在哈希表和 Java 的前世今生(上),掌握HashMap看这一篇就够了!!! 中,我们讲解了哈希表的原理以及JDK7 HashMap的源码及JDK7中HashMap的注意点。
在哈希表和 Java 的前世今生(中),掌握HashMap看这一篇就够了!!!中,我们讲解了JDK8 HashMap的源码,以及其与JDK7 HashMap的区别。
在哈希表和 Java 的前世今生(下),掌握HashMap看这一篇就够了!!!中 我们讲解了 Hashtable与HashMap的区别以及JDK7 ConcurrentHashMap的原理以及源码解读
今天是本次HashMap的最后一篇讲解,主要讲解JDK8 ConcurrentHashMap的原理以及源码解读
七、JDK8 中 ConcurrentHashMap
7.1 问题 13:JDK8 中 ConcurrentHashMap 变化
-
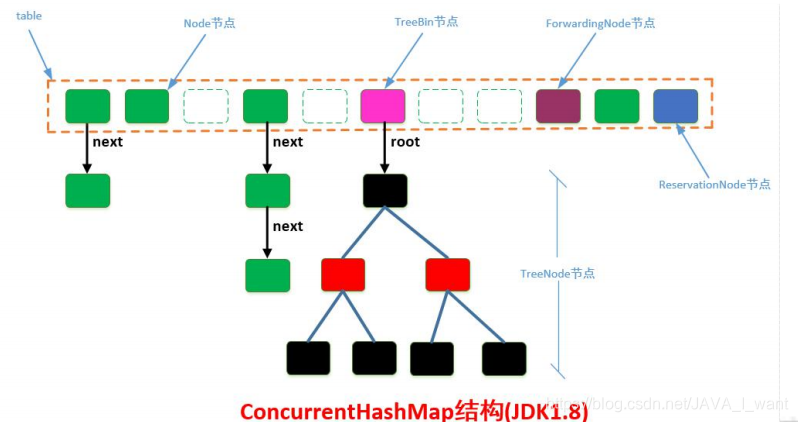
结构简单:JDK8 抛弃 JDK7 的 Segment 分段锁机制,由 JDK7 的两级数组变回了原来的一级数组。链表长度>=8,该链表转换为红黑树。
-
降低锁的粒度:锁住数组的每个桶的头结点,锁粒度更小。(Hashtable 是锁住整个表、JDK7 的 ConcurrrentHashMap 是锁住一个段 Segment。而这里是锁住一个链表或者一个红黑树)
-
锁变化:不使用 Segment 锁(继承 ReentrantLock),利用 CAS+Synchronized来保证并发安全。
-
并发扩容,多个线程参与。(JDK7 的 ConncurrentHashMap 的 Segement 数组长度固定不扩容,扩容的每个 HashEntry 数组的容量,此时不需要考虑并发,因为到这里的时候,是持有该 Segment 的独占锁的)
注意:JDK8 中,Segment 类依旧存在,但只是为了兼容,只有在序列化和反序列化时才会被用到
- 更多的 Node 类型
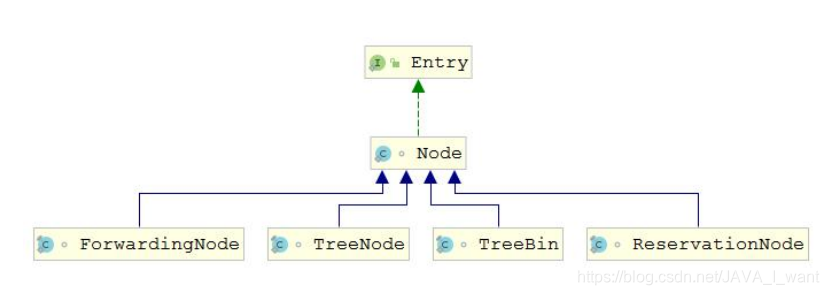
a. Node<K,V>:基本结点/普通节点。当 table 中的 Entry 以链表形式存储时才使用,存储实际数据。该类的 key 和 value 不为 null(其子类可为 null)
b. TreeNode:红黑树结点。当 table 中的 Entry 以红黑树的形式存储时才会使用,存储实际数据。ConcurrentHashMap 中对 TreeNode 结点的操作都会由 TreeBin 代理执行。
c. TreeBin:代理操作 TreeNode 结点。该节点的 hash 值固定为-2,存储实际数据的红黑树的根节点。因为红黑树进行写入操作整个树的结构可能发生很大变化,会影响到读线程。因此 TreeBin 需要维护一个简单的读写锁,不用考虑写-写竞争的情况。当然并不是全部的写操作都需要加写锁,只有部分put/remove 需要加写锁。
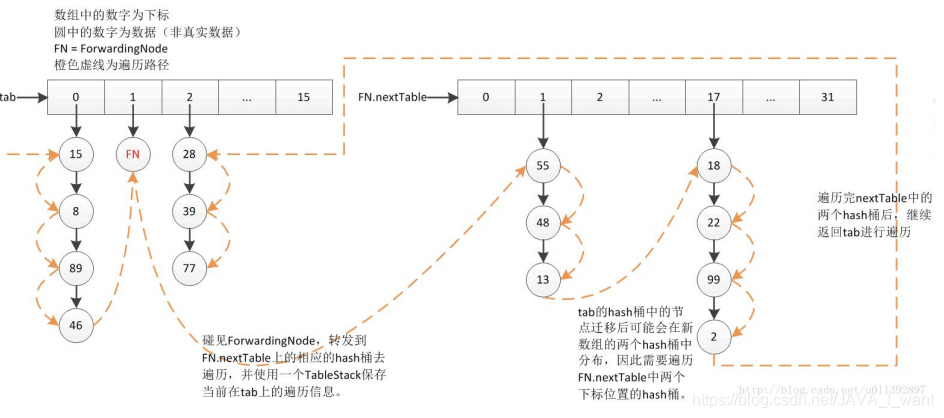
d. ForwardingNode:转发结点。该节点是一种临时结点,只有在扩容进行中才会出现,该节点的 hash 值固定为-1,并且它不存储实际数据。如果旧 table的一个 hash 桶中全部结点都迁移到新的数组中,旧 table 就在桶中放置一个ForwardingNode。当读操作或者迭代操作遇到 ForwardingNode 时,将操作转发到扩容后新的 table 数组中去执行,当写操作遇见 ForwardingNode时,则尝试帮助扩容。
