上一篇有对R-CNN做出详解。地址:R-CNN详解
本文主要是描述SPPNet对R-CNN在速度上的一些改进。
R-CNN速度慢在哪里?
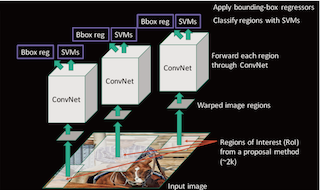
R-CNN慢就慢在要对每个候选区域进行卷积提取特征,上面R-CNN详解中提到选择搜索算法(selective search)会有2000个候选区域。由此可见这里面的卷积操作需要花费很多时间。
SPPNet的改进
●减少卷积运算
●防止图片变形
除了卷积运算多之外,R-CNN中候选区域的图片还需要变形,影响准确率。

SPPNet不同于R-CNN的第一个地方是先整张图片进行卷积运算,然后得到一个feature map(特征图)。然后每个候选区域与feature map映射,得到每个候选区域的特征向量。因为这些特征向量的大小都是不一样的,因此添加一个SSP(spatial pyramid pooling)层。SSP层可以接收任何大小的特征图输入,但是会输出固定大小的特征向量,然后再传递到全连接层。
候选区域与feature map映射过程
原图一方面是经过卷积得到一个feature map,另一方面是经过SS(选择性搜索)得到候选区域,现在要将候选区域与feature map进行映射:

映射是通过图中的坐标点来实现的,这里有个计算公式:
●左上角的点
x’=(X/S)+1
●右下角的点
x’=(X/S)-1
这里是S是所有stride(步长)的乘积,包括卷积,池化的步长。论文中设定的S为16。
论文地址
左上角的点坐标为(Xmin,Ymin),右下角的点坐标为(Xmax,Ymax)。所以计算上会有不一样。
SSP层
SSP层的任务是将任意大小的特征图转换成固定大小的特征向量。
假设原图输入是224x224,对于conv出来后的输出是13x13x256的,可以理解成有256个这样的Filter,每个Filter对应一张13x13的feature map。接着在这个特征图中找到每一个候选区域映射的区域,spp layer会将每一个候选区域分成1x1,2x2,4x4三张子图,对每个子图的每个区域作max pooling,得出的特征再连接到一起,就是(16+4+1)x256的特征向量,接着给全连接层做进一步处理,如下图:
子图的max pooling操作,以4X4为例:

划分了16张子图,取每张子图的max像素值。所以4x4会得出16个特征向量。加上2x2,1x1的一共就是21x256个特征向量。
总结
先来看完整的SPPNet结构图

SPPNet在R-CNN的基础上做出了改进,减少了卷积运算时间。但是训练依然很慢,特征依然需要写入磁盘,仍需要分阶段训练SVM,Bounding box回归器等。
END
