本篇文章从HashMap的发展历程进行较为详细的解读,对JDK7、JDK8HashMap都有讲解,并且对ConcurrentHashMap也有一定的讲解。相信我,看了这篇文章,你不需要再去学习HashMap!
主要内容
- 开篇
- 哈希表原理
- JDK7 HashMap(源码解读)
- JDK8 HashMap
- Hashtable
- JDK7 ConcurrentHashMap
- JDK8 ConcurrentHashMap
- 最后的总结和交流
一、开篇
1.1 问题 1:哈希表和 Java 的前世今生是什么
哈希表(hashtable 散列表)是一种数据结构,是一种神奇的数据结构,查询、添加、删除效率非常快,时间复杂度可以达到 O(1)。
Java 的集合中给出了底层结构采用哈希表数据结构的实现类,按照时间顺序分别为第一代Hashtable、第二代 HashMap、第三代 ConcurrentHashMap(concurrent 并发)。相同点:底层结构都是哈希表,都是用来存储 key-value 映射,都实现了 Map 接口。

- Hashtable 线程安全,但是效率太低,底层使用 synchronized 同步方法,
已不再使用。 - HashMap 线程不安全,效率提升,适用单线程情况下。可以借助 Collections. synchronziedMap()保证线程安全,底层使用 synchronized 同步代码块,效率比
Hashtable 高。 - 在大量并发情况下如何提高集合的效率和安全呢? ConcurrentHashMap:JDK7 底
层采用 Lock 锁,但是 JDK8 的 ConcurrentHashMap 不使用 Lock 锁,而是使用了
CAS + synchronized 代码块锁。保证安全的同时,性能均也很高。
注意
- ConcurrentHashMap 推出后,HashMap 并未过时,适用不同场景。两者同时进
行性能提高和结构完善。 - 和三种线程同步技术的发展密切相关
- Hashtable 不可 null key-value,HashMap 可以,ConcurrentHashMap 不可
1.2 问题2:正确认识HashMap的重要性
- 重点:JavaSE 是 Java 的技术基础,集合是 JavaSE 的重点,HashMap 是集合的重点
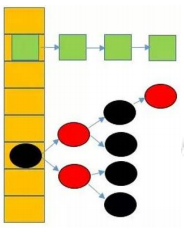
- 难点:综合了数组、链表、红黑树等多种数据结构。
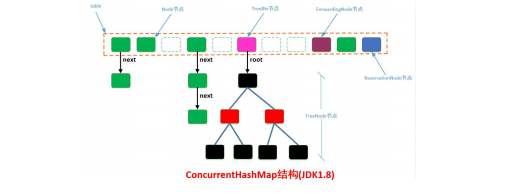
- 新点:HashMap 在 7,8 中有较大变化;ConcurrentHashMap 是新一代并发集合类,在 JDK7、JDK8 中也有很大的变化。
1.3 问题3:23个小问题
对于HashMap的讲解,我罗列了23个小问题,请读者带着这些问题进行阅读,在后面,我会一一的讲解这些知识点。
- 哈希表的由来,她究竟解决了什么问题,为什么神奇。
- 哈希表的原理(结构、添加步骤、查询步骤)
- JDK7 中 HashMap 的关键点(源码解读)
3.1 为什么要把 hash 也放到 Entity 中
3.2 第一步为什么还要多次散列,为什么这样实现
3.3 为什么求索引不使用 h%length,而是使用 h&(length-1)
3.4 为什么主数组的长度必须是 2 的幂
3.5 为什么加载因子选择 0.75
3.6 JDK7 的死循环问题(并不是死锁)
3.7 多线程 put 的时候为什么可能导致元素丢失 - JDK8 中 HashMap 的变化
- JDK8 HashMap 为什么是当链表长度>=8 后变成红黑树,而不是其他值
- Hashtable 和 HashMap 的不同之处
- Hashtable 的缺点
- 为什么 Hashtable 主数组默认长度是 11,为何扩容 2 倍还要+1
- JDK7 ConcurrentHashMap 关键技能点
- JDK7 ConcurrentHashMap 通过无参构造方法创建对象的结果
- Unsafe 类是怎么回事
- JDK7 ConcurrentHashMap 的缺点是什么
- JDK8 中 ConcurrentHashMap 变化
- JDK8 ConcurrentHashMap 怎么放弃 Lock 使用 synchronized 了
- JDK8 中 ConcurrentHashMap 的 sizeCtl 属性的作用
- 折 腾 什 么 ? Hashtable 不 可 存 储 null key-value , HashMap 可 以 ,ConcurrentHashMap 不可
二、哈希表的原理
2.1 问题 1:哈希表的由来,她究竟解决了什么问题,为什么神奇 如何解决数据查询、添加、删除等效率呢?此处以查询为例进行说明。
-
在无序数组中按照内容查找,效率低下,时间复杂度是 O(n)。

