第三章 游戏软件工程基础
本书的第三章以C++为例,主要讲解了面向对象编程的基础概念,涉及C++的面向对象特性以及一些底层的原理等等。
同样列出本章大致的知识框架,列出一些需要注意的知识点:
· 重温C++及最佳实践
· 面向对象
· 多重继承
· 菱形继承问题
· 可使用虚继承,大多数C++软件开发者都会完全避免多重继承
· 可以只容许单继承层次结构中多重继承一些简单且无父的类
· 合成和聚合
· 合成:has a
· 聚合:use a
· 编码标准
· C/C++的数据、代码及内存
· 数值表达形式
· 定点记法
· 同时限制了可表示整数部分的范围及小数部分的精度
· 浮点记法
· 范围和精度的取舍
· 基本数据类型
· SIMD类型
· 可移植的特定大小类型
· 多数游戏引擎会定义自定的基本数据类型
· 多字节值及字节序
· 微处理器
· 小端:最低有效字节存于较低的内存位置
· 大端:最高有效字节存于较低的内存位置
· 字节序转换
· 声明、定义及链接规范
· 翻译单元
· 链接器链接外部引用
· 找不到extern引用的目标:“无法解决的外部符号”
· 找到两个或以上同名实体:“符号被多重定义”
· 声明与定义
· 声明是实体的引用,定义是实体本身
· 多重声明和定义
· 两个同等定义位于一个翻译单元时,编译器报告同名实体错误
· 两个同等定义位于不同翻译单元时,链接器报告“符号被多重定义”
· 头文件中的定义,以及内联
· 内联函数必须置于头文件中
· 链接规范
· 外部链接的定义可以被定义处以外的翻译单元看见并引用
· 内部链接的定义只能被该定义处的翻译单元看见,不能被其他翻译单元引用
· 所有定义预设为外部链接,使用static关键字可以把定义改为内部链接
· C/C++内存布局
· 可执行映像
· 可执行文件总是包含程序的部分映像
· 程序除了把可执行映像置于内存中,一般也会分配额外内存
· 映像文件的组成
· 代码段:包含程序定义的全部函数的可执行机器码
· 数据段:包含全部获初始化的全局及静态变量
· BSS段:包含所有未初始化全局变量和静态变量
· 只读数据段:包含所有只读全局变量
· 编译器通常把整数常量视为明示常量,插进机器码之中,占用代码段储存空间
· 程序堆栈
· 调用函数时,一块连续的内存会压入栈,此内存块称为堆栈帧
· 堆栈帧储存3类数据
· 调用函数的返回地址
· 相关CPU寄存器的内容
· 函数里的所有局部变量
· 动态分配的堆
· 成员变量
· 类的静态成员
· static用于class声明时,不控制该变量的可见性
· 类声明内的类静态变量不占内存,必须于一个.cpp文件内定义类静态变量分配内存
· 对象的内存布局
· 对齐和包裹
· 数据对象的对齐是指,其内存地址是否为对齐字节大小的倍数
· 现在许多处理器实际上只能正常地读/写已对齐的数据块
· 小成员组合在一起,包裹更高效
· 末端字节填充
· 使结构作为数组类型时仍能正确对齐
· C++中类的布局
· 继承与虚函数
· 当B类派生于A类,内存里B类的数据成员会紧接A类数据成员之后
· 当类含有或继承一个或多个虚函数
· 类的布局最前端里添加4字节虚表指针
· 类的每个实例都会有虚表指针
· 每个类含有一个虚函数表
· 虚函数表包含该类声明或继承而来的所有虚函数指针
· 捕捉及处理错误
· 错误类型
· 用户错误、程序员错误
· 二者界限的区分
· 错误的处理
· 处理玩家、开发者、程序员的错误
· 实现错误检测及处理
· 错误返回码
· 异常
· 断言
· 断言通常实现为一个宏,在if/else语句里对表达式求值
然后是一些自己对文章知识点的理解:
1.关于多重继承:
文中提到在大多数C++的开发中会避免使用多重继承,但容许从一个单继承层次结构中多重继承一些简单且无父的类。个人认为可以用“接口”来理解这种情况:如图,Animator作为一个接口类型,没有成员变量,只有成员函数作为接口,这些函数应为空的函数或纯虚函数,而它的派生类则需要实现这些接口(即重写这些函数)。C++不像Java有接口的概念,但可以通过类的继承实现类似的功能,就如本例的Animator类一样。那么为什么要重新定义一个Animator类呢?而不是直接在Shape类里面进行扩展呢?个人认为有两个可能:一是除了Shape类外还有其他的类也需要实现这些接口;二是避免Shape类职责太多而变得臃肿,是出于设计模式方面的考虑。
2.关于合成和聚合:
合成和聚合都是描述类与类之间的关系的,但是它们之间比较容易混淆。如书上提到,合成在类之间是“有一个”的关系,而聚合在类之间则是“用一个”的关系。它们之间的区别在于,合成关系要求两个类具有相同的生命周期,“整体”不存在了,“个体”也不能存在;而在聚合中个体是可以独立于整体存在的。二者之间的区别或许可以通过C++代码的具体实现来理解:合成一般表现为一个类含有另一个类的成员变量,聚合一般表现为一个类含有另一个类的指针。
3.关于浮点数:
都知道浮点数是用来存储小数或者无理数的,但至于它存储数据的具体细节就不一定有很多人了解了。浮点数由符号位(1位)、指数位(8位)、尾数位(23位)组成,可以这样理解浮点数:无论这个浮点数有多大(或多小),它的“有效数字”范围都是一样的,因为浮点数的尾数位是固定的,至于它有多大(多小),由指数位控制。除此之外,浮点数的指数位设为0或255有什么特殊含义,还有浮点数的非规约形式是什么,都是需要了解的。
4.关于字节序转换:
书中提到有时因为一些“硬件”方面的原因,需要进行字节序的转换,比如对一个四字节大小的U32类型进行字节序转换:
如图,每次用对应的掩码与原值进行位并操作,取得每个字节的内容,再把字节移动到“相反”的位置即可
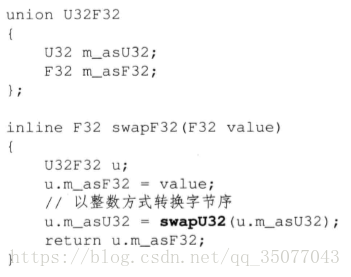
浮点数字节序转换则需要先转换为整数:
如图,使用union实现类型的转换。union是C++的一个不太常用的关键字,其作用和struct类似,但一个主要的区别是union的数据成员共享一块内存区域,因此可以用来做类型转换(union如果用的好的话也可以最大化内存的利用率,起到节约内存的作用)。注意这里的类型转换不改变任何字节的数据,和C++的强制类型转换什么的是不一样的。
5.关于外部引用:
注意"extern"关键字修饰的变量是变量本身引用其他翻译单元的,而不是提供给其他翻译单元引用的!这里不知道为什么老是记不清。
最后整理一些还存在的疑问:
1.浮点数字节序转换的时候为什么不能像整数那样,直接用位运算来做呢?而是先转换为整数?书中也提到:“字节始终是字节”。
2.书中提到,编写C++程序时,在.h文件中写函数声明和内联函数的定义,在.cpp文件中写非内联函数的定义,这没有问题。但根据我写C++的经验,编写模板类的时候所有函数(包括声明和定义)都必须写在.h文件中,如果把函数的定义写在.cpp文件中则会报错。C++的一般类和模板类有什么不一样的地方导致了这样的区别?
3.书中提到了内存对齐,即数据对象的内存地址是否为对齐字节大小的倍数,对齐字节大小一般为2的幂。那么假如我编写了一个C++类,类的大小不为2的幂,程序为该类的对象分配内存的时候会不会考虑内存对齐呢?如果会,怎么对齐?
4.继承与虚函数:文中提到含虚函数的类的实例都有一个虚表指针,指向该类对应的虚函数表,虚函数表又有指向函数的指针。虚表指针存储在每一个类的实例中,但是虚函数表一般存在内存的什么位置?虚函数表指向的函数呢?