本人CSDN博客专栏:https://blog.csdn.net/yty_7
Github地址:https://github.com/yot777/
使用Matplotlib将数据可视化
Matplotlib 能创建非常多的可视化图表,它有一个丰富的 Python 工具生态环境,请移步到以下教程进行学习:
https://blog.csdn.net/zw0Pi8G5C1x/article/details/79186024
如果不打算深入学习,使用下图可以简要了解Matplotlib 的一些重要术语:

结合我们上一节的内容,演示一下在Python中如何使用Matplotlib将数据可视化。
步骤1:我们要引入Matplotlib库,使用以下import语句,之后使用Matplotlib库的简写成plt就可以了。
import matplotlib.pyplot as plt如果提示没有安装matplotlib模块,请使用Python的pip命令进行安装。
步骤2:我们要决定画哪种图,由于上一节的使用的数据是:
1 2 1
4 5 0
2 1 1
4 2 1
6 1 0
3 3 1
5 2 0
4 5 0
2 7 0
2 6 1
前两列是特征,最后一列是标签,一共10条数据,因此我们画散点图,并且不同标签显示不同的颜色。
scatter()是Matplotlib库画散点图的函数,原型如下:
matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, verts=None, edgecolors=None, *, data=None, **kwargs)
我们暂且只使用scatter()函数的最简单形式:scatter(x, y)
参数(x, y)表示即将绘制散点图的数据点的x轴坐标和y轴坐标。
特别注意x, y均是长度为n的元组,示例如下:
import matplotlib.pyplot as plt
#画出3个散点,坐标分别是(1,1)、(2,4)、(3,9)
plt.scatter((1,2,3), (1,4,9))
plt.show()运行结果如图:
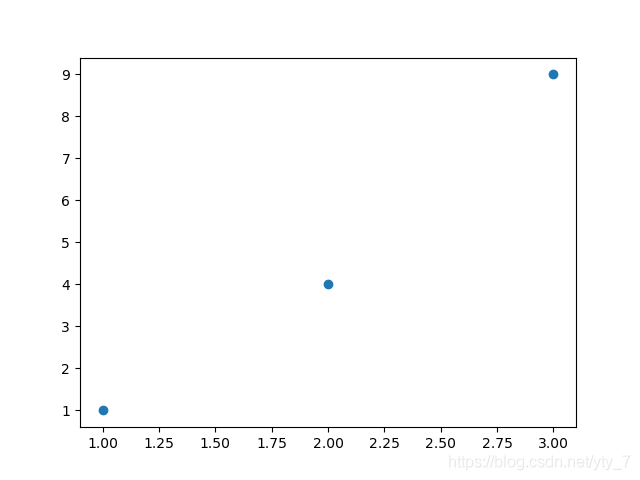
scatter()函数的详细讲解请移步:
https://blog.csdn.net/m0_37393514/article/details/81298503
步骤3:将原始数据按照不同的标签分类,即将标签为0的放到一组,将标签为1的放到一组
步骤4:将标签为0那一组数据用scatter()函数导入x轴坐标和y轴坐标。
步骤5:将标签为1那一组数据用scatter()函数导入x轴坐标和y轴坐标。
步骤6:显示画好的散点图。
代码如下,注意和之前代码略有不同的地方:
上一节的代码:
#特征矩阵featureMat实际上是二维列表,注意添加元素的方法和一维列表稍有不同
featureMat.append([lineArr[0], lineArr[1]])
#向标签向量labelMat添加元素,即lineArr当前行的最后1个元素
labelMat.append(lineArr[-1])本节代码:
#特征矩阵featureMat实际上是二维列表,注意添加元素的方法和一维列表稍有不同
featureMat.append([float(lineArr[0]), float(lineArr[1])])
#向标签向量labelMat添加元素,即lineArr当前行的最后1个元素
labelMat.append(float(lineArr[-1]))注意:特征矩阵featureMat和标签向量labelMat的每一个元素都被强制转型成了float浮点数字型,这是为了方便scatter()函数识别x轴坐标和y轴坐标,因为坐标只能是数字不能是字符。
完整代码如下:
import matplotlib.pyplot as plt
import numpy as np
def loadDataSet(fileName):
#创建空特征矩阵
featureMat = []
#创建空标签向量
labelMat = []
#打开文件
fr = open(fileName)
#按行遍历读取文件
for line in fr.readlines():
#每一行先去掉回车换行符,再以Tab键为元素之间的分隔符号,把每一行分割成若干个元素
lineArr = line.strip().split('\t')
#向特征矩阵featureMat添加元素,即lineArr当前行的第0个元素和第1个元素
#特征矩阵featureMat实际上是二维列表,注意添加元素的方法和一维列表稍有不同
featureMat.append([float(lineArr[0]), float(lineArr[1])])
#向标签向量labelMat添加元素,即lineArr当前行的最后1个元素
labelMat.append(float(lineArr[-1]))
#当前行的元素已添加到特征矩阵featureMat和标签向量labelMat,进入下一行继续
#所有行都读取完毕后关闭文件
fr.close()
#整个loadDataSet()函数返回特征矩阵featureMat和标签向量labelMat
return featureMat, labelMat
def showDataSet(featureMat, labelMat):
#创建标签为1的样本列表
data_one = []
#创建标签为0的样本列表
data_zero = []
#遍历特征矩阵featureMat,i是特征矩阵featureMat的当前行
#特征矩阵featureMat的两个特征列,正好是散点图的数据点的x轴坐标和y轴坐标
for i in range(len(featureMat)):
#如果特征矩阵featureMat的当前行号i对应的标签列表labelMat[i]的值为1
if labelMat[i] == 1:
#将当前特征矩阵featureMat[i]行添入data_one列表
data_one.append(featureMat[i])
#如果特征矩阵featureMat的当前行号i对应的标签列表labelMat[i]的值为0
elif labelMat[i] == 0:
#将当前特征矩阵featureMat[i]行添入data_zero列表
data_zero.append(featureMat[i])
#将做好的data_one列表转换为numpy数组data_one_np
data_one_np = np.array(data_one)
#将做好的data_zero列表转换为numpy数组data_zero_np
data_zero_np = np.array(data_zero)
#根据标签为1的样本的x坐标(即data_one_np的第0列)和y坐标(即data_one_np的第1列)来绘制散点图
plt.scatter(data_one_np[:,0], data_one_np[:,1])
#根据标签为0的样本的x坐标(即data_zero_np的第0列)和y坐标(即data_zero_np的第1列)来绘制散点图
plt.scatter(data_zero_np[:,0], data_zero_np[:,1])
#显示画好的散点图
plt.show()
if __name__ == '__main__':
#调用loadDataSet()函数
X, y = loadDataSet('test.txt')
#调用showDataSet()函数
showDataSet(X, y)
运行结果如图:

我们从散点图可以直观看出:
蓝色的点(标签为1)似乎都集中在图的左下部分,橙色的点(标签为0)似乎都集中在图的右上部分
我们在散点图上再增加两个点A和B,想想他们的标签应该分别是什么?这就是机器学习第一个算法KNN即将解决的问题。

总结
Matplotlib 能创建非常多的可视化图表,绘图步骤:
步骤1:引入Matplotlib库,使用import matplotlib.pyplot as plt
步骤2:决定画哪种图,本节是散点图
散点图暂时只使用scatter()函数的最简单形式:scatter(x, y)
参数(x, y)表示即将绘制散点图的数据点的x轴坐标和y轴坐标。
特别注意x, y均是长度为n的元组
步骤3:将原始数据按照不同的标签分类,即将标签为0的放到一组,将标签为1的放到一组
步骤4:将标签为0那一组数据用scatter()函数导入x轴坐标和y轴坐标。
步骤5:将标签为1那一组数据用scatter()函数导入x轴坐标和y轴坐标。
步骤6:显示画好的散点图。
注意:特征矩阵featureMat和标签向量labelMat的每一个元素都要强制转型成为float浮点数字型。
本人CSDN博客专栏:https://blog.csdn.net/yty_7
Github地址:https://github.com/yot777/
如果您觉得本篇本章对您有所帮助,欢迎关注、评论、点赞!Github欢迎您的Follow、Star!