-
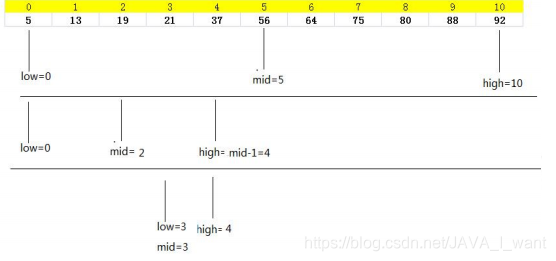
在有序数组中按照内容查找,可以使用折半查找,时间复杂度 O(log2n)
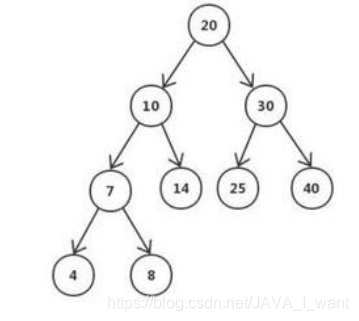
- 在二叉平衡树中按照内容查找,时间复杂度 O(log2n)
- 在数组中按照索引查找,不进行比较和计数,直接计算得到,效率最高,时间复杂度 O(1)

问题:按照内容查找,能否也不进行比较,而是通过计算得到地址,实现类似数组按照 索引查询的高效率呢 O(1)
有!!!哈希表来实现。
前面查找方法共同特点:通过将关键字值与给定值比较,来确定位置。效率取决比较次数。
理想的方法是:不需要比较,根据给定值能直接定位记录的存储位置。
这样,需要在记录的存储位置与该记录的关键字之间建立一种确定的对应关系,使每个记录的关键字与一个存储位置相对应。
2.2 问题 2:哈希表的原理(结构、添加步骤、查询步骤)
1. 哈希表的结构和特点
- hashtable 也叫散列表
- 特点:快 很快 神奇的快
- 结构:结构有多种
- 最流行、最容易理解:顺序表+链表
- 主结构:顺序表
- 每个顺序表的节点在单独引出一个链表
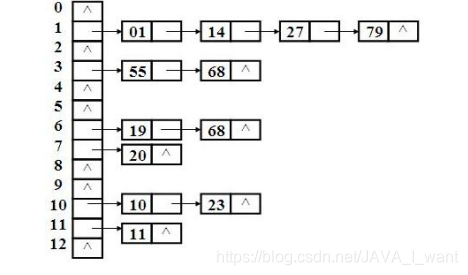
桶 bucket :每个元素后面可以拉一个链表,成为一个桶。
bucketIndex:桶索引。数组元素的索引。
2. 哈希表是如何添加数据的
- 计算哈希码(调用 hashCode(),结果是一个 int 值,整数的哈希码取自身即可)
- 计算在哈希表中的存储位置 y=k(x)=x%11
x:哈希码 k(x) 函数 y:在哈希表中的存储位置 (位置就是数组的索引) - 存入哈希表
- 情况 1:一次添加成功
- 情况 2:多次添加成功(出现了冲突(碰撞 collision),调用 equals()和对应链表
的元素进行比较,比较到最后,结果都是 false,创建新节点,存储数据,并加入
链表) - 情况 3:不添加(出现了冲突,调用 equals()和对应链表的元素进行比较, 经过
一次或者多次比较后,结果是 true,表明重复,不添加)
结论 1:哈希表添加数据快(3 步即可,不考虑冲突)
结论 2:唯一
结论 3:无序
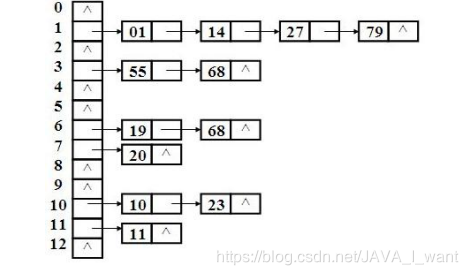
3. 哈希表是如何查询数据的
和添加数据的过程是相同的
- 情况 1:一次找到 23 86 76
- 情况 2:多次找到 67 56 78
- 情况 3:找不到 100 200
结论 1:哈希表查询数据快
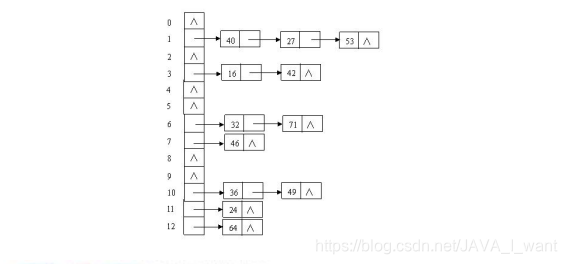
三、JDK7 HashMap
3.1 问题 3:JDK7 中 HashMap 的关键点
-
JDK7 及之前,HashMap 底层是一个 table 数组+链表的哈希表存储结构
-
链表上每个节点的就是一个 Entry,字段包括四部分

