MySQL主从复制:通过主从复制可以实现数据备份、故障转移、MySQL集群、高可用、读写分离等。原理如下:
- 从库生成两个线程,一个I/O线程,一个SQL线程;
- I/O线程去请求主库的binlog,并将得到的binlog日志写到relay log(中继日志) 文件中;
- 主库会生成一个 log dump 线程,用来给从库 i/o线程传binlog;
- SQL 线程会读取relay log文件中的日志,并解析成具体操作,来实现主从的操作一致,而最终数据一致;

MyCat:MyCat主要是通过对SQL的拦截,然后经过一定规则的分片解析、路由分析、读写分离分析、缓存分析等,然后将SQL发给后端真实的数据块,并将返回的结果做适当处理返回给客户端。
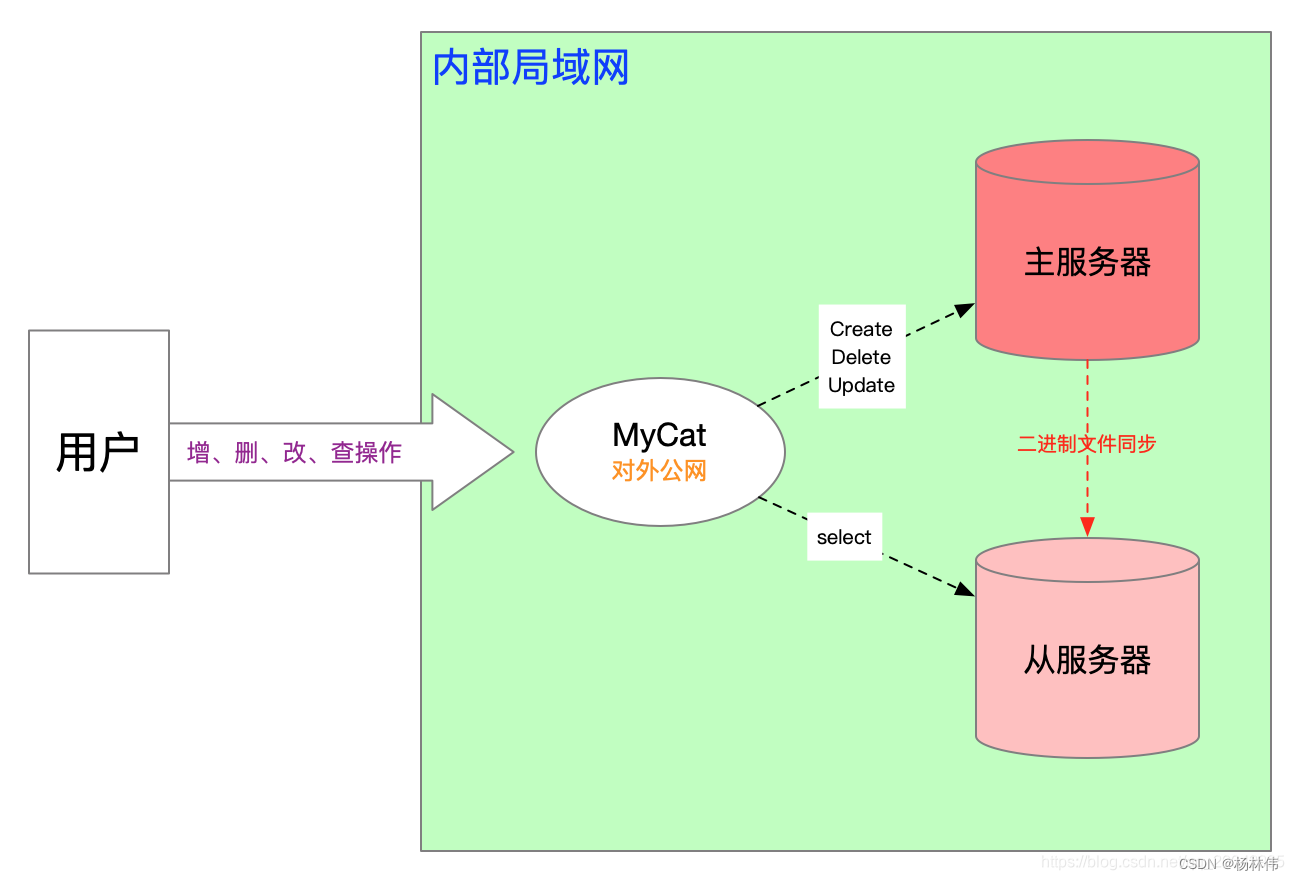
MyCat安装与配置:主要配置解压包的schema.xml文件
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- TESTDB1 是mycat的逻辑库名称,链接需要用的 -->
<schema name="mycat_testdb" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"></schema>
<!-- database 是MySQL数据库的库名 -->
<dataNode name="dn1" dataHost="localhost1" database="test" />
<!--
dataNode节点中各属性说明:
name:指定逻辑数据节点名称;
dataHost:指定逻辑数据节点物理主机节点名称;
database:指定物理主机节点上。如果一个节点上有多个库,可使用表达式db$0-99, 表示指定0-99这100个数据库;
dataHost 节点中各属性说明:
name:物理主机节点名称;
maxCon:指定物理主机服务最大支持1000个连接;
minCon:指定物理主机服务最小保持10个连接;
writeType:指定写入类型;
0,只在writeHost节点写入;
1,在所有节点都写入。慎重开启,多节点写入顺序为默认写入根据配置顺序,第一个挂掉切换另一个;
dbType:指定数据库类型;
dbDriver:指定数据库驱动;
balance:指定物理主机服务的负载模式。
0,不开启读写分离机制;
1,全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡;
2,所有的readHost与writeHost都参与select语句的负载均衡,也就是说,当系统的写操作压力不大的情况下,所有主机都可以承担负载均衡;
-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- 可以配置多个主从 -->
<writeHost host="hostM1" url="192.168.162.132:3306" user="root" password="123456">
<!-- 可以配置多个从库 -->
<readHost host="hostS2" url="192.168.162.133:3306" user="root" password="123456" />
</writeHost>
</dataHost>
</mycat:schema>
数据库分表分库原则:遵循 垂直拆分与水平拆分。
