AIStudio介绍
目前各大公司为了发展自己的人工智能业务,同时也是为了推广自己的解决方案,都推出了免费GPU计算资源。比如说谷歌的Kanggle Kernel和Google Colaboratory。与谷歌相比,百度的AIStudio和飞桨(PaddlePaddle)算是后起之秀。
飞桨作为国产的深度学习框架,但由于Tensorflow和Pytorch在深度学习领域巨大的统治力,所以其一直处于不温不火的状态。于是百度便提供了一个针对AI学习者的在线一体化开发平台。平台集合了AI教程, 深度学习样例工程, 各领域的经典数据集, 云端的运算及存储资源, 以及比赛平台和社区。
与其他的平台类似,AIStudio也提供了GPU支持,但百度的AIStudio相对于其他的平台有一个明显的优势。AIStudio采用的是Tesla V100的GPU,在单精度浮点运算上,AI Studio提供的运行环境在计算性能上还是很有优势的。虽然性能上好很多,但目前还是可以免费得到,目前AI Studio提供了免费申请和运行项目奖励这两种获得算力卡的方式。即使算力卡用完了(目前送得太多,根本用不完),AI Studio的CPU也是很有竞争力的。AI Studio的CPU采用的是 Intel® Xeon® Gold 6148 CPU,可以说在配置上,AI Studio是很有竞争力的。
但百度毕竟是百度,国产GPU的羊毛也不能随便薅。AIStudio中默认只能使用PaddlePaddle作为学习框架,对于Tensorflow等是不支持且不允许的。但也不是没有办法(手动狗头)。其实支持一下国产的深度学习框架是件好事,更何况参加比赛还有奖金拿。

项目创建
项目创建的具体步骤不再赘述。这里只说明几个问题:
- 导入的数据集是
.zip格式,进入到环境后保存在/data目录下。可将下载的各种框架以及数据集一起打包后导入。进入环境后找到压缩文件使用unzip命令解压。 - 进入环境后输入
nvidia-smi可以显示当前的显卡驱动信息,先观察你的驱动版本,如果是3.9.x,那么环境可以直接使用。但如果你的版本是4.0.0及以上,并且环境为darknet的话,请重新打开项目,直到版本正确为止。但如果你使用的为Tensorflow2.0,那么4.0.0及以上的显卡驱动是可以直接使用的。(关于问什么重启之后显卡驱动版本会来回切换,这个我也不太清楚,这可能也是需要改进的地方,狗头+1)。 - 不要尝试重装或更新显卡驱动版本。
打开后的环境如下截图
可以看到环境中除了终端之外还提供了一个notebook,虽然没有图形界面,但这也方便了我们进行代码编写和数据处理。这里SHELL所处目录为/home/aistudio.
安装darknet
这里有两种方式安装darknet,第一种是直接从官网git下来,依次输入:
git clone https://github.com/pjreddie/darknet.git
cd darknet
make
另一种方法是先从这里下载下来,然后和数据集一起导入环境,解压后同样进入到/darknet下进行编译。
如果成功的话你将可以看到以下信息
mkdir -p obj
gcc -I/usr/local/cuda/include/ -Wall -Wfatal-errors -Ofast....
gcc -I/usr/local/cuda/include/ -Wall -Wfatal-errors -Ofast....
gcc -I/usr/local/cuda/include/ -Wall -Wfatal-errors -Ofast....
.....
gcc -I/usr/local/cuda/include/ -Wall -Wfatal-errors -Ofast -lm....
编译完成之后运行darknet
./darknet
成功的话将会出现以下结果
usage: ./darknet <function>
开启GPU编译
为了让yolo更快运行,并且AIStudio已经提供了免费的GPU 资源,所以这里我们一定要开启GPU:
cd /darknet
vi Makefile
然后将第一行和第二行的值都修改为1,修改后如下图
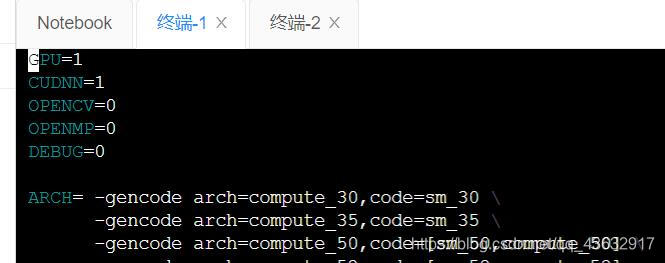
之后退出编译器回到/darknet重新编译,如下
成功后输出

注意这个地方,如果上面你的显卡驱动版本为4.0.0以上的话,这里的编译将会报错。具体原因应该与darknet的版本有关。
测试预训练模型
这里我们先使用yolo官方提供的预训练模型来测试一下当前环境。
预训练模型可以从这里下载之后导入到数据集中,也可以直接在终端输入以下命令
wget https://pjreddie.com/media/files/yolov3.weights
注意下载的yolov3.weights权重文件应放在/darknet目录下。
然后进行测试
./darknet detect cfg/yolov3.cfg yolov3.weights data/eagle.jpg
正常的话将会看到以下输出:
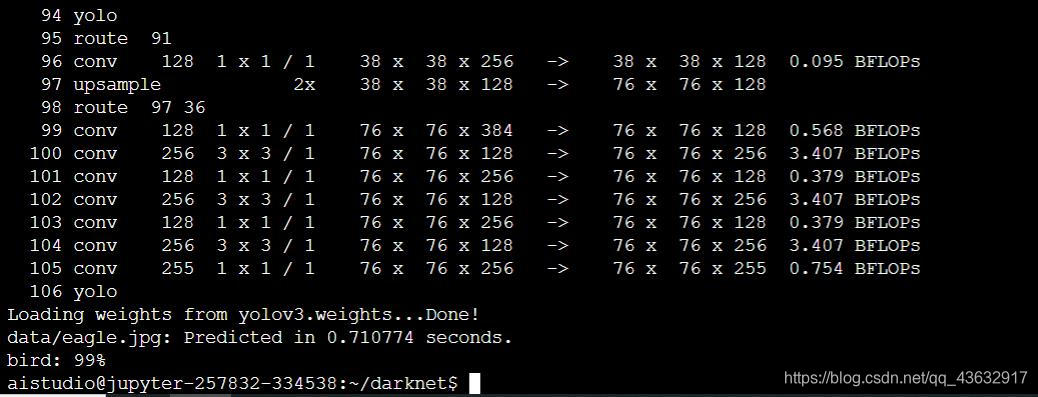
当然以上过程将会非常快。
接下来我们用AIStudio提供的notebook来看一下输出的图片。需要注意的是,AIStudio的notebook默认的环境是PaddlePaddle,且不支持其他的框架,这里就是我目前看来最不方便的地方之一。但是我们还是可以它来进行一些文件的读写或者数据的处理的。这里我把他作为一个python的IDE来使用。然后我通过matplotlib将刚才的图片显示出来
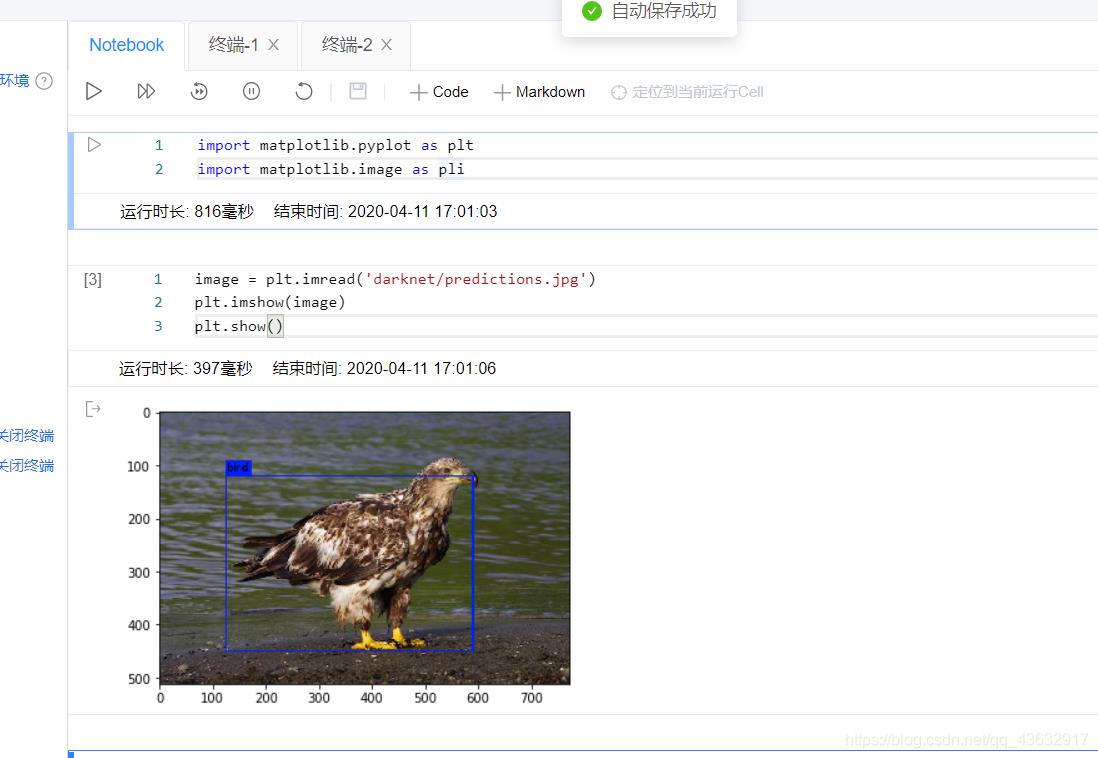
如上图所示,我们可以发现预测结果是正确的,至此,我们的环境就配置完成了。
训练自己的数据集
之后我们就可以快乐的使用白嫖来的GPU来训练自己的数据集了,这里我给出我的例子。
我这里使用的为yolov3-tiny的权重文件,可以在这里下载。
训练文件的目录如下

(yolov3参数配置过程不再赘述)
在终端输入以下命令得到预训练模型yolov3-tiny.conv.15
./darknet partial dataset/yolo-tiny-obj.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15
输入以下命令开始训练
./darknet detector train dataset/obj.data dataset/yolo-tiny-obj.cfg yolov3-tiny.conv.15
如果一切正常将会开始训练
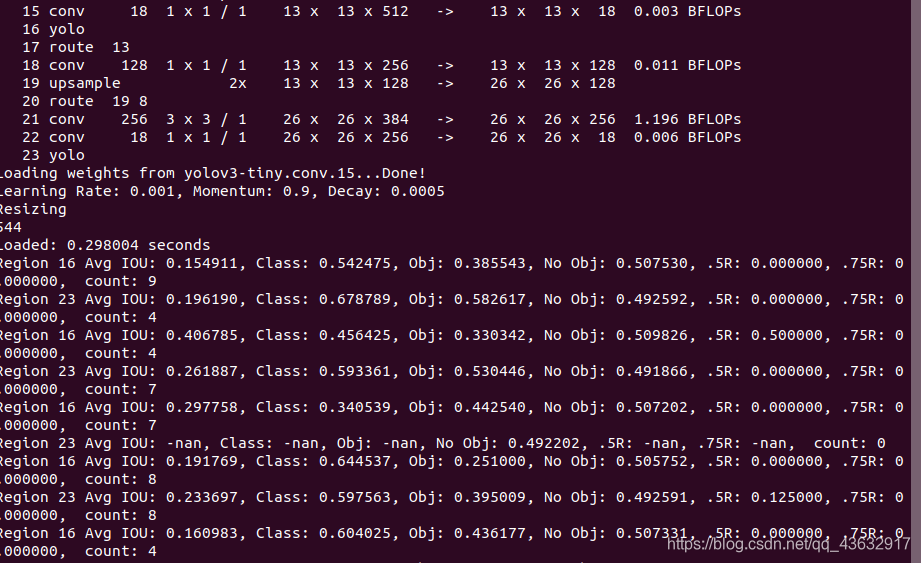
如果你运行中出现了nan, 这是正常现象,但如果全部都是nan的话,这就是训练过程出了问题,请仔细检查每一步是否按照操作进行。
训练完成后进行测试:
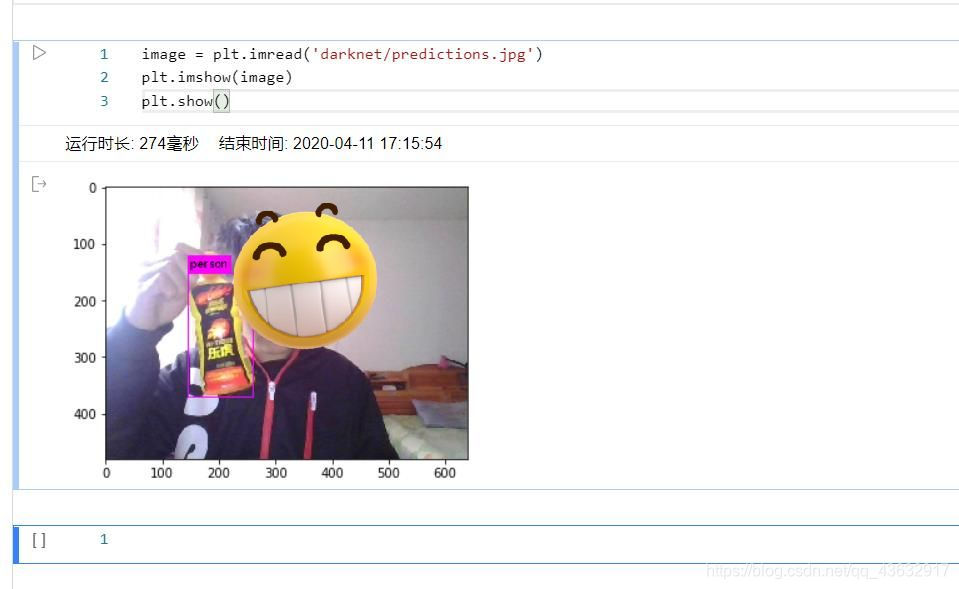
yolov3-tiny在迭代10000次左右之后效果已经非常好,而且速度相对于我笔记本上的垃圾显卡的提升也是非常可观的,300张训练样本,100张测试样本总耗时两个多小时(在我的MX150上训练可能需要两个晚上)。
其他配置
Git配置
这里我使用git的原因是我发现没有办法能够从项目中导出我训练的文件,于是我突发奇想,直接建一个仓库将我的文件从AIStudio直接push到远程仓库。缺点是,但训练的权重文件太大时,速度不会很快。当然这里只是我的一个做法,应该还有其他的方法能够将文件夹导出。此处抛砖引玉。
创建数据文件夹
由于每次重启项目的时候,平台并不会保留我们的所有操作,这里就需要我们将所有的文件全都放在/home/aistudio目录下,也就是主目录
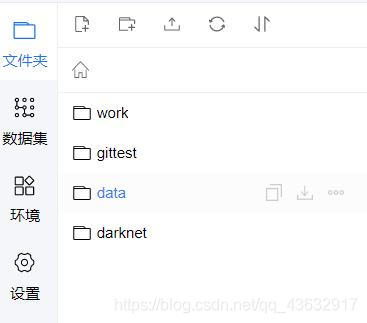
如上图所示,这里的/work以及/data是平台默认的文件夹,一般导入的数据集都存放在/data目录下。下面的/gittest以及/darknet是我自己创建的文件夹,在主目录创建文件夹,重启之后不会删除。
写在最后
由于AIStudio是一个相对比较新的平台,并且PaddlePaddle是一个非常好用框架,如果你掌握了该框架,就可以不需要以上这些步骤,直接使用PaddlePaddle的一些API完成自己的训练了。所以说对于一个全新的事物,更应该采用全新的眼光去看待它。倘若还是因循守旧,结果只能适得其反,给自己带来不必要的麻烦。
