
update table_name set column_name1=values1,... [where <condition>]; //修改指定字段的值 如: update staff set salary=2048 where id=9; update staff set salary=1024 where id between 5 and 9; -
表中查询数据
单表查询
//单表查询 select * from staff; //(*)查询所有字段数据 select 字段名1,字段名2,...字段名n from table_name; //查询指定字段数据(某几列) select 字段名1,字段名2,...字段名n from table_name where 条件; //查询指定记录where 条件判断符
操作符
说明
= 相等
<> , != 不相等
< 小于
<= 小于或者等于
> 大于
>= 大于或者等于
between 位于两者之间
//带 in 关键字的查询 select * from staff where id in(1,2,8); //id=1、id=2、id=8 select * from staff where id not in(1,2,8); //带 between and 的范围查询 select * from staff where id between 1 and 8; //id-->1至8 的记录 select * from staff where id not between 1 and 8; //id-->1至8 以外的记录 //带 like 的字符匹配查询 select * from staff where name like 't%'; //查询所有名字以 t 开头的记录 select * from staff where name like '%t%'; //查询所有名字中包括 t 的记录 select * from staff where name like 't%y'; //查询所有名字以 t 开头并以 y 结尾的记录 select * from staff where name like '___y'; //查询所有名字以 y 结尾并且前面只有三个字符的记录 //查询空值 select * from staff where salary is null; //查询字段 salary 的值为空的记录 //带 and、or 的多条件查询 select * from staff where id=1 and salary>=1000; //查询结果不重复 select distinct 字段名 from 表名; //distinct 关键字可以消除重复的记录值对查询结果排序
//order by 默认情况下,升序排 select * from staff order by salary [asc]; select * from staff order by salary desc; //降序排 //group by 该关键字常和集合函数一起用,如: MAX()、MIN()、COUNT()、SUM()、AVG() [group by 字段] [having <条件表达式>] //基本语法格式 如:根据 salary 对 staff 表中的数据进行分组,并显示人员数大于等于1的分组信息 select salary,group_concat(name) as names from staff group by salary having count(name)>=1; select salary,count(*) as total_num from staff group by salary with rollup; //with rollup 关键字用来统计记录数量 select * from staff group by salary,name; //多字段分组 //group by + order by select name, sum(2*salary) as salary_total from staff group by salary having sum(2*salary)>2000 order by salary_total; //使用 limit 限制查询结果的数量 limit [位置偏移量,] 行数 //基本语法格式 select * from staff limit 4; //从第一行开始显示,显示共四行 select * from staff limit 4,4; //从第5行开始显示,显示共四行使用集合函数查询
// count() 函数 count(*) 计算表中行的总数,不管某列值是否为空 count(字段名) 计算指定列下总的行数,空值的行不被记录 select count(*) as total_num from staff; select count(salary) as salary_num from staff; // sum()函数。计算时忽略值为 NULL 的行 select sum(salary) as salary_total from staff; // avg()函数 select avg(salary) as avg_salary from staff; // max()函数、min()函数。以 max 为例 select max(salary) as max_salary from staff; select name,max(salary) as max_salary from staff;