背景简述
由于学校新开设的一门大数据导论课程,我需要搭建一个Hadoop集群来进行一些大数据相关的坑成设计。而在搭建集群的过程中,我参考了网上的许多教程,但是由于版本不同或是某些叙述不到位或是缺少,导致我在搭建的过程中吃了不少苦头,但最终还是成功完成搭建。完成之后,我有了自己写一片博客的想法以供后学者参考。我不能保证你按照我的做法一定能搭建成功,所以我还会讲一些我自己的解决问题的经验。在我看来,搭建成功固然重要,但你能学到更多东西才更好。
本文主要面向的读者是对于Linux系统所知甚少,并且处于对大数据的初步接触阶段。
搭建流程
建议初次学习的人各种软件尽可能选择相同的版本,尤其是HADOOP,2.X和3.X版本的环境配置存在较大的差异,本文对3.X版本不完全适用。由于更多的是在命令行操作,所以没有进行语言汉化。
1.虚拟机环境搭建及相关文件的下载
首先在VMware Workstation官网上下载软件,然后下载ubantu系统镜像
我将所有软件都安装在F盘中便于管理,但位置可以随你心意。
然后下载Hadoop,下载JDK (下载时需要注册账户)
本人选择的都是官网或知名大学的镜像网站,也可自行选择其他路径下载,一些下载包的版本及格式建议为:ubuntu-18.04.2-desktop-amd64.iso、hadoop-2.8.5.tar.gz、jdk-8u211-linux-x64.tar.gz
至于具体安装过程,属于一键式操作,几乎不存在出故障的可能,不过多叙述。(建议虚拟机名称为master)

2.虚拟机更改下载源
虚拟机第一次启动后,可能会提示进行更新,如果没有,在所有软件里搜索software updater。

点击Settings,在ubantu software中更改download from,选择others,找到china,展开选择一个你喜欢的下载网站,我采用的是阿里云,然后保存更改(点close就好),建议所有软件均更新至最新版。

3.配置JDK和Hadoop相关环境变量
首先将下载的文件拖放到当前用户的根目录下,并解压(右键extract here)至当前文件夹。建议所有机器上的文件放在相同的位置(此处不复制Hadoop也没问题,当时我是为了单机版测试才安装的它)

修改/etc/profile文件,在命令行中使用sudo gedit /etc/profile在文件的最后加上如下代码(命令行中密码不可见,输入后回车即可)修改后保存关闭(出现warning是正常的)。在命令行中输入source /etc/profile。
export JAVA_HOME=/home/z/jdk-12.0.1
export PATH=${JAVA_HOME}/bin:$PATH
- 1
- 2
 现在可以用java -version检查JDK是否已正常安装。
现在可以用java -version检查JDK是否已正常安装。

4.创建Hadoop用户
然后我们最好创建一个专门用于运行Hadoop的账户,以避免权限等诸多问题,有兴趣可自行了解。
先创建用户组hadoop,在添加用户hadoop至hadoop组(回车使用默认信息即可,最后输y)
依次输入sudo addgroup hadoopsudo adduser -ingroup hadoop hadoop

为新创建的hadoop用户添加root权限sudo gedit /etc/sudoers并加入以下代码
hadoop ALL=(ALL:ALL) ALL
- 1

5.配置hostname和hosts文件
修改本机主机名,便于管理。并且为三个节点互联做准备。建议此主机名为master。
sudo gedit /etc/hostname 将ubantu修改为master后保存。
安装net-tools后查看本机IP地址(我的是192.168.100.135)
sudo apt install net-toolsifconfig -a
 然后修改hosts文件(由于ip地址一般顺序分配,我走了一点巧路,提前预测了另两个节点的ip,若与实际不一致,则三台虚拟机均要修改)。输入sudo gedit /etc/hosts,在第三行加入以下内容。
然后修改hosts文件(由于ip地址一般顺序分配,我走了一点巧路,提前预测了另两个节点的ip,若与实际不一致,则三台虚拟机均要修改)。输入sudo gedit /etc/hosts,在第三行加入以下内容。
192.168.100.135 master
192.168.100.136 slave1
192.168.100.137 slave2
- 1
- 2
- 3