- 垂直拆分:根据不同的业务,分为不同的数据库,比如会员数据库、订单数据库、支付数据库等,垂直拆分在大型电商系统中用的非常常见。缺点是:部分业务表无法join,只能通过接口方式解决,提高了系统复杂度。
- 水平拆分:把同一个表拆到不同的数据库中。可以将数据的水平切分理解为是按照数据行的切分,就是将表中 的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,主要有分表,分库两种模式。水平切分提高了系统的稳定性跟负载能力,但是跨库join性能较差。比如:按时间、哈希、业务规则分表。
MyCat 10种水平分片策略:
- 求模算法:根据id进行十进制求摸运算,运算结果为分区索引,跟ES集群非常相似。
- 分片枚举:比如按照省份或区县来做保存
- 范围约定
- 日期指定
- 固定分片hash算法
- 通配取模
- ASCII码求模通配
- 编程指定
- 字符串拆分hash解析
Sharding-Jdbc:提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。应用场景:
- 数据库读写分离
- 数据库分表分库
SJdbc与MyCat的区别:
- MyCat是一个基于第三方应用中间件数据库代理框架,客户端所有的jdbc请求都必须要先交给MyCat,再有MyCat转发到具体的真实服务器中。
- Sharding-Jdbc是一个Jar形式,在本地应用层重写Jdbc原生的方法,实现数据库分片形式。
- MyCat属于服务器端数据库中间件,而Sharding-Jdbc是一个本地数据库中间件框架。
配置如下:
server:
port: 9002
mybatis-plus:
# mapper-locations: classpath*:/mapper/*.xml
global-config:
db-config:
column-underline: true
#shardingjdbc配置
sharding:
jdbc:
data-sources:
###配置第一个从数据库
ds_slave_0:
password: root
jdbc-url: jdbc:mysql://192.168.212.203:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true
driver-class-name: com.mysql.jdbc.Driver
username: root
###主数据库配置
ds_master:
password: root
jdbc-url: jdbc:mysql://192.168.212.202:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true
driver-class-name: com.mysql.jdbc.Driver
username: root
###配置读写分离
master-slave-rule:
###配置从库选择策略,提供轮询与随机,这里选择用轮询
load-balance-algorithm-type: round_robin
####指定从数据库
slave-data-source-names: ds_slave_0
name: ds_ms
####指定主数据库
master-data-source-name: ds_master
数据库索引:是一种数据结构,用于提高数据库表的检索速度和查询性能。索引是数据库中的一种数据结构,类似于书籍的目录,它提供了一种快速访问表中特定行的方法。通过创建索引,数据库系统可以更有效地执行查询,减少数据扫描的时间,从而加快检索和查询操作。