e. ReservationNode:保留结点,也被称为空节点。该节点的 hash 值固定为-3,不保存实际数据。正常的写操作都需要对 hash 桶的第一个节点进行加锁,如果 hash 桶的第一个节点为 null 时是无法加锁的,因此需要 new 一个ReservationNode 节点,作为 hash 桶的第一个节点,对该节点进行加锁。
7.2 问题 14:JDK8 ConcurrentHashMap 怎么放弃 Lock 使用 synchronized 了
-
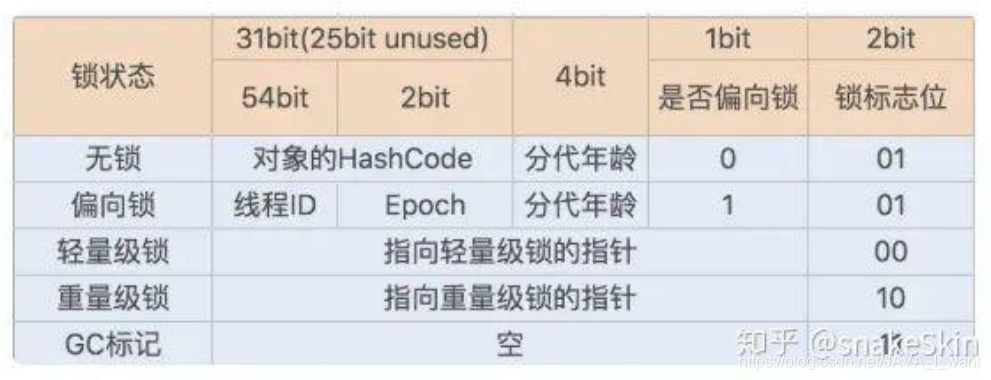
synchronized 之前一直都是重量级锁,但是 JDK6 中官方是对他进行过升级,引入了偏向锁,轻量级锁,重量级锁,现在采用的是锁升级的方式去做的。针对synchronized 获取锁的方式,JVM 使用了锁升级的优化方式,就是先使用偏向锁优先同一线程然后再次获取锁,如果失败,就升级为 CAS 轻量级锁,如果失败就会短暂自旋,防止线程被系统挂起。最后如果以上都失败就升级为重量级锁。所以是一步步升级上去的,最初也是通过很多轻量级的方式锁定的。
-
ReentantLock 是 JDK 层面的,synchronized 是 JVM 层面的。相对而言,synchronized 的性能优化空间更大,这就使得 synchronized 能够随着 JDK 版本的升级而不改动代码的前提下获得性能上的提升。
-
另外此处 synchronized 锁住的是单个链表的头结点,粒度小,而不是 Hashtable、Collections 等锁整个哈希表。低粒度下,synchronized 和 Lock 的差异没有高粒度下明显。
对象头 Mark Word(标记字段)
| 锁 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 偏向锁 | 加锁和解锁不需要额外的消耗,和执行非同步方法比仅存在纳秒级的差距 | 如果线程间存在锁竞争,会带来额外的锁撤销的消耗 | 适用于只有一个线程访问同步块场景 |
| 轻量级锁 | 竞争的线程不会阻塞,提高了程序的响应速度 | 如果始终得不到锁,竞争的线程使用自旋会消耗 CPU | 追求响应时间,锁占用时间很短 |
| 重量级锁 | 线程竞争不使用自旋,不会消耗 CPU | 线程阻塞,响应时间缓慢 | 追求吞吐量,锁占用时间较长 |
7.3 问题 15:sizeCtl 属性的作用
sizeCtl 属性是 ConcurrentHashMap 中出镜率很高的一个属性,因为它是一个控制标识符,在不同的地方有不同用途,而且它的取值不同,也代表不同的含义。
- -1 代表正在初始化
- -N 表示有 N-1 个线程正在进行扩容操作
- 正数或 0 代表 hash 表还没有被初始化,这个数值表示初始化或下一次进行扩容的大小,这一点类似于扩容阈值的概念。还后面可以看到,它的值始终是当前ConcurrentHashMap 容量的 0.75 倍,这与 loadfactor 是对应的。
7.4 问题 16:折腾什么?Hashtable 不可存储 null key-value,HashMap可以,ConcurrentHashMap 不可
其实你发现 Hashtable、ConcurrentHashMap 不允许 null,但是都是线程安全的,适用于多线程环境。而 HashMap 却是线程不安全的,适用于单线程环境。和此有关吗?其实有关系的。