6.登入新建的hadoop账户
以后我们都将只对hadoop用户进行操作。一定要注意是root用户,还是Hadoop用户,弄错之后会带来一些问题。
7.SSH的安装
为了减少虚拟机互联时相互身份认证的问题,可以配置ssh免密登陆,首先就要安装ssh。
sudo apt-get install openssh-server,首先尝试登陆本机ssh localhost,登陆成功后使用exit退出登陆。然后将虚拟机关机

8.克隆虚拟机
工具栏->虚拟机->管理->克隆(注意应创建完整克隆)克隆后的虚拟机名称分别命名为slave1和slave2。

开机后,修改克隆得到的两台机器的/etc/hostname文件,分别改为slave1/slave2sudo gedit /etc/hostname (重启后生效)
9.配置SSH免密登陆
现在我们有三台虚拟机了,将它们都开机,直接登陆hadoop用户。用ifconfig查看发现ip地址很不巧的与预期不符,所以修改三台机器的/etc/hosts文件中的ip。修改三台机器相互ping,检查网络是否正常联通。若都能ping通,则开始配置免密登陆。

首先ssh localhost分别登陆本机,然后生成公钥和私钥。方法如下图。

需要输入时直接回车就好。三台机器均要执行。
cd ~/.ssh
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys
- 1
- 2
- 3
三台机器均完成后,将master的authorized_keys追加到另两台机器的authorized_keys文件中。首先将master的authorized_keys传到slave机上。然后再在slave上将master的文件追加。
//master节点上
scp authorized_keys hadoop@slave1:/home/hadoop
scp authorized_keys hadoop@slave2:/home/hadoop
//slave1节点上
cat /home/hadoop/authorized_keys >> ~/.ssh/authorized_keys
//slave2节点上
cat /home/hadoop/authorized_keys >> ~/.ssh/authorized_keys
- 1
- 2
- 3
- 4
- 5
- 6
- 7
现在我们可以尝试在master上免密登陆slave节点了。

10.配置Hadoop完全分布式相关文件
将hadoop安装包复制进虚拟机后,在hadoop账户相同的位置解压Hadoop下载包,在该文件夹下右键打开终端(terminal)输入bin/hadoop version检查Hadoop版本。

现在我们来到了最重要的一步,进行hadoop完全分布式的配置。如果你感兴趣的话可以在命令行下打开文件并修改sudo gedit + 文件名 or 使用vim,如果你不熟悉的话可以直接找到文件再打开,这些文件都在hadoop-2.8.5/etc/hadoop文件夹中。大多数修改都是在文件中configuration和/configuration之间插入内容。
1.修改core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop-2.8.5/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

2.修改hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop-2.8.5/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop-2.8.5/dfs/data</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3.修改mapred-site.xml
首先我们需要将mapred-site.xml.template复制并重命名为mapred-site.xml,然后添加以下内容。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 1
- 2
- 3
- 4
4.修改yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5.修改slaves文件,删除原有内容后修改为以下内容
maste
slave1
slave2
- 1
- 2
- 3
6.打开hadoop-env.sh文件,找到JAVA_HOME,将其修改为我们在安装JDK的路径(对我而言,是/home/z/jdk-12.0.1)
至此,所有的配置工作已经完成,我们需要将配置好的Hadoop传输到另两台机器上。使用的命令为scp -r /home/hadoop/hadoop-2.8.5 hadoop@slave1:/home/hadoop
scp -r /home/hadoop/hadoop-2.8.5 hadoop@slave2:/home/hadoop
现在我们即将开始Hadoop的运行。
完全分布式运行wordcount实例
1.namenode格式化
首先在master上进入Hadoop文件夹后打开终端进行namenode格式化。
hadoop@master:~/hadoop-2.8.5$ bin/hadoop namenode -format
- 1
 注意:上面只要出现“successfully formatted”就表示成功了。
注意:上面只要出现“successfully formatted”就表示成功了。
2.启动Hadoop并检查是否正常启动
hadoop@master:~/hadoop-2.8.5$ sbin/start-all.sh
- 1
使用jps命令检查各部分是否正常,当如下图所示时,启动正常。
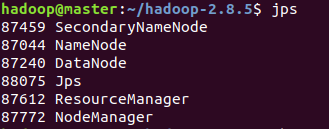
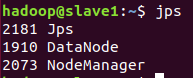
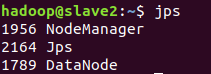
3.创建项目数据文件夹,上传文件,运行,查看结果
我在根目录下放了一个test.txt文件用于测试。文件内容如图。
(在这一部分,运行命令会有许多警告,是由于jdk的版本过高导致的,由于时间原因,暂未换版本,但这些不影响使用)
 使用的命令如下:
使用的命令如下:
hadoop@master:~/hadoop-2.8.5$ bin/hdfs dfs -mkdir /data/input
hadoop@master:~/hadoop-2.8.5$ bin/hdfs dfs -put /home/hadoop/test.txt /data/input
hadoop@master:~/hadoop-2.8.5$ bin/hdfs dfs -ls /data/input
hadoop@master:~/hadoop-2.8.5$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /data/input/test.txt /data/output/counter
hadoop@master:~/hadoop-2.8.5$ bin/hdfs dfs -cat /data/output/counter/part-r-00000
- 1
- 2
- 3
- 4
- 5
结果如图:

4.关闭程序
hadoop@master:~/hadoop-2.8.5$ sbin/stop-all.sh
- 1
使用浏览器可视化管理Hadoop集群
在主节点master的浏览器中分别输入master:8088和master:50070,master可换为主节点虚拟机master的IP地址。如图所示:


结语与致谢
我在安装过程中也有了一些小小的经验,写在这里与大家一起分享。
如果你namanode格式化过程及之后出现了问题,仔细看上面显示的英文,尤其是warning,找到后复制搜索。当你发现解决方案并解决后,最好要把hadoop文件夹中的dfs和tmp文件夹以及logs中的文件清空,否则的话,可能又会产生一些奇怪的错误。
要注意细节,不要拼错文件名,命令名,或是路径(尤其是“/”不能漏)
我认为在整个过程中有许多地方值得我们深入学习:
linux命令行的使用,了解常见的命令及其使用
vim的使用,vim可以在命令行中操作文件,很值得学习
由于我在安装时参考了太多的教程,也询问了一些同学,难以在此一一列出,因而一并感谢。也希望我的文章能对你有帮助。
转载 : https://blog.csdn.net/weixin_45062527/article/details/90183948

背景简述
由于学校新开设的一门大数据导论课程,我需要搭建一个Hadoop集群来进行一些大数据相关的坑成设计。而在搭建集群的过程中,我参考了网上的许多教程,但是由于版本不同或是某些叙述不到位或是缺少,导致我在搭建的过程中吃了不少苦头,但最终还是成功完成搭建。完成之后,我有了自己写一片博客的想法以供后学者参考。我不能保证你按照我的做法一定能搭建成功,所以我还会讲一些我自己的解决问题的经验。在我看来,搭建成功固然重要,但你能学到更多东西才更好。
本文主要面向的读者是对于Linux系统所知甚少,并且处于对大数据的初步接触阶段。
搭建流程
建议初次学习的人各种软件尽可能选择相同的版本,尤其是HADOOP,2.X和3.X版本的环境配置存在较大的差异,本文对3.X版本不完全适用。由于更多的是在命令行操作,所以没有进行语言汉化。
1.虚拟机环境搭建及相关文件的下载
首先在VMware Workstation官网上下载软件,然后下载ubantu系统镜像
我将所有软件都安装在F盘中便于管理,但位置可以随你心意。
然后下载Hadoop,下载JDK (下载时需要注册账户)
本人选择的都是官网或知名大学的镜像网站,也可自行选择其他路径下载,一些下载包的版本及格式建议为:ubuntu-18.04.2-desktop-amd64.iso、hadoop-2.8.5.tar.gz、jdk-8u211-linux-x64.tar.gz
至于具体安装过程,属于一键式操作,几乎不存在出故障的可能,不过多叙述。(建议虚拟机名称为master)
2.虚拟机更改下载源
虚拟机第一次启动后,可能会提示进行更新,如果没有,在所有软件里搜索software updater。
点击Settings,在ubantu software中更改download from,选择others,找到china,展开选择一个你喜欢的下载网站,我采用的是阿里云,然后保存更改(点close就好),建议所有软件均更新至最新版。
3.配置JDK和Hadoop相关环境变量
首先将下载的文件拖放到当前用户的根目录下,并解压(右键extract here)至当前文件夹。建议所有机器上的文件放在相同的位置(此处不复制Hadoop也没问题,当时我是为了单机版测试才安装的它)
修改/etc/profile文件,在命令行中使用sudo gedit /etc/profile在文件的最后加上如下代码(命令行中密码不可见,输入后回车即可)修改后保存关闭(出现warning是正常的)。在命令行中输入source /etc/profile。
export JAVA_HOME=/home/z/jdk-12.0.1
export PATH=${JAVA_HOME}/bin:$PATH
- 1
- 2
现在可以用java -version检查JDK是否已正常安装。
4.创建Hadoop用户
然后我们最好创建一个专门用于运行Hadoop的账户,以避免权限等诸多问题,有兴趣可自行了解。
先创建用户组hadoop,在添加用户hadoop至hadoop组(回车使用默认信息即可,最后输y)
依次输入sudo addgroup hadoopsudo adduser -ingroup hadoop hadoop
为新创建的hadoop用户添加root权限sudo gedit /etc/sudoers并加入以下代码
