TX2上用YOLOv3训练自己数据集的流程(VOC2007数据集-TX2-GPU版本)
平台:英伟达NVIDIA TX2开发板 环境:python2.7,cuda8.0,cudnn6.0.2. 以下2007都改为2009,文件夹修改的原因
前期准备:
以防8G的内存不够用,另外开辟4-8G的虚拟内存:
1. 创建8G大小的swapfile
fallocate -l 8G swapfile
2. 更改swapfile的权限
chmod 600 swapfile
3. 创建swap区
mkswap swapfile
4. 激活swap区
sudo swapon swapfile
5. 确认swap区在用
swapon -s
运行过程中如果遇到内存占用较多,执行以下语句清除部分内存的占用:
1.1 数据集制作:
A.制作VOC格式的xml文件工具:LabelImg
将xml文件存放在/darknet/scripts/VOCdevkit/VOC2009/Annotations
B.将VOC格式的xml文件转换成YOLO格式的txt文件
用到的脚本:voc_label.py
执行:cd darknet
python voc_label.py
生成:
1、/darknet/scripts/VOCdevkit/VOC2009/labels
2、/darknet/scripts/2009_train.txt
.txt里的数据格式是这样的:

具体的每一个值的计算方式是这样的:假设一个标注的boundingbox的左下角和右上角坐标分别为(x1,y1)(x2,y2),图像的宽和高分别为w,h
归一化的中心点x坐标计算公式:((x2+x1) / 2.0)/ w
归一化的中心点y坐标计算公式:((y2+y1) / 2.0)/ h
归一化的目标框宽度的计算公式: (x2-x1) / w
归一化的目标框高度计算公式:((y2-y1)/ h
1.2 文件修改
准备好了自己的图像后,需要按VOC数据集的结构放置图像文件。VOC的结构如下
--VOC2009
--Annotations ---主要存放xml文件
--ImageSets
--Main -----为train.txt等(需要自己用软件生成)
作用:
--Layout
--Segmentation
--JPEGImages ---放我们已按统一规则命名好的原始图像
--SegmentationClass
--SegmentationObject
这里面用到的文件夹是Annotation、ImageSets和JPEGImages。
其中文件夹Annotation中主要存放xml文件,每一个xml对应一张图像,并且每个xml中存放的是标记的各个目标的位置和类别信息,命名通常与对应的原始图像一样;而ImageSets我们只需要用到Main文件夹,这里面存放的是一些文本文件,通常为train.txt等,该文本文件里面的内容是需要用来训练或测试的图像的名字(无后缀无路径);JPEGImages文件夹中放我们已按统一规则命名好的原始图像。
因此,首先
1.新建文件夹VOC2009(通常命名为这个,也可以用其他命名,但一定是名字+年份,例如MYDATA2016,无论叫什么后面都需要改相关代码匹配这里,本例中以VOC2007为例)
2.在VOC2009文件夹下新建三个文件夹Annotation、ImageSets和JPEGImages,并把准备好的自己的原始图像放在JPEGImages文件夹下
3.在ImageSets文件夹中,新建三个空文件夹Layout、Main、Segmentation,然后把写了训练或测试的图像的名字的文本拷到Main文件夹下,按目的命名,我这里所有图像用来训练,故而Main文件夹下只有train.txt文件。
1.3 编译工程
改配置文件:
我想要GPU支持的版本,所以在编译工程前需要先修改Makefile文件,根据自己需求改,GPU版本的将GPU=1,CUDNN = 1, OPENCV=1,

执行:
cd darknet
make
如果遇到缺失包报错,将缺失的包装上去以后重新编译,重复下列两个操作,直到所有包都装好,
make clean
make
1.4 配置文件参数修改
(A) 修改darknet/cfg/voc-1.data
classes= 80 类别数
train = /home/nvidia/darknet/scripts/2009_train.txt 训练数据2009_train.txt的路径
//valid = /home/pjreddie/data/voc/2009_test.txt 验证数据2009_test.txt的路径
names = data/2-voc-1.names 存放类别名
backup = /home/nvidia/darknet/backup 生成的权重文件存放的路径
(B)关于cfg修改,以6类目标检测为例,主要有以下几处调整(蓝色标出),也可参考我上传的文件,里面对应的是4类。#表示注释,根据训练和测试,自行修改。
例如:cfg/yolov3-1.cfg
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=1
subdivisions=1
# 一批训练样本的样本数量,每batch个样本更新一次参数
# batch/subdivisions作为一次性送入训练器的样本数量
# 如果内存不够大,将batch分割为subdivisions个子batch
# 上面这两个参数如果电脑内存小,则把batch改小一点,batch越大,训练效果越好
# subdivisions越大,可以减轻显卡压力