无法容忍的歧义。如果 map.get(key) return null,是 key 不存在呢,还是 value 是null 呢?单线程情况下可以区分,可以通过先调用 map.contains(key)来辨别,但在并行映射中,两次调用 map.contains(key)和 map.get(key) 之间,映射可能已更改。
7.5 JDK8 ConcurrentHashMap 源码阅读:put( )
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key 和 value 均不能为空
if (key == null || value == null) throw new NullPointerException();
// 得到 hash 值
int hash = spread(key.hashCode());
// 用于记录相应链表的长度
int binCount = 0;
for (Node<K, V>[] tab = table; ; ) {
Node<K, V> f;
int n, i, fh;
// 如果数组"空",进行数组初始化
if (tab == null || (n = tab.length) == 0)
// 初始化数组,后面会详细介绍
tab = initTable();
// 找该 hash 值对应的数组下标,得到第一个节点 f
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 如果数组该位置为空,用一次 CAS 操作将这个新值放入其中即可,
//这个 put 操作差不多就结束了,可以拉到最后面了
// 如果 CAS 失败,那就是有并发操作,进到下一个循环就好了
if (casTabAt(tab, i, null, new Node<K, V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// hash 等于 MOVED,表示正在扩容
else if ((fh = f.hash) == MOVED)
// 帮助数据迁移
tab = helpTransfer(tab, f);
else { // 到这里就是说,f 是该位置的头结点,而且不为空
V oldVal = null;
// 获取数组该位置的头结点的监视器锁
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { // 头结点的 hash 值大于 0,说明是链表
// 用于累加,记录链表的长度
binCount = 1;
// 遍历链表
for (Node<K, V> e = f; ; ++binCount) {
K ek;
// 如果发现了"相等"的 key,进行值覆盖,
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 到了链表的最末端,将这个新值放到链表的最后面
Node<K, V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K, V>(hash, key, value, null);
break;
}
}
} else if (f instanceof TreeBin) { // 红黑树
Node<K, V> p;
binCount = 2;
// 调用红黑树的插值方法插入新节点
if ((p = ((TreeