计算机科学速成课 Crash Course Computer Science
第三十四集 机器学习&人工智能 Machine Learning & Artificial Intelligence
机器学习算法让计算机可以从数据中学习,然后自行做出预测和决定,能自我学习的程序很有用,比如判断是不是垃圾邮件。虽然有用,但是我们不会说它有人类一般的智能,虽然AI和ML这两个词经常混着用,大多数计算机科学家会说机器学习是为了实现人工智能这个更宏大目标的技术之一。
机器学习和人工智能算法一般都很复杂,所以本集重点讲概念。
分类
简单例子开始,判断飞蛾是月蛾还是帝蛾,这叫分类(classification),做分类的算法叫分类器(classifier)。我们可以使用照片和声音来训练算法,很多算法会减少复杂性,把数据简化成特征(features),特征是用来帮助分类的值。对于之前的飞蛾分类例子,我们用两个特征:翼展和重量。
数据处理
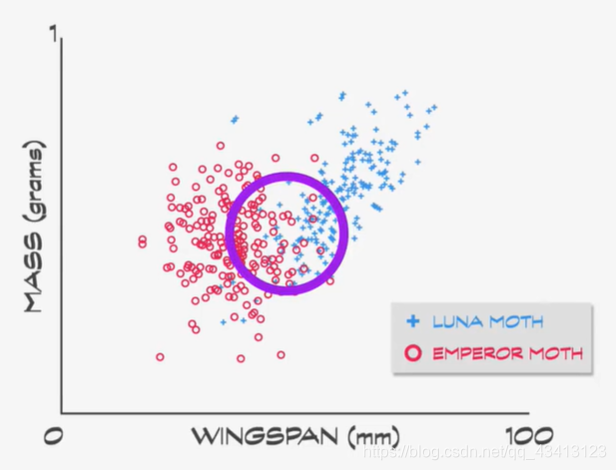
为了训练分类器做出好的预测,我们需要训练数据(training data),专家在记录数据时不只记录特征值,还会把种类也记录,这叫标记数据(labeled data)。因为只有两个特征,很容易用散点图把数据视觉化,可以看出大致分成两组,但是中间有一定重叠,想完全区分两个组比较困难,需要机器学习算法找出最佳区分。
决策
可以肉眼大致估算一下,判断翼展小于45毫米的可能是帝蛾,可以再加一个条件,重量必须小于0.75才算帝蛾,这些线叫决策边界(decision boundaries)。分析数据可知,有86只帝蛾在正确的区域,剩下14只在错误的区域,另一方面有82只月蛾在正确的区域,18只在错误的区域,这个记录正确数和错误数的表叫做混淆矩阵(confusion matrix)。机器学习算法的目的是最大化正确分类并最小化错误分类。
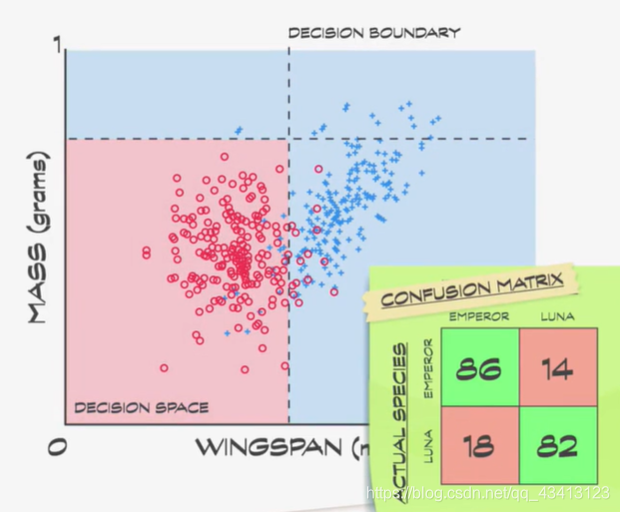
用这些决策边界,如果遇到不认识的飞蛾可以测量它的特征,并绘制在决策空间上,这叫未标签数据(unlabeled data)。决策边界可以猜测飞蛾种类。
决策树
把决策空间切成几个盒子的简单方法可以用决策树(decision tree)来表示,生成决策树的机器学习算法需要选择用什么特征来分类,每个特征用什么值。决策树只是机器学习的一个简单例子,一些算法用多个决策树来预测,计算机科学家称之为森林(forests)。
支持向量机
支持向量机(Support Vector Machine)本质上是用任意线段来切分决策空间,不一定是直线,可以是多项式或其他数学函数。
例子只有两个特征所以人类可以轻松做到(画出决策边界),如果加第3个特征比如触角长度,那么2D线段会变成3D平面,在三个维度上做决策边界,平面不必是直的,而且真正有用的分类器会有很多飞蛾种类。
决策树和支持向量机发源于统计学(statistics),统计学早在计算机出现之前就在用数据做决定,有一大类机器学习算法用了统计学,但也有不用统计学的算法,比如人工神经网络。