hadoop ALL=(ALL:ALL) ALL
- 1
5.配置hostname和hosts文件
修改本机主机名,便于管理。并且为三个节点互联做准备。建议此主机名为master。
sudo gedit /etc/hostname 将ubantu修改为master后保存。
安装net-tools后查看本机IP地址(我的是192.168.100.135)
sudo apt install net-toolsifconfig -a
然后修改hosts文件(由于ip地址一般顺序分配,我走了一点巧路,提前预测了另两个节点的ip,若与实际不一致,则三台虚拟机均要修改)。输入sudo gedit /etc/hosts,在第三行加入以下内容。
192.168.100.135 master
192.168.100.136 slave1
192.168.100.137 slave2
- 1
- 2
- 3
6.登入新建的hadoop账户
以后我们都将只对hadoop用户进行操作。一定要注意是root用户,还是Hadoop用户,弄错之后会带来一些问题。
7.SSH的安装
为了减少虚拟机互联时相互身份认证的问题,可以配置ssh免密登陆,首先就要安装ssh。
sudo apt-get install openssh-server,首先尝试登陆本机ssh localhost,登陆成功后使用exit退出登陆。然后将虚拟机关机
8.克隆虚拟机
工具栏->虚拟机->管理->克隆(注意应创建完整克隆)克隆后的虚拟机名称分别命名为slave1和slave2。
开机后,修改克隆得到的两台机器的/etc/hostname文件,分别改为slave1/slave2sudo gedit /etc/hostname (重启后生效)
9.配置SSH免密登陆
现在我们有三台虚拟机了,将它们都开机,直接登陆hadoop用户。用ifconfig查看发现ip地址很不巧的与预期不符,所以修改三台机器的/etc/hosts文件中的ip。修改三台机器相互ping,检查网络是否正常联通。若都能ping通,则开始配置免密登陆。
首先ssh localhost分别登陆本机,然后生成公钥和私钥。方法如下图。
需要输入时直接回车就好。三台机器均要执行。
cd ~/.ssh
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys
- 1
- 2
- 3
三台机器均完成后,将master的authorized_keys追加到另两台机器的authorized_keys文件中。首先将master的authorized_keys传到slave机上。然后再在slave上将master的文件追加。
//master节点上
scp authorized_keys hadoop@slave1:/home/hadoop
scp authorized_keys hadoop@slave2:/home/hadoop
//slave1节点上
cat /home/hadoop/authorized_keys >> ~/.ssh/authorized_keys
//slave2节点上
cat /home/hadoop/authorized_keys >> ~/.ssh/authorized_keys
- 1
- 2
- 3
- 4
- 5
- 6
- 7
现在我们可以尝试在master上免密登陆slave节点了。
10.配置Hadoop完全分布式相关文件
将hadoop安装包复制进虚拟机后,在hadoop账户相同的位置解压Hadoop下载包,在该文件夹下右键打开终端(terminal)输入bin/hadoop version检查Hadoop版本。
现在我们来到了最重要的一步,进行hadoop完全分布式的配置。如果你感兴趣的话可以在命令行下打开文件并修改sudo gedit + 文件名 or 使用vim,如果你不熟悉的话可以直接找到文件再打开,这些文件都在hadoop-2.8.5/etc/hadoop文件夹中。大多数修改都是在文件中configuration和/configuration之间插入内容。
1.修改core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop-2.8.5/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2.修改hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop-2.8.5/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop-2.8.5/dfs/data</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3.修改mapred-site.xml
