计算机科学速成课 Crash Course Computer Science
第九集 高级CPU设计 Advanced CPU Design
早期计算机的提速方式是减少晶体管的切换时间,晶体管组成了逻辑门,ALU以及其他组件,但这种提速方式最终会碰到瓶颈,所以处理器厂商发明各种新技术来提升性能,不但让简单指令运行更快,也让它能进行更复杂的运算。
现代CPU直接在硬件层面设计了除法,可以直接给ALU除法指令,这使得ALU更大也更复杂,但也更厉害了。复杂度 VS 速度的平衡在计算机发展史上经常出现。例如现代处理器有专门电路来处理图形操作,解码压缩视频,加密文档等,如果用标准操作来实现则需要很多个时钟周期。某些处理器有MMX,3DNOW,SSE,它们有额外电路做更复杂的操作,用于游戏和加密等场景。
如何快速传递数据给CPU?
指令不断增加,人们一旦习惯了它的便利就很难删掉,所以为了兼容旧指令集,指令数量越来越多。英特尔4004——第一个集成CPU有46条指令,足够做一台能用的计算机。但现代处理器有上千条指令,有各种巧妙复杂的电路,超高的时钟速度带来另一个问题:如何快速传递数据给CPU?
RAM成了瓶颈(bottleneck),RAM是CPU之外的独立组件,意味着数据要用线来传递——总线(bus),总线可能只有几厘米,电信号的传输接近光速,但是CPU每秒可以处理上亿条指令,很小的延迟也会造成问题。RAM还需要时间找地址,取数据,配置,输出数据,一条“从内存读数据”的指令可能要多个时钟周期,CPU空等数据。
缓存
解决延迟的方法之一是给CPU加一点RAM——缓存(cache)。因为处理器里的空间不大,所以缓存一般只有KB或者MB,而RAM都是GB起步的。缓存提高了速度,CPU从RAM拿数据时,RAM不用传一个,可以传一批,虽然花的时间久一点,但是数据可以存在缓存。这很实用因为数据常常是一个个按顺序处理的。因为缓存离CPU近,一个时钟周期就能给数据,所以CPU不需要空等,比起反复去RAM拿数据快得多。
如果想要的数据已经在缓存中,称为缓存命中(cache hit),如果想要的数据不在缓存,称为缓存未命中(cache miss)。缓存也可以当临时空间存一些中间值,适合又长又复杂的运算。计算中间值时,数据不是直接存到RAM,而是存在缓存,这样不但存起来快一些,如果还要接着算,取值也快一些,但是这样会带来一个问题:缓存和RAM的数据不一致,这种不一致必须记录下来,之后要进行同步。因此缓存里每块空间有一个特殊标记——脏位(dirty bit)。同步一般发生在当缓存满了而CPU又要缓存时,在清理缓存腾出空间之前,会先检查脏位,如果是脏的(有数据不一致),在加载新内容之前会把数据写回RAM。
流水线
另一种提升性能的方法叫“指令流水线”(instruction pipelining),取址–解码–执行 不断重复,这种设计需要三个时钟周期执行1条指令,但是因为每个阶段用的是CPU的不同部分,这意味着可以并行处理,“执行”一个指令的同时可以“解码”下一个指令,“读取”下下个指令。不同任务重叠进行,同时用上CPU里所有部分,这样的流水线每个时钟周期执行1个指令,吞吐量*3。
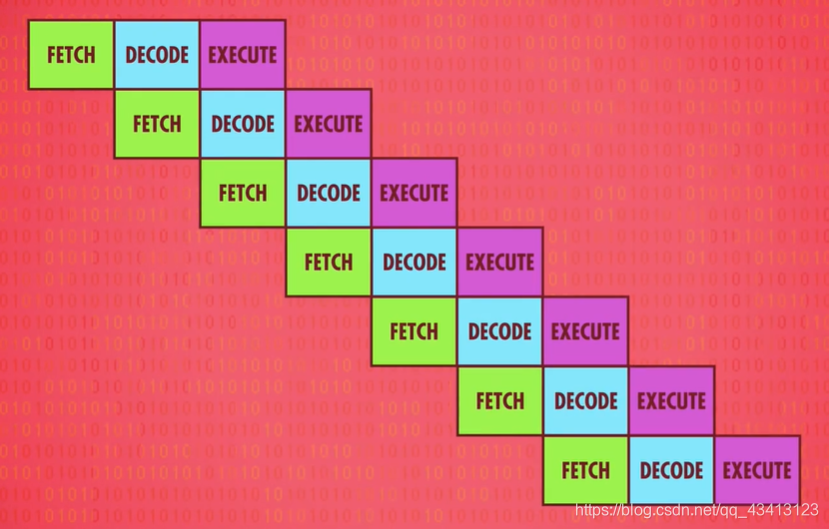
和缓存一样,这也会带来一些问题,第一个问题是指令之间的依赖关系,例如在读某个数据而正在执行的指令会改变这个数据,也就是说拿的是旧数据。因此流水线处理器需要先弄清楚数据依赖性,必要时停止流水线以避免出问题。高端CPU如笔记本和手机里的那种会更进一步,动态排序有依赖关系的指令,最小化流水线的停工时间,这叫“乱序执行”(out-of-order execution)。这种电路非常复杂,但由于非常高效,几乎所有现代处理器都有流水线。
条件跳转
第二个问题是“条件跳转”,跳转指令会改变程序的执行流,简单的流水线处理器在看到 JUMP 指令时会停一会,等待条件值确定下来,一旦 JUMP 的结果出来了,处理器就继续流水线。因为空等会造成延迟,所以高端处理器会用一些技巧,可以把 JUMP 想成是岔路口,高端CPU会猜哪条路的可能性大一些,然后提前把指令放进流水线,这叫“推测执行”(speculative execution)。当 JUMP 的结果出了,如果CPU猜对了,流水线已经塞满正确指令,可以马上运行,如果CPU猜错了,就要清空流水线。
分支预测
为了尽可能减少清空流水线的次数,CPU厂商开发了复杂的方法,来猜测哪条分支更有可能,叫“分支预测”(branch prediction),现代CPU的正确率超过90%,理想情况下,流水线一个时钟周期完成1个指令,然后“超标量处理器”出现了,一个时钟周期完成多个指令,即便有流水线设计,在指令执行阶段处理器里有些区域还是可能会空闲,例如在执行一个“从内存取值”指令期间,ALU会闲置,所以一次性处理多条指令(取指令+解码)会更好,如果多条指令要CPU的不同部分,就多条同时执行。
我们可以再进一步,加多几个相同的电路执行出现频次很高的指令,比如CPU有四个,八个甚至更多完全相同的ALU,可以同时执行多个数学运算。
多核处理
以上都是优化1个指令流的吞吐量,另一个提升性能的方法是同时运行多个指令流,用多核处理器(multi-core processors),例如双核或四核处理器,意思是一个CPU芯片里,有多个独立处理单元,很像是有多个独立CPU,但因为它们整合紧密所以可以共享一些资源,比如缓存,使得多核可以合作运算。当多核不够时,可以用多个CPU,高端计算机(比如YouTube服务器)需要更多马力让上百人能同时流畅观看。2个或4个CPU是最常见的,但有时人们有更高的性能要求,所以建造超级计算机。
如果要做怪兽级运算例如模拟宇宙形成等,需要强大的计算能力,给普通台式机加几个CPU没有作用。神威·太湖之光有40960个CPU,每个CPU有256个核心,总共超过1千万个核心,每个核心的频率是1.45GHz,每秒可以进行9.3亿亿次浮点数运算,也叫每秒浮点运算次数(floating point math operations per second,FLOPS)。