-
默认主数组长度 16;
-
主数组的长度可以直接指定,但最终长度会变为刚刚大于指定值的 2 的幂。
-
默认装填因子 0.75(元素个数达到主数组长度 75%时扩容)
-
每次主数组扩容为原来的 2 倍
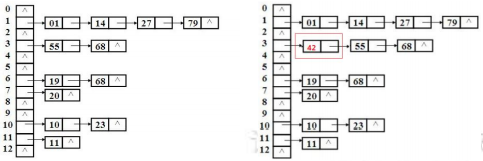
- 发生冲突,经过比较不存在相同 key 的元素,要添加一个新的节点。不是加
到链表最后,而是添加到链表最前 - 发生冲突,经过比较存在相同 key 的元素,使用新的 value 替换旧的 value,
并返回旧的 value。
3.2 源码阅读(JDK7)
- 如果 key 是 null,直接存入到索引是 0 的桶中。不进行第一步和第二步操作。

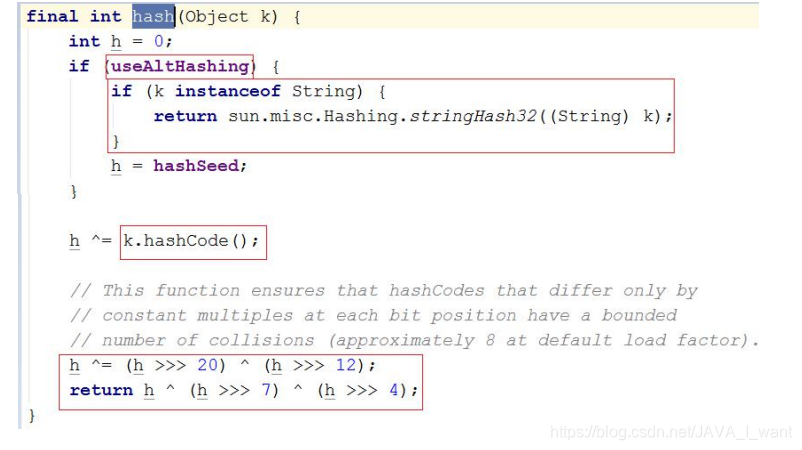
-
第一步计算哈希码,不仅调用了 hashCode(),又进行了多次散列。目的在于key 不同,哈希码尽量不同,减少冲突。极端情况下,对 String 的哈希值的判断,采用 JDK 内部的特殊算法计算。了解即可。
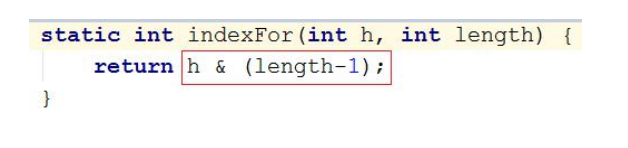
-
第二步,计算存储位置,使用了位运算来提高效率
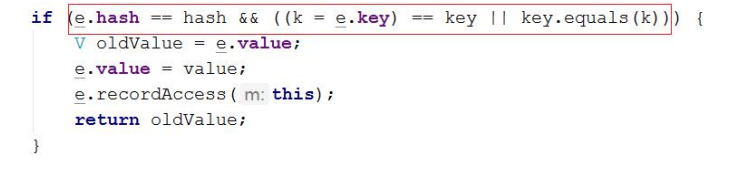
- 第三步判断 key 是否存在的条件是比较哈希码 && 内容。其实直接调用equals()即可,这个条件是为了提高效率。
- 扩容的条件是:节点数量达到阈值 && 新元素的位置已经有节点

尽量减少扩容的次数,因为扩容会导致原来的节点要重新散列到新数组的位置。如果能够预估到节点的数量,可以直接指定哈希表主数组的长度。
-
真正的扩容是由 transfer()实现的。扩容需要重新创建一个新的哈希表(主数组),原来的节点 Entry 都要重新计算存储位置并添加到新哈希表中。

-
发生冲突,经过比较不存在相同 key 的元素,要添加一个新的节点。不是加到链表最后,而是添加到链表最前

3.3 更多的细节问题
问题 3-1:为什么要把 hash 也放到 Entity 中
- 扩容时不用重新计算 hash,省去第一步,直接使用来计算存储位置即可
- 判断 key 是否存在时,可以先判断 hash,只是一个整数,效率高。Hash 不同,直接短路,提高效率。
问题 3-2:第一步为什么还要多次散列,为什么这样实现
目的:保证高低 bit 位都能参与到 Hash 的计算中,一句话就是为了减少 hash 冲突的几率。保证在默认的加载因子下,每个链表的长度一般不会超过 8.
问题 3-3:为什么求索引不使用 h%length,而是使用 h&(length-1)
使用位运算可以提升效率。直接取模,如果 h 是负数,计算的索引会是负数
问题 3-4:为什么主数组的长度必须是 2 的幂
因为计算存储位置的公式:h&(length-1)。如果主数组的长度不是 2 的幂,该表达式实现不了取模的效果。