首先我们需要将mapred-site.xml.template复制并重命名为mapred-site.xml,然后添加以下内容。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 1
- 2
- 3
- 4
4.修改yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5.修改slaves文件,删除原有内容后修改为以下内容
maste
slave1
slave2
- 1
- 2
- 3
6.打开hadoop-env.sh文件,找到JAVA_HOME,将其修改为我们在安装JDK的路径(对我而言,是/home/z/jdk-12.0.1)
至此,所有的配置工作已经完成,我们需要将配置好的Hadoop传输到另两台机器上。使用的命令为scp -r /home/hadoop/hadoop-2.8.5 hadoop@slave1:/home/hadoop
scp -r /home/hadoop/hadoop-2.8.5 hadoop@slave2:/home/hadoop
现在我们即将开始Hadoop的运行。
完全分布式运行wordcount实例
1.namenode格式化
首先在master上进入Hadoop文件夹后打开终端进行namenode格式化。
hadoop@master:~/hadoop-2.8.5$ bin/hadoop namenode -format
- 1
注意:上面只要出现“successfully formatted”就表示成功了。
2.启动Hadoop并检查是否正常启动
hadoop@master:~/hadoop-2.8.5$ sbin/start-all.sh
- 1
使用jps命令检查各部分是否正常,当如下图所示时,启动正常。
3.创建项目数据文件夹,上传文件,运行,查看结果
我在根目录下放了一个test.txt文件用于测试。文件内容如图。
(在这一部分,运行命令会有许多警告,是由于jdk的版本过高导致的,由于时间原因,暂未换版本,但这些不影响使用)
使用的命令如下:
hadoop@master:~/hadoop-2.8.5$ bin/hdfs dfs -mkdir /data/input
hadoop@master:~/hadoop-2.8.5$ bin/hdfs dfs -put /home/hadoop/test.txt /data/input
hadoop@master:~/hadoop-2.8.5$ bin/hdfs dfs -ls /data/input
hadoop@master:~/hadoop-2.8.5$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /data/input/test.txt /data/output/counter
hadoop@master:~/hadoop-2.8.5$ bin/hdfs dfs -cat /data/output/counter/part-r-00000
- 1
- 2
- 3
- 4
- 5
结果如图:
4.关闭程序
hadoop@master:~/hadoop-2.8.5$ sbin/stop-all.sh
- 1
使用浏览器可视化管理Hadoop集群
在主节点master的浏览器中分别输入master:8088和master:50070,master可换为主节点虚拟机master的IP地址。如图所示:
结语与致谢
我在安装过程中也有了一些小小的经验,写在这里与大家一起分享。
如果你namanode格式化过程及之后出现了问题,仔细看上面显示的英文,尤其是warning,找到后复制搜索。当你发现解决方案并解决后,最好要把hadoop文件夹中的dfs和tmp文件夹以及logs中的文件清空,否则的话,可能又会产生一些奇怪的错误。
要注意细节,不要拼错文件名,命令名,或是路径(尤其是“/”不能漏)
我认为在整个过程中有许多地方值得我们深入学习:
linux命令行的使用,了解常见的命令及其使用
vim的使用,vim可以在命令行中操作文件,很值得学习
由于我在安装时参考了太多的教程,也询问了一些同学,难以在此一一列出,因而一并感谢。也希望我的文章能对你有帮助。