learning_rate:学习率,训练发散的话可以降低学习率。学习遇到瓶颈,loss不变的话也减低学习率。
max_batches: 最大迭代次数。
policy:学习策略,一般都是step这种步进式。
step,scales:这两个是组合一起的,举个例子:learn_rate: 0.001, step:100,25000,35000 scales: 10, .1, .1 这组数据的意思就是在0-100次iteration期间learning rate为原始0.001,在100-25000次iteration期间learning rate为原始的10倍0.01,在25000-35000次iteration期间learning rate为当前值的0.1倍,就是0.001, 在35000到最大iteration期间使用learning rate为当前值的0.1倍,就是0.0001。随着iteration增加,降低学习率可以是模型更有效的学习,也就是更好的降低train loss。

最后一层卷积层中filters数值是 5×(类别数 + 5)。
region里需要把classes改成你的类别数。
最后一行的random,是一个开关。如果设置为1的话,就是在训练的时候每一batch图片会随便改成320-640(32整倍数)大小的图片。目的和上面的色度,曝光度等一样。如果设置为0的话,所有图片就只修改成默认的大小 416*416。
1.5 跑模型
I.5.1 训练
上面完成了就可以命令训练了,可以在官网上找到一些预训练的模型作为参数初始值,也可以直接训练,训练命令为
$./darknet detector train ./cfg/voc-1.data cfg/yolov3-1.cfg
将权重文件保存在/darknet/backup下
训练过程中会根据迭代次数保存训练的权重模型,然后就可以拿来测试了。

Avg IOU: 当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1;
Class: 标注物体的分类准确率,越大越好,期望数值为1;
obj: 越大越好,期望数值为1;
No obj: 越小越好;
.5R: 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
0.75R: 以IOU=0.75为阈值时候的recall;
count: 正样本数目。

