引言
本文介绍线性回归算法。
它主要解决回归问题,思想简单,实现容易;
是很多强大的非线性模型的基础;
它的结果具有很好的可解释性。
我们在机器学习基础概念中说过,如果结果是一个连续数值,而不是一个类别的话, 那么就是回归问题。回顾问题要预测的是具体的数值,通常这些数值在一个连续的空间里面。今天我们学习的线性回归算法就是一个最简单的回归算法。
线性回归算法
假设我们有房屋面积和房屋价格的一些数据。每个房屋有自己的面积,和价格。
我们把它们画到二维平面上。

线性回归算法认为房屋价格和面积具有一定的线性关系。也就是说随着面积的增大,价格也会增加,并且增大的趋势是线性的。
两个变量之间存在一次方函数关系,就称它们之间存在线性关系
在这种假设下,我们希望能找到一条直线,能最大程度的拟合样本特征和样本输出标记之间的关系。
拟合就是把平面上一系列的点,用一条光滑的曲线连接起来。

比如找到这样一条直线,有了这条直线之后,我们拿到一个新的房屋面积,就可以预测它对应的房屋价格。

这里的房屋面积是特征;价格就是输出标记了。这和上篇文章介绍的分类问题不同。在分类问题中,两个轴代表特征,而样本的颜色代表所属的类别。
我们本文主要介绍的线性回归都只有一个特征,加上输出标记刚好可以在二维平面中可视化表示。
这种只有一个特征的线性回归,可称为简单线性回归。在我们学会了简单线性回归问题后,可以更好的理解多个样本特征的线性回归问题(多元线性回归)。
回到简单线性回归问题。

我们想要找一条直线能最大程度拟合样本点,二维平面中的直线方程可以表示为
。
每一个点对应了一个样本特征 ,表示第 个数据点。我通常习惯不加括号的形式。该样本特征点对应的输出标记记为 。
如果我们找到了一条这样的直线,也就是找到了 的取值,那么我们就可以把 代入这个方程,此时会得到一个值,记为 。即

对应到图中就是红点所在的位置,一般我们预测的结果很难刚好等于真实结果的。因此,它们之间会有一个差值。
我们想要寻找最佳拟合的直线,就是希望真实值 和我们的预测值 它们的差距尽可能小
那我们如何用数学式子表示它们的差距呢?很容易想到的是做减法:
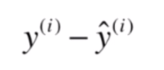
但是这样得到的结果可能有正有负,如果不加处理的话,直接把这些结果加起来,可能正负抵消最终得到差距为0。这显然是不合理的。
因此一般可以想到的是加个绝对值。
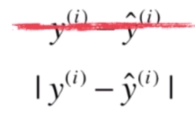
但是绝对值是不好求导的,我们后面需要通过计算导数等于0的点来求得极值点。
另一种替代的方法是加上括号的平方:
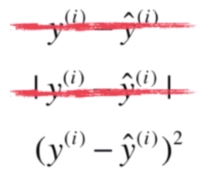
这样不仅可以处理差值为负的情况,这个函数还是一个处处可导的函数。
如果我们考虑所有样本的话,就是将它们的差距累加起来:
那么我们的目标是使上面这个式子尽可能的小。这里 的,代入上面的式子得:
现在需要找到 和 ,使得 尽可能小。
注意这个式子里面的未知数是 和 ,而不是我们常见的 ,这里的 和 都是已经确定的训练数据或测试数据。
我们现在要做的是找到一个组参数值,使得 这个函数尽可能的小,这是典型的一种机器学习的推导思路。
这里我们称这个函数为损失函数(loss function或cost function)。
这里的损失可以理解为误差或错误。损失越小也就是错误越小
通过分析问题,确定问题的损失函数;然后最优化损失函数,获得机器学习的模型。
这是机器学习算分的一种思路,几乎所有的参数学习算法都是这样的套路。我们线性回归算法的参数就是这里的 和 。