保证 length-1 的二进制的低 x 位都是 1,进行&运算。因为 0&1=0,1&1=1,可以让 h 的低 x 位值完整保存下来,正好作为余数,还不冲突。
如果 length 不是 2 的幂,使用该表达式会导致不同数据产生相同哈希码,进而导致地址冲突。

问题 3-5:为什么加载因子选择 0.75
源码原文如下:

翻译:
通常,默认负载因子(0.75)在时间和空间成本之间提供了一个很好的权衡。 较高的值会减少空间开销,但会增加查找成本。 设置其初始容量时,应考虑映射中的预期条目数及其负载因子,以最大程度地减少重新哈希操作的数量。 如果初始容量大于最大条目数除以负载因子,则不会发生任何哈希操作。
问题 3-6:JDK7 的死循环问题(并不是死锁)
这也是为什么 JDK8 对 HashMap 进行大手术的原因所在。问题出在 HashMap 扩容时。扩容对用户是透明的,却是一切坑的原因。

因为 JDK7 的新节点是添加到链表头部,导致重新散列后,链表的节点顺序会颠倒。如果是单线程情况下,这不算问题。
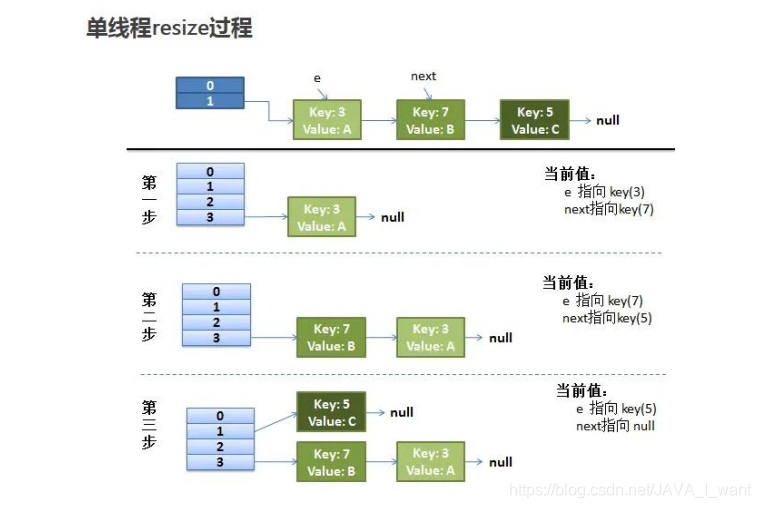
多线程扩容时,同时执行 transfer 方法,可能扩容后形成循环列表。如果下步要查询get()一个不存在的 key,或者 put 不存在的 key,悲剧出现了——Infinite Loop。
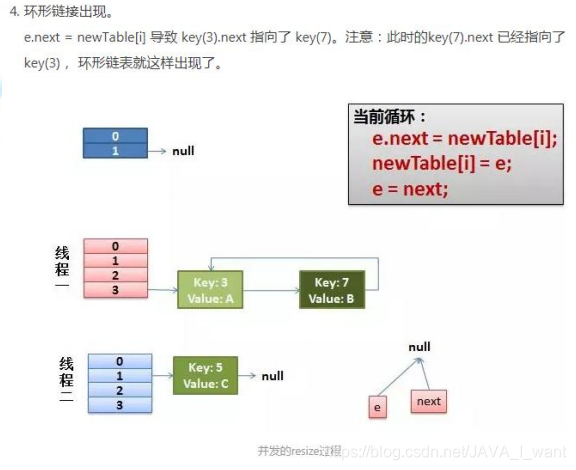
参考:https://www.jianshu.com/p/e1c020d37c6a
问题 3-7 多线程 put 的时候为什么可能导致元素丢失
主要问题出在 addEntry 方法的 new Entry (hash, key, value, e),如两个线程都同时取得了 e,则他们下一个元素都是 e,然后赋值给 table 元素时有一个成功有一个丢失。
虽然 HashMap 是线程不安全的,还是有人在多线程情况下用,其实是开发者自己的原因。有人把这个问题报给了 Oracle,不过 Oracle 起初不认为这是一个问题。因为 HashMap 本来就不支持并发。要并发就用 ConcurrentHashmap 或者使用 Collections 类的synchronizedMap()方法来同步。别看 Oracle 嘴硬,在 JDK8 中还是进行了修补。