I.5.2 测试
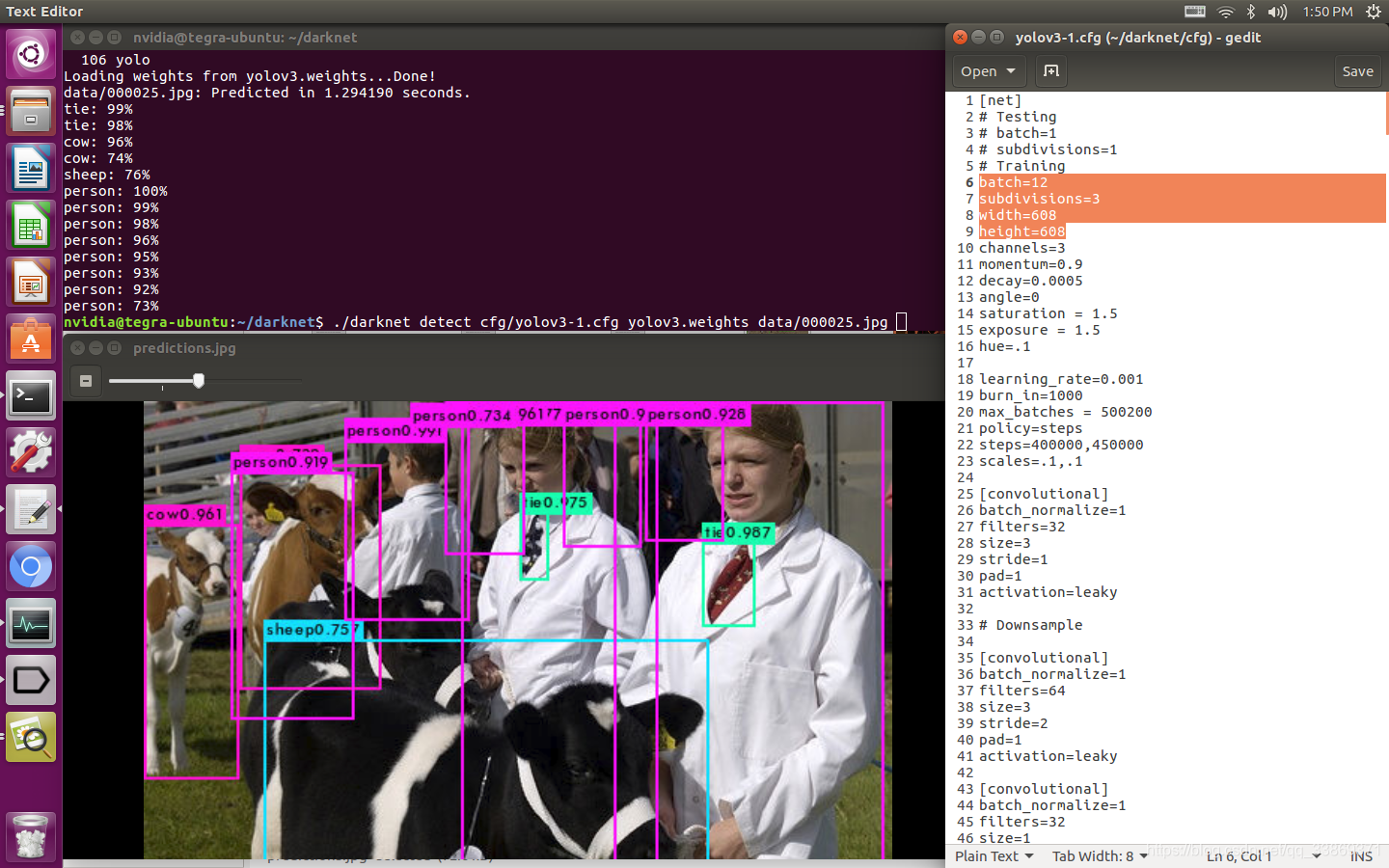
(1)一张图片
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
原始图片
生成的图片保存在darknet下
(2)一个视频
./darknet detector demo cfg/ voc-1.data cfg/yolov3-1.cfg yolov3.weights data/test1.flv


(3)批量图片
./darknet detector test cfg/voc-2.data cfg/yolov3-1.cfg yolov3.weights
Enter Image Path:后面输入你的txt文件路径(你准备好的所有测试图片的路径全部存放在一个txt文件里)
这里可以输入:/home/nvidia/darknet/scripts/2009_train.txt
输出带标记的图片保存在:/darknet /data/out
(4)验证批量图片,返回评估值
将要验证的每张图片的路径保存在scripts/2009_valid-1.txt 下
./darknet detector valid cfg/voc-valid-1.data cfg/yolov3-1.cfg yolov3.weights
/*只在./results/det_valid_[类名].txt里保存测试结果,如下:*/
<image identifier> <confidence> <left> <top> <right> <bottom>
文件名;每个框中存在该分类物体的概率;框框坐标 xmin;框框坐标 ymin;框框坐标 xmax;框框坐标 ymax
其中(左,上) - (右,下)定义检测对象的边界框。 图像中左上角的像素具有坐标(1,1)。 更高的置信度值意味着检测结果的正确性。 下面显示了一个示例文件摘录。 请注意,对于图像000006,检测到多个对象:
复制代码
//comp3_det_test_car.txt:
000004 0.702732 89 112 516 466
000006 0.870849 373 168 488 229
000006 0.852346 407 157 500 213
(5)查看训练网络的召回率
https://www.jianshu.com/p/7ae10c8f7d77/
https://blog.csdn.net/hysteric314/article/details/54093734
./darknet detector recall cfg/voc-valid-1.data cfg/yolov3-1.cfg yolov3.weights (这个命令需修改dectector.c文件)