这是一个典型的最小二乘法(误差相减的平方和)问题。我们通过最小二乘法可以直接求得 和 的表达式,代入数据就可以马上求得具体的 和 。
用最小二乘法来求a和b
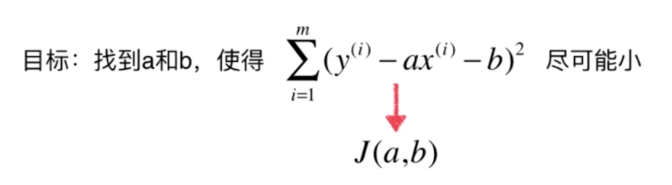
我们这里可以把损失函数记为
,
是我们要求的参数。还有些人记为
这只是名字不同而已。
由高等数学知识(忘了的可以先看下这篇文章,相信很快就可以回忆起来)可知,我们对这个函数求导,并且令导数等于0,在导数等于0的地方就是极值点的地方。
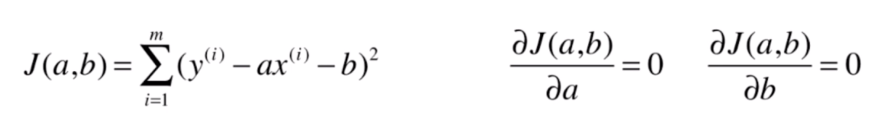
因此这里我们来计算一下损失函数对
的求导后的式子。
先对 求导,利用了链式求导法则,并且对 求导时,将 看作常数( 当然也是常数):
我们令导数 即
两边同除以 得:
我们把求和函数拿出来得到:
又 中 是和 无关的常数,相当于 个 累加,即 。
因此上面按个式子可以写成:
我们把 移到等式右边,整理下得:
然后我们把等式两边同除以 ,得到
又 就是求 的均值,可记为 ,即 ,对于 也是一样,因此上式可以写成:
我在这里一步一步写出希望大家能看的明白。接下来计算对 的求导。
再对
求导:
同理令其等于0可得:
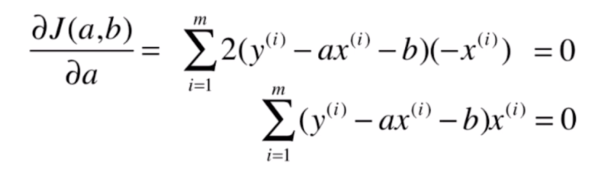
然后我们可以把上面求得的 代入上面这个式子:
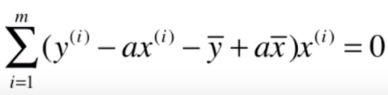
上面这个式子现在还有 这一个未知数,我们整理后就可以得到 的式子了。
我们先把外面的
乘到括号里面得:
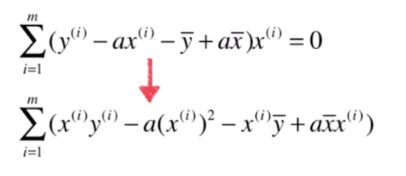
我们变换一下括号里面的顺序,整理一下得:
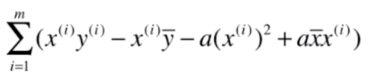
再把前后两项分开:
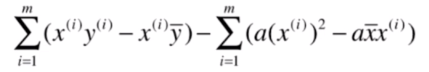
这样包含未知数
的都到了后面这一项,别忘了整个式子是等于0的,因此可以把含
的一项移到等式的右边得:
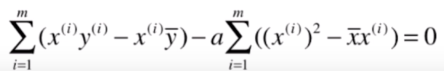
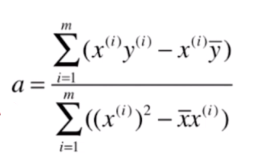
最后我们就得到了
的表达式和
的表达式。此时我们可以通过编写代码的方式根据不同的
求得对应的
。
但是此时我们对这个式子进一步整理的话,可以得到一个更加简洁的表达式,并且可以进行向量化的运算。
我们具体来看如何整理。
把分子上的括号解开:
我们来看下 如何变形:
其实 的均值 是一个常数,我们可以把这个常数提出来
如果把 和 相结合的话,就可以写成
因此,上式又可以写成:
因为 是一个常数,常数放到求和符号左边或右边都可以。
我们看这个式子(上面等式最左边的式子和最右边的式子),相当于将 和 对调了。
另外,从 可以推出
还是因为 和 都是常数。对一个常数求累加,相当于这个常数加了 次。
有了以上的结论,我们对 的表达式进行一些变换。
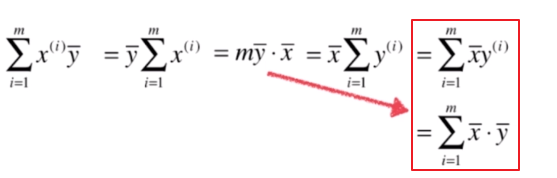
对于分子,因为
;
对于分母,有
接下来这个式子可以简化为:
最终我们得到
和
的简单写法形式

