在介绍常见的数据集划分原则前,我们先看一下为什么要对数据集进行划分。
首先,我们进行模型验证的一个重要目的是要选出一个最合适的模型,对于监督学习而言,我们希望模型对于未知数据的泛化能力强,所以就需要模型验证这一过程来体现不同的模型对于未知数的表现效果。 最先我们用训练准确度(用全部的数据进行训练和测试)来衡量模型的表现,这种方式会导致模型过拟合;为了解决这一问题,需要将所有数据划分成训练集和测试集两部分,用训练集进行模型训练,得到的模型再用测试机来衡量模型的预测表现能力,这种度量方式叫测试准确度,这种方式可以有效避免过拟合。
常见的训练集和测试集划分原则有:交叉验证法、留出法。
一、K折 交叉验证
测试准确度的一个缺点是过度依赖测试集,不同的测试集表现效果不尽相同,而交叉验证的基本思想是:将数据集进行一系列分割,生成一组不同的训练测试集,然后分别训练模型并计算测试准确率,最后对结果进行平均处理。这样来有效降低测试准确率的差异。
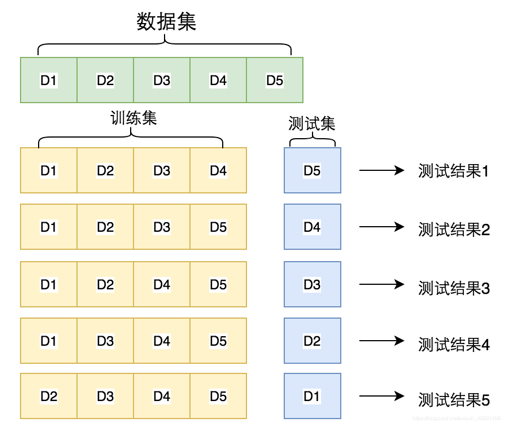
交叉验证是将数据集D划分成k个大小相似的互斥子集,每次都用其中k-1个子集的并集作为训练集,余下那个子集作为测试集。这样就会有k次划分,k次训练。最终结果是返回k个测试结果的均值。通常把交叉验证法称为“k折交叉验证”,k最常用的取值是10,此时称为10折交叉验证。
步骤:
(1)不重复抽样,将原始数据随机划分为k份
(2)每次挑选其中1份作为测试集,剩余k-1份作为训练集
(3)重复第二步 k 次,这样每个子集都有一次机会作为测试集,其余机会作为训练集
(4)计算 k 组测试结果的平均值作为模型精度的估计,并作为当前 k 折交叉验证下模型的性能指标
下图展示了5折交叉验证的训练示意图
K的取值:
(1)数据量小的时候,k可以设大一点,这样训练集占整体比例就比较大,不过同时训练的模型个数也增多。
(2)数据量大的时候,k可以设小一点。
k折验证的目的包括特征选取、模型选取、还是调参
二、留出法
留出法是将数据集D划分成两个互斥集合,为了尽可能保持数据分布的一致性,通常使用分层采样的方式,以7:3的比例划分训练集和测试集。单次使用留出法得到的结果往往不够稳定可靠,不同的训练集测试集划分会导致模型评估标准不同,一般都会进行多次随机划分,例如100次试验评估就会得到100个结果,留出法取这100个结果的平均。