默认数据与索引文件位置:/var/lib/mysql
索引实现原理:
- hash算法:据关键码值(Key value)而直接进行访问的数据结构,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做
散列函数,存放记录的数组叫做散列表。缺点是不能进行范围查找。 - 平衡二叉树算法:它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值(平衡因子 ) 不超过1。 也就是说AVL树每个节点的平衡因子只可能是-1、0和1(左子树高度减去右子树高度)。优点是平衡二叉树算法基本与二叉树查询相同,效率比较高。缺点是插入操作需要旋转,支持范围查询。
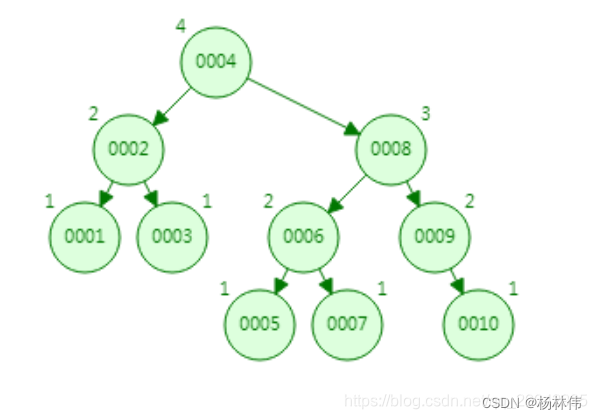
- 数据结构B树:B树(B-tree) 是一种树状数据结构,它能够存储数据、对其进行排序并允许以O(log n)的时间复杂度运行进行查找、顺序读取、插入和删除的数据结构。B树,概括来说是一个节点可以拥有多于2个子节点的二叉查找树。与自平衡二叉查找树不同,B-树为系统最优化大块数据的读和写操作。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。普遍运用在数据库和文件系统

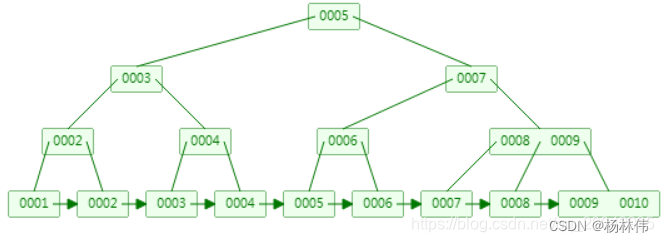
- 数据结构B+树:B+树相比B树,新增叶子节点与非叶子节点关系,叶子节点中包含了key和value,非叶子节点中只是包含了key,不包含value。所有相邻的叶子节点包含非叶子节点,使用链表进行结合,有一定顺序排序,从而范围查询效率非常高。
MyISAM引擎(读多写少,不支持事务):使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。使用表级锁定。不支持事务。
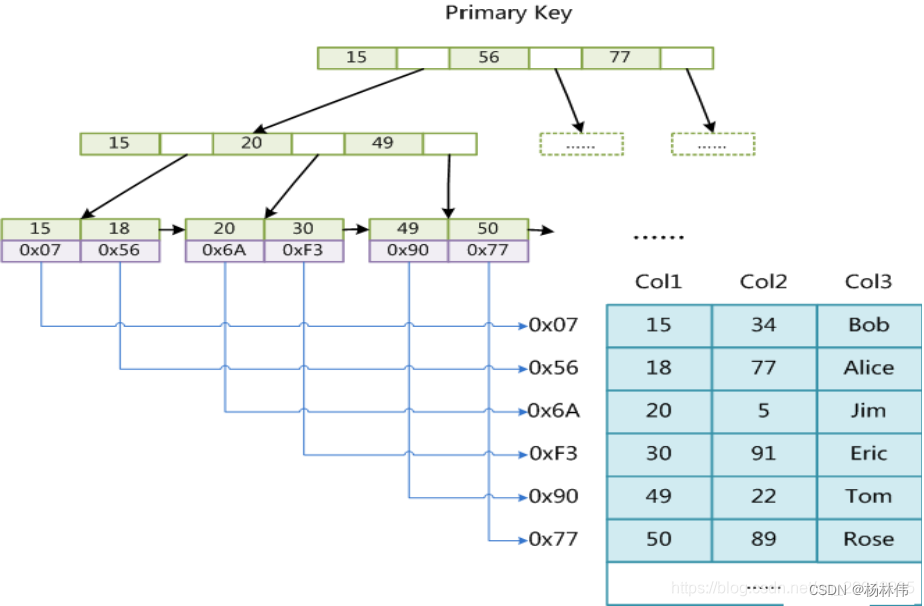
**InnoDB引擎(推荐,写多读少场景,支持事务):**也使用B+Tree作为索引结构,将数据和索引都存储在同一个表空间中。这种存储结构使得InnoDB在处理大量写操作和并发事务时表现得更为优越。使用行级锁定,支持事务。
MySQL优化方案:
- 索引优化
- 慢查询优化:开启慢查询、查询慢查询限制时间(slow_query_log)
- 表优化
explain命令:在解决数据库性能上是第一推荐使用命令,大部分的性能问题可以通过此命令来简单的解决

联合索引左前缀原则:指索引的最左匹配原则。在MySQL中,如果你创建了一个多列索引,查询只能充分利用索引的最左边的列。
举例:
-- 创建了一个复合索引(多列索引)
CREATE INDEX idx_example ON your_table (col1, col2, col3);
-- 索引的最左边的列是col1
-- 以下查询可以使用索引
SELECT * FROM your_table WHERE col1 = 'some_value';
-- 以下查询不能充分利用索引,因为没有涉及到索引的最左边的列
SELECT * FROM your_table WHERE col2 = 'some_value';
因为MySQL在使用索引时,会从索引的最左边开始匹配,并且只有当查询条件涉及到索引的最左边的列时,MySQL才能够充分利用这个索引。
**B+树能够存放多少字节数据:**主要考虑的是B+树的叶子节点能够存储多少数据。B+树的叶子节点包含了实际的索引数据,而非叶子节点只包含索引键值用于导航。

事务传播机制:定义了在一个事务中嵌套调用其他事务时,事务的行为和传播规则。常见的事务传播行为包括:
- REQUIRED(默认):关键词:
必须,表示如果当前存在事务,那么新的操作必须在该事务中进行;如果当前没有事务,将创建一个新的事务。 - REQUIRES_NEW:
需要新的,表示无论当前是否存在事务,都将创建一个新的事务。 - NESTED:
嵌套,表示在当前事务的嵌套事务中执行。 - SUPPORTS:
支持,表示如果当前存在事务,就加入该事务;如果没有事务,以非事务方式执行。 - NOT_SUPPORTED:
不支持,表示以非事务方式执行,如果当前存在事务,将挂起该事务。 - MANDATORY:
强制,表示如果当前存在事务,就加入该事务;如果没有事务,则抛出异常。 - NEVER:
从不,表示以非事务方式执行,如果当前存在事务,将抛出异常。 - TIMEOUT:
超时,表示以相对时间为基准,如果事务在指定时间内没有完成,就回滚事务。
事务隔离级别:
- **READ UNCOMMITTED(未提交读):**事务可以读取其他事务尚未提交的数据,可能导致脏读、不可重复读和幻读问题。
- **READ COMMITTED(已提交读):**特点:事务只能读取其他事务已经提交的数据,解决了脏读问题,但仍可能有不可重复读和幻读问题。
- **REPEATABLE READ(可重复读):**在同一事务中多次读取相同记录时,结果是一致的。解决了脏读和不可重复读问题,但仍可能有幻读问题。
- **SERIALIZABLE(串行化):**最高的隔离级别,通过对数据进行加锁,解决了脏读、不可重复读和幻读的所有问题。但也可能降低并发性能。
- **READ SNAPSHOT(快照读):**事务可以读取一个在事务开始时快照中存在的数据版本,适用于某些数据库系统的特殊实现。事务读取在事务开始时的快照数据,而不受其他事务的影响,避免了脏读、不可重复读和幻读问题。
脏读、不可重复读和幻读:
-
脏读(读写了未提交的):
- 定义: 当一个事务读取了另一个事务未提交的数据时,就发生了脏读。
- 场景: 如果事务A修改了一行数据,但尚未提交,此时事务B读取了这个未提交的数据,就可能导致脏读。
-
不可重复读(读提交之后的):
- 定义: 当一个事务多次读取同一行数据,但在这个过程中另一个事务对该行数据进行了修改并提交,导致事务A读取到不同的数据,就发生了不可重复读。
- 场景: 如果事务A在读取某一行数据后,事务B修改并提交了这一行数据,此时事务A再次读取同一行数据,就可能得到与之前不同的结果。
-
幻读(读一批提交之后的数据):
- 定义: 当一个事务多次查询某个范围的数据,但在这个过程中另一个事务插入或删除了符合这个范围的数据,导致事务A得到不同的结果,就发生了幻读。
- 场景: 如果事务A查询了一个表中的一批数据,而此时事务B插入了一条符合查询条件的新数据,再次查询的结果中会包含这条新插入的数据,就可能发生幻读。
FOR UPDATE :是一种用于在事务中锁定所选行的语句。当你在一个事务中执行
SELECT查询时,如果你希望防止其他事务修改这些数据,可以使用FOR UPDATE。这会在选定的行上设置共享锁,其他事务如果尝试在这些行上执行更新、删除或添加新行的操作,会被阻塞,直到持有锁的事务释放锁。