下面就会知道为什么说这种形式是简单形式。
简单线性回归算法的实现
接下来我们实现一下这个最简单的线性回归算法,先构建一些假数据:
import numpy as np
import matplotlib.pyplot as plt
# 先构建一些假数据
x = np.array([1.,2.,3.,4.,5.]) # 浮点数数组
y = np.array([1.,3.,2.,3.,5.])
因为我们这里的 只是一个向量(只有一个特征),所以我们用小写来表示。如果有多个特征的话,就是一个矩阵,我们就会用大写字母表示。
然后我们可视化一下这些数据:
plt.scatter(x,y)
plt.axis([0,6,0,6])
plt.show()

接下来我们通过编程的方式来实现一下这个求解
的公式:
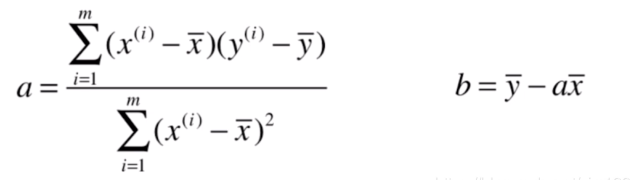
#先计算均值
x_mean = np.mean(x)
y_mean = np.mean(y)
num = 0.0 # numerator 分子
d = 0.0 # denominator 分母
# 先通过循环来求解
for x_i,y_i in zip (x,y):
num += (x_i - x_mean) * (y_i - y_mean)
d += (x_i - x_mean) ** 2
a = num / d
b = y_mean - a * x_mean
print(a,b) # 0.8 0.39999999999999947
这样我们就求得了 的值。
把它们代入公式 画到平面上看下效果:
plt.scatter(x,y)
plt.axis([0,6,0,6])
plt.plot(x,a * x + b,'r-')
plt.show()

这根红色的直线就是我们通过最小二乘法得到的最佳拟合直线。现在我们就可以来进行预测了,假设来了一个新的样本,样本值为 :
x_predict = 6
y_predict = a * x_predict + b
print(y_predict)#5.2
我们就可以得到预测值是 。可能是你朋友有个60平米的房子,你预测的房价是520万。
接下来我们把上述过程封装到一个类中去:
# 最小二乘法实现的
import numpy as np
class SimpleLinearRegression1:
def __init__(self):
self.a_ = None
self.b_ = None
def fit(self,x_train,y_train):
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = 0.0
d = 0.0
# 先通过循环来求解
for x,y in zip (x_train,y_train):
num += (x - x_mean) * (y - y_mean)
d += (x - x_mean) ** 2
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self,x_predict):
return np.array([self._predict(x) for x in x_predict])
def _predict(self,x_single):
return self.a_ * x_single + self.b_
def __repr__(self):
return "SimpleLinearRegression1(a=%s,b=%s)" % (self.a_,self.b_)
接下来使用下我们刚才写的类:

reg1 = SimpleLinearRegression1()
reg1.fit(x,y)
reg1.predict(np.array([x_predict])) # array([5.2])
接下来绘制 下这条直线(其实和上面的是一样的):
y_hat1 = reg1.predict(x) # 这个相当于是y函数
plt.scatter(x,y)
plt.axis([0,6,0,6])
plt.plot(x,y_hat1,'r-')
plt.show()

向量化运算
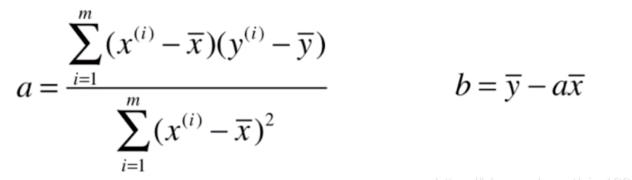
我们上面推导出来的这个公式的目的其实是进行向量化运算的。我们知道向量化运算的效率是远大于循环运算的。
我们改写下 的形式, 的分子和分母都可以看成是两个向量点乘。

