大数据集群准备工作
准备工作
1、 关闭防火墙/etc/init.d/iptables stop
chkconfig iptables off
2、 关闭selinux
3、修改主机名
4、ssh无密码拷贝数据
特别说明(在主节点无密码访问到从节点)
ssh-keygen
ssh-copy-id 192.168.100.201
ssh-copy-id 192.168.100.202
ssh-copy-id 192.168.100.203
5、设置主机名和IP的对应
vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost
localhost.localdomain localhost6 localhost6.localdomain6 192.168.100.201 node01 192.168.100.202 node02
192.168.100.203 node03
6、jdk1.8 安装
大数据集群安装部署
1、大数据安装包上传解压
2、配置hadoop环境变量
新建文件/etc/profile.d/hadoop.sh,编译一下内容分
export HADOOP_HOME=/export/servers/hadoop-2.6.0-cdh5.14.0 export PATH=$PATH:$HADOOP_HOME/bin
3、修改hadoop系统配置文件(在讲义中复制粘贴)
core-site.xml Hadoop的核心配置文件
hdfs-site.xml 存储组件的核心配置文件
mapred-site.xml 计算组件的核心配置文件
yarn-site.xml 资源调度的核心配置文件
4、验证hadoop支持哪些算法
./hadoop checknative
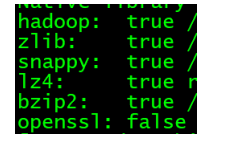
若openssl 不支持,则需要安装
yum -y install openssl-devel

5、安装包分发
scp -r hadoop-2.6.0-cdh5.14.0 node02:$PWD
scp -r hadoop-2.6.0-cdh5.14.0 node03:$PWD
6、hadoop环境变量配置分发
scp -r /etc/profile.d/hadoop.sh node02:/etc/profile.d/
scp -r /etc/profile.d/hadoop.sh node03:/etc/profile.d/
7、集群格式化(在主节点,hadoop的安装路径下 bin里 )
./hdfs namenode -format
8、集群启动(进入/export/servers/hadoop-2.6.0-cdh5.14.0/sbin)
执行启动
./start-all.sh
9、集群启动验证
主节点 jps
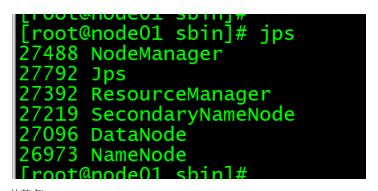
从节点jps

集群启动
在hadoop安装目录的sbin下执行
./start-all.sh 正常启动集群

正常的关闭集群

哪个节点的服务出现异常,就到哪个节点的log下面找对应的日志
所有的启动信息(有异常或无异常)都包含在日志中
集群不要轻易的去格式化(格式化后集群的所有数据都被删除且无法恢复)
验证集群是否可用
jps 用于验证集群服务的启动情况
1、namenode所在节点的IP+50070端口 查看HDFS的web界面是否可用
2、在HDFS系统中创建一个文件夹或文件,若能创建表示集群可以
HDFS不支持目录或文件夹切换,所有路径必须写成结对路径
HDFS权限与linux 的权限等完全相同
HDFS 体验
创建文件夹
hadoop fs -mkdir /abc
上传文件
hadoop fs -put /opt/a.txt /abc
查看文件夹内的内容
hadoop fs -ls /abc