人工神经网络
人工神经网络(artificial neural networks)灵感来自于大脑里的神经元。神经元是细胞,用电信号和化学信号来处理和传输消息,它从其他细胞得到一个或多个输入,然后处理信号并发出信号,形成巨大的互联网络,能处理复杂的信息。
人工神经元可以接收多个输入,然后整合并发出一个信号,它们被放成一层层形成神经元网络,因此得名神经网络。回到飞蛾例子,神经网络的第一层是输入层,提供需要被分类的单个飞蛾数据,最后一层为输出层,有两个神经元:分别为帝蛾和月蛾,两个神经元里最为“兴奋”的就是分类结果,中间有一个隐藏层,负责把输入变成输出,即进行分类。
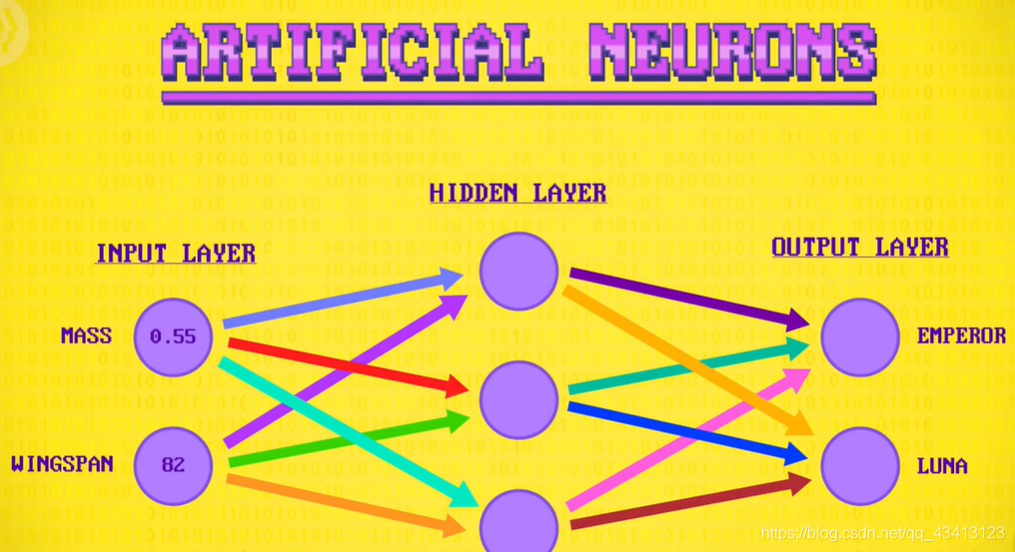
神经元做的第一件事是把每个输入乘以一个权重,对于计算出来的结果用一个偏差值处理,意思是加或减一个固定值,做神经网络时,这些偏差和权重一开始会设置成随机值,然后算法会调整这些值来训练神经网络,使用标记数据来训练和测试,逐渐提高准确性(很像人类学习的过程),最后,神经元有激活函数,称为传递函数,会应用于输出,对结果执行最后一次数学修改,例如把值限制在-1和+1之间,或把负数改成0。加权,求和,偏置,激活函数会应用于一层里的每个神经元,并向前传播。
深度学习
注意:隐藏层可以有很多层,深度学习(deep learning)因此得名。
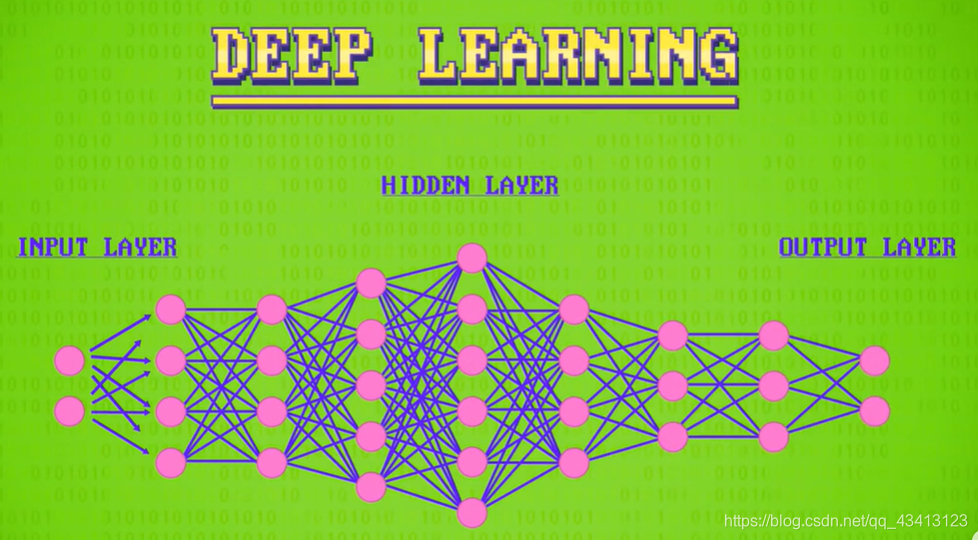
几年前,Google和Facebook展示了深度神经网络在照片中识别人脸的准确率,和人一样高。现在有深度神经网络开车,翻译,诊断医疗状况等等,算法虽然复杂,但是只能做一件事情,这种AI称为“弱AI”(Weak AI)或“窄AI”(Narrow AI),只能做特定任务。
真正通用的像人一样聪明的AI称为“强AI”(Strong AI),数字化知识的爆炸性增长,比如维基百科,网页和YouTube视频将是强AI的完美引燃物,人类一天最多只能看24小时的YouTube,但是计算机可以看上百万小时。比如,IBM的沃森吸收了2亿个网页的内容,包括维基百科的全文,虽然不是强AI但沃森也很聪明,在2011年的知识竞赛中碾压了人类。
强化学习
AI不仅可以吸收大量信息,也可以不断学习进步,而且一般比人类快得多。2016年Google推出AlphaGo,一个会玩围棋的窄AI,它和自己的克隆版下无数次围棋,从而打败了最好的人类围棋选手。学习什么管用,什么不管用,自己发现成功的策略,这叫强化学习(reinforcement learning),是一种很强大的方法,和人类的学习方式非常相似,人类不是天生会走路,是上千小时的试错中学会的。计算机现在才刚学会反复试错来学习,对于很多狭窄的问题,强化学习已经被广泛使用,有趣的是,如果这类技术可以更广泛地应用,创造出类似人类的强AI,能像人类一样学习但是学习速度超快,这对人类可能有相当大的影响。