下面我们就通过向量运算的形式改写下我们写的线性回归的代码:
# 最小二乘法实现的
import numpy as np
class SimpleLinearRegression2:
def __init__(self):
self.a_ = None
self.b_ = None
def fit(self,x_train,y_train):
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
# 通过向量化运算
num = (x_train - x_mean).dot(y_train - y_mean) #dot是向量点乘,返回的是标量
d = (x_train - x_mean).dot(x_train - x_mean)
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self,x_predict):
return np.array([self._predict(x) for x in x_predict])
def _predict(self,x_single):
return self.a_ * x_single + self.b_
def __repr__(self):
return "SimpleLinearRegression2(a=%s,b=%s)" % (self.a_,self.b_)
改写好了之后,使用方式是一样的:
reg2 = SimpleLinearRegression2()
reg2.fit(x,y)

下面我们用大量的数据来进行性能测试,看向量化的方法究竟提升了多大。
m = 100000 #100W
big_x = np.random.random(size=m)
big_y = big_x * 2.0 + 3.0 + np.random.normal(size = m)
%timeit reg1.fit(big_x,big_y)
%timeit reg2.fit(big_x,big_y)

可以看到它们都能正确算出结果,但使用循环方式的reg1耗时大约1秒;而使用向量化运算的reg2耗时只有18.7毫秒。性能提升有56倍。
我们现在实现出了线性回归算法,但这并不意味着结束。我们还需要评估下算法的表现好不好。
评估线性回归的指标
上篇文章中介绍了在分类问题中可以使用准确度衡量,那在回归问题中使用什么衡量呢。
均方误差
在回归问题中我们的目标是使损失函数尽可能小。
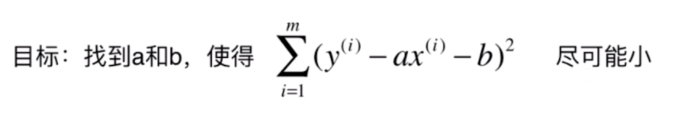
在学习过程中,我们也是需要将数据集分成训练数据和测试数据的。我们要找到 使上面这个式子尽量小,其实是对训练数据来说的。也就是
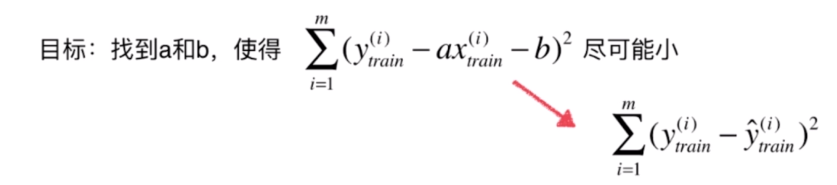
当训练过程结束后,就可以得到
和
,得到了
之后就可以将测试数据集中的每个数据代入,得到相应的预测值。
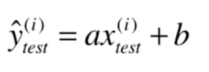
因此我们可以用测试数据集中的实际
值减去预测的
值的平方作为衡量标准:
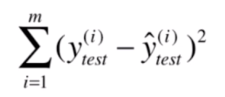
但是这个标准是和 的个数有关的。如果你用了10000个测试数据来进行测试,平均每个的误差只有0.5;但是我只有了2个测试数据来测试,平均误差高达5。
进行求和后显然我的结果会比你的要好一些。因此这里需要对结果进行一个求平均操作:
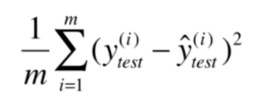
这个标准叫做均方误差(MSE,Mean Squared Error)
但是这个标准还有个小问题,如果对于房价我们预测值是以万元为单位的话,那么这个标准得到的结果的量纲其实是万元的平方。这个量纲有时会给我们带来麻烦,所以改进的方法是对求得的结果进行开平方。
均方根误差
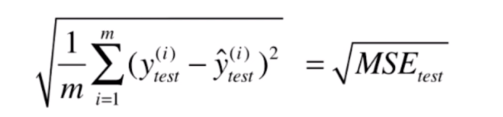
这样就得到了均方根误差(RMSE,Root Mean Squared Error)。
这样求得的结果的量纲和 的量纲是一致的。
平均绝对误差
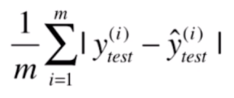
还有一种方法是直接相减并求绝对值的和,最后求均值。这种方法叫平均绝对误差(MAE,Mean Absolute Error)。
这里值得一提的是,这个方法虽然不能当成我们训练时的损失函数,但是测试的时候是可以用的。
也就是说评价算法的标准可以和训练算法的损失函数完全不一致。
下面我们编程来实现这三个标准:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
boston = datasets.load_boston()
我们现在开始用真实数据来学习,这里用的是sklearn中的波士顿房价。

通过DESCR可以看下这份数据的描述。可以看到有506个样本和13个特征。
我们先取一个特征来做简单线性回归。我们取RM这个属性,它指的是每个房子的房间数。

我们先找到RM属性的位置。
x = boston.data[:,5] #只取第5列,RM
y = boston.target
plt.scatter(x,y)
plt.show()

从这些数据的散点图中我们可以看到一些非常奇怪的点,它们都等于最大值50。
这些点可能是我们采集样本时的上限点,可能是你的计量仪器最大值的限制,也可能是你把所有价值大于 50万美元都记为50万美元导致的。
这里我们先简单的去掉这些数据。
np.max(y) #50.0
x = x[y < np.max(y)]
y = y[y < np.max(y)]
plt.scatter(x,y)
plt.show()

现在没有极端点了,接下来可以用我们写的简单线性回归算法来对房价进行预测了。
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y)
print(x_train.shape)#(367,)
print(x_test.shape) #(123,)
reg = SimpleLinearRegression2() # 用我们写的向量版本
reg.fit(x_train,y_train)

这样就得到训练好的模型,下面我们画出这条拟合直线。
plt.scatter(x,y)
plt.plot(x_train,reg.predict(x_train),'r')
plt.show()

现在我们就可以使用这个模型进行预测了。
y_predict = reg.predict(x_test)
接下来就用我们这小节介绍的指标来评价这个预测结果。
mse_test = np.sum((y_predict - y_test)**2) / len(y_test)
mse_test # 41.208294244548306
from math import sqrt
rmse_test = sqrt(mse_test)
rmse_test # 6.4193686795936795
mae_test = np.sum(np.absolute(y_predict - y_test)) / len(y_test)
mae_test # 4.450547791426998
实现起来也是很简单的,接下来我们把这些方法封装到函数中:
def mean_squared_error(y_true,y_predict):
return np.sum((y_true - y_predict)**2)/ len(y_true)
def root_mean_squared_error(y_true,y_predict):
return sqrt(mean_squared_error(y_true,y_predict))
def mean_absolute_error(y_true,y_predict):
return np.sum(np.absolute(y_true - y_predict)) / len(y_true)

在本节的最后我们看下sklearn中的这些标准是怎么用的。
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
print(mean_squared_error(y_test,y_predict))
print(mean_absolute_error(y_test,y_predict))

可以看到结果和我们自己写的是一样的。

最后我们看下RMSE与MAE的比较。
它们的量纲是一样的,但是RMSE的结果要比MAE大一些。
我们可以从RMSE的式子中看出原因,它是将错误值平方后再累加,最后开方。如果我们样本中最大的错误值很大,假设是100,平方后差距会扩大到10000。也就是说RMSE会放大我们的错误值。
我们尽量让RMSE更加小的意义更大的一些,这样的意义是让最大的错误值更加小。
在训练我们的算法的时候,我们的损失函数其实就是RMSE中没有根号的那部分。前面的 是常数,在给定训练集后,样本数是固定的,此时考不考虑除以 都无所谓的。当然我们在训练的过程中使用的是训练数据集而不是测试数据集。
也就是说,我们用这个损失函数本质就是想减少最终预测结果最大的误差之间的差距。
判定系数
上面我们介绍了MSE,RMSE和MAE这三个指标。其实这三个指标还有一定的问题。
我们评价分类问题的指标是分类的准确度:1表示最好,0表示最差。即使我们的分类问题不同,我们也可以用这个指标来表示不同分类算分的优劣。但是上面的这三个指标是没有这个性质的。
比如我们预测房产数据和预测学生成绩得到的这些指标是不具有可比性的。因为它们的领域不同,进而它们的量纲也不同。
这个问题的解决方法是使用判定系数R Square)这个指标。
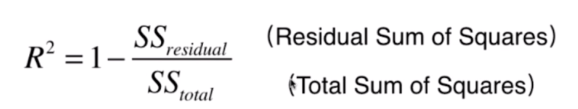
上面的式子看起来不知道是什么,如果用下面的式子就好理解多了:
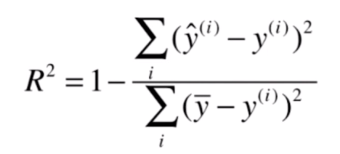
就是用预测结果减去真实值;而
是用均值减去真实值。
它们都需要平方再求和。
对于分子来说,我们可以理解为使用我们的模型预测产生的错误;

对于分母来说,可以理解为使用均值预测产生的错误。如果一个模型使用均值来进行预测,那么这个模型叫基准模型(Baseline Model),就是说我们的模型至少要比基准模型要好,否则我们学习到的模型是没有什么意义的。
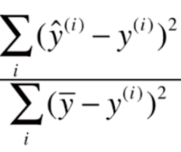
这个式子就考虑了我们预测的模型和基准模型之间的关系,如果这项越小,说明我们的模型越好,反之说明我们的模型越差。如果整个式子的结果大于1,说明我们的模型甚至比不上基准模型。

再结合整个式子来考虑的话, 越大越好,最大为 ,因为最好的模型就是使得分子为 ,整个式子为 。当然,这种 情况是很难实现的,我们来考虑其他情况:
- 当我们的模型等于基准模型时, 为
- 如果 ,说明我们学习的模型还不如基准模型。此时,很有可能是我们的数据不存在任何线性关系
这个式子是不是很眼熟呢,如果我们把分子分母同除以 的话:
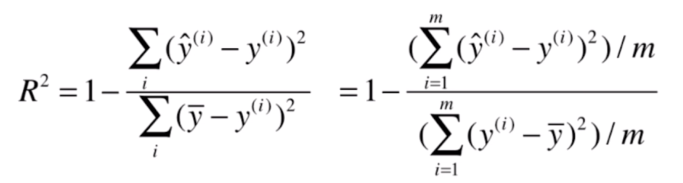
那么得到的分子部分就成了MSE,分母部分就是
的方差。
因此可以写成这种形式:
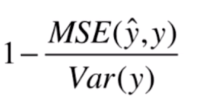
公式介绍的差不多了,下面我们编程来实现一下:
1 - mean_squared_error(y_test,y_predict) / np.var(y_test)
理解了上面的式子,实现起来也挺简单的。
最后我们看下sklearn中是如何使用的:
from sklearn.metrics import r2_score
r2_score(y_test,y_predict)
 我们也可以把这个方法封装到我们的回归类中:
我们也可以把这个方法封装到我们的回归类中:
# 最小二乘法实现的
import numpy as np
class SimpleLinearRegression2:
def __init__(self):
self.a_ = None
self.b_ = None
def fit(self,x_train,y_train):
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
# 通过向量化运算
num = (x_train - x_mean).dot(y_train - y_mean) #dot是向量点乘,返回的是标量
d = (x_train - x_mean).dot(x_train - x_mean)
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self,x_predict):
return np.array([self._predict(x) for x in x_predict])
def _predict(self,x_single):
return self.a_ * x_single + self.b_
def score(self,x_test,y_test):
y_predict = self.predict(x_test)
return mean_squared_error(y_test,y_predict) / np.var(y_test)
def __repr__(self):
return "SimpleLinearRegression2(a=%s,b=%s)" % (self.a_,self.b_)
在简单线性回归中,每个样本只有一个特征,但是实际情况是每个样本很可能是有多个特征的。
对于多个特征的情况,我们可以用多元线性回归处理。
多元线性回归

如果这里每个 是一个向量的话,就成了多元线性回归问题。对应的 成了截距 。
如果我们可以学习到
到
这些参数值的话,我们就可以通过下面的方式预测多个特征的样本值:
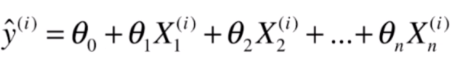
其实求解思路和简单线性回归是一致的,对于简单线性回归来说,我们使
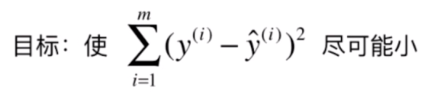
对于多元线性回归问题来说,
表达式成了
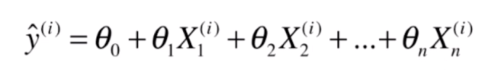
因此目标就变成了找到一组
使得这个式子尽可能小:

我们把我们要求解的
整理成一个向量
(加上转置表示这是个列向量):
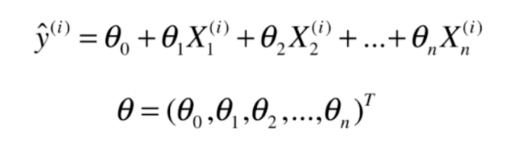
我们让这个式子保存一致,我们增加一个虚构的特征
,得到:
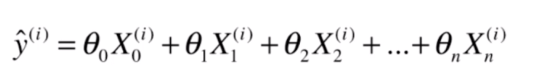
这样我们可以说
(行向量)是这样的:
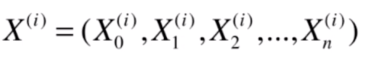
这样的好处是,我们可以简化
的表示:
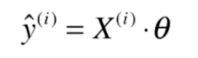
把它推广到所有的样本上,我们定义一个新的矩阵
:

其实就是多了我们虚构的一列
。
就是有
个元素的列向量:
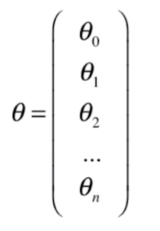
此时
就可以写成:
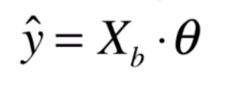
是 的矩阵,而 是 的向量,它们点乘的结果就是 的向量。相当于是这 个样本的预测值。
这样多元线性回归问题就是使得这个式子尽可能小
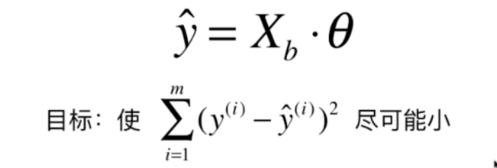
而这个式子也可以做向量化处理

我们的多元线性回归问题就是估计一个
使得这样的一个式子尽可能小
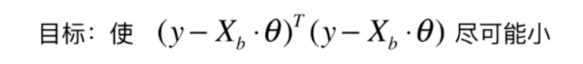
我们求这个问题的思路和简单线性回归是一样的,也可以使用最小二乘法的思路。
对 中的每个变量进行求导,让它们等于 。

可以推导出 的式子如上,这个推导过程我们可以先不深究,事实上对于多元线性回归问题一般是使用梯度下降这种方法去解的。
这个式子被称为是多元线性回归的正规方程解(Normal Equation)。
这个式子看起来好,但是实际上求解是有问题的。它的时间复杂度过高( ,虽然经过优化后可以达到 ,也是很高)。
如果你的样本数量量很多,或者样本特征很多,用这个式子来解就很耗时。但是不管怎样,我们先来实现下。
实现多元线性回归

这里我们的
是包括截距的,但是求解了之后一般会分开保存它们。因为系数和截距的意义是不同的。
知道了这一点后就可以开始编写代码了:
import numpy as np
from sklearn.metrics import r2_score
class LinearRegression:
def __init(self):
self.coef_ = None # 系数
self.interception_ = None # 截距
self._theta = None
def fit_normal(self, X_train, y_train):
X_b = np.hstack([np.ones((len(X_train), 1)), X_train]) # 构造X_b X_train加上 虚构的都等于1的列
self._theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y_train) # 通过正规方程解求得theta
# 分开保存
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def predict(self, X_predict):
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
return X_b.dot(self._theta)
def score(self, X_test, y_test):
y_predict = self.predict(X_test)
return r2_score(y_test, y_predict)
def __repr__(self):
return "LinearRegression(coef_=%s,interception_=%s)" % (self.coef_, self.interception_)
写好多元线性回归类后我们拿真实数据来测试一下它,此时我们使用全部的特征:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
y = boston.target
X = X[y < 50.0]
y = y[y < 50.0]
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y)
reg = LinearRegression()
reg.fit_normal(X_train,y_train)