- Number表示处理到第几张图片。
- Correct表示正确的识别除了多少bbox。这个值算出来的步骤是这样的,丢进网络一张图片,网络会预测出很多bbox,每个bbox都有其置信概率,概率大于threshold的bbox与实际的bbox,也就是labels中txt的内容计算IOU,找出IOU最大的bbox,如果这个最大值大于预设的IOU的threshold,那么correct加一。
- Total表示实际有多少个bbox。
- Rps/img表示平均每个图片会预测出来多少个bbox。
- IOU: 这个是预测出的bbox和实际标注的bbox的交集 除以 他们的并集。显然,这个数值越大,说明预测的结果越好。
- Recall召回率, 意思是检测出物体的个数 除以 标注的所有物体个数。通过代码我们也能看出来就是Correct除以Total的值。
大雁与飞机
假设现在有这样一个测试集,测试集中的图片只由大雁和飞机两种图片组成,如下图所示:

假设你的分类系统最终的目的是:能取出测试集中所有飞机的图片,而不是大雁的图片。
现在做如下的定义:
True positives : 飞机的图片被正确的识别成了飞机。
True negatives: 大雁的图片没有被识别出来,系统正确地认为它们是大雁。
False positives: 大雁的图片被错误地识别成了飞机。
False negatives: 飞机的图片没有被识别出来,系统错误地认为它们是大雁。
假设你的分类系统使用了上述假设识别出了四个结果,如下图所示:
那么在识别出来的这四张照片中:
True positives : 有三个,画绿色框的飞机。
False positives: 有一个,画红色框的大雁。
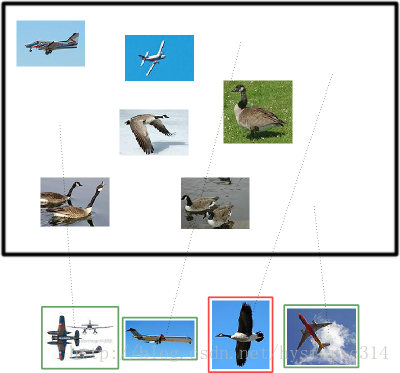
没被识别出来的六张图片中:
True negatives : 有四个,这四个大雁的图片,系统正确地没有把它们识别成飞机。
False negatives: 有两个,两个飞机没有被识别出来,系统错误地认为它们是大雁。
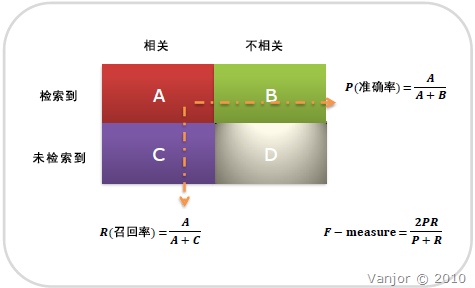
Precision 与 Recall
Precision其实就是在识别出来的图片中,True positives所占的比率:
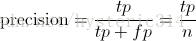
其中的n代表的是(True positives + False positives),也就是系统一共识别出来多少照片 。
在这一例子中,True positives为3,False positives为1,所以Precision值是 3/(3+1)=0.75。
意味着在识别出的结果中,飞机的图片占75%。
Recall 是被正确识别出来的飞机个数与测试集中所有飞机的个数的比值:
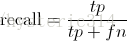
Recall的分母是(True positives + False negatives),这两个值的和,可以理解为一共有多少张飞机的照片。
在这一例子中,True positives为3,False negatives为2,那么Recall值是 3/(3+2)=0.6。
意味着在所有的飞机图片中,60%的飞机被正确的识别成飞机.。
准确率就是找得对,召回率就是找得全。
I.5.3 注意
1、测试输出的图片与原图片像素相同,
2、用yolov3-tiny-1.cfg(288*288), 跑test1.flv,大概30帧左右
用yolov3-tiny-1.cfg(输入网络图片像素为416*416), 跑test1.flv,大概20帧左右
用yolov3-tiny-1.cfg(608*608), 跑text1.flv,大概10帧左右
用yolov3-1.cfg(288*288), 跑test1.flv,大概5帧左右
用yolov3-1.cfg(416*416), 跑test1.flv,大概3帧左右
用yolov3-1.cfg(608*608), 跑test1.flv,大概2帧左右
参考文献
[1] https://blog.csdn.net/u012135425/article/details/80294884
[2] https://blog.csdn.net/lilai619/article/details/79695109
[3] https://www.cnblogs.com/antflow/p/7350274.html
[4]https://blog.csdn.net/mieleizhi0522/article/details/79989754