并且我们可以看一下结果的R方值是多少:
reg.score(X_test,y_test) #0.7277453338706474
这个值比我们刚才只有一个特征来进行预测的结果好了不少(其实这么说不太准确,应该在拆分数据集的时候指定一个随机种子,如:X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666),这样保证数据和测试数据是一样的才有说服性。我这里就不这样做了,大家可以自己试一下),从这里可以看到,如果我们的数据特征更多,并且真的能反应房价指标,那么使用更多的特征预测结果会更好。
接下来我们看下如何使用sklearn中封装的类来解决回归问题。
使用sklearn解决回归问题
先准备好数据:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
boston = datasets.load_boston()
X = boston.data
y = boston.target
X = X[y < 50.0]
y = y[y < 50.0]
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666)
接下来就是调用sklearn中的类:
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X_train,y_train)
我们查看下它学到的参数:

lin_reg.score(X_test,y_test) # 0.8009390227581032
看起来似乎比我们自己实现的要好,但其实是一样的。当我指定一样的随机种子后,再看:

在文章开头说,线性回归法的结果具有很好的可解释性。为什么这么说呢,下面一起来看下。
线性回归的可解释性

我们以上文中用sklearn封装的线性回归类得到的结果为例说明。
看以看到coef_返回了一个系数的数组。
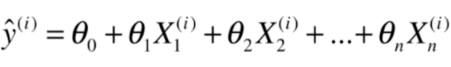
这里返回的系数是从
开始。每个系数的正负号表示相应的特征与房价的关系是正相关还是负相关。
如果为正的话,值越大,表示相关度越高。相应的特征值就越能影响房价(房价越大);如果系数的符号为负的话,表示负相关,系数绝对值越大,房价就越低。
也就是说正负符号代表是正相关还是负相关,而系数绝对值的大小代表的是影响程度。
因此在这里我们对系数进行一下排序。

默认的排序是从小到大的。它返回的数组中,最左边的那个元素就是负的特别大的值,最右边的那个元素是正的特别大的值。
我们可以把结果传入feature_names数组,来看下这些是什么特征:
boston.feature_names[np.argsort(lin_reg.coef_)]

我们看下文档,看这些特征表示什么意义:

从中可以看出,最大的特征RM表示房间数量,第二大特征RAD表示离高速路的距离,就是交通的便利性;
我们再来看下负相关最大的特征NOX,它表示氮氧化物如一氧化碳浓度,一氧化氮浓度越高,房价越低,这是很合理的。第二大特征是DIS,它说的是离上班地方的远近,当然越远房价就低。这也很合理。
这就是我们说线性回归对数据具有可解释性。当我们获得了这个可解释性后,我们可以采集更多的特征来更好的预测房价,比如房间数量其实是和房间的大小,占地面积有关的。我们可以去采集下这些特征,看能否更好的预测房价。
总结
本文我们详细探讨了线性回归算法。

线性回归算法只能解决回归问题,它是一个典型的参数学习问题。
我们在使用线性回归算法时,是有一个假设的。假设就是数据和最终的输出结果之间有一定的线性关系。
我们也可以通过改进线性回归算法来解决非线性问题。
线性回归算法有个非常重要的有点是对数据具有强解释性。
本文文通过正规方程解来实现的线性回归算法, 如果我们的样本数量或特征数量巨大的话,使用这种方法是不合适的。那么应该要怎么办呢,下一篇文章就会介绍另一种方法——梯度下降法。
梯度下降法是求解最优模型的通用方法。
参考
- 上一篇:机器学习入门——K近邻算法
- 下一篇:机器学习入门——不可不知的梯度下降算法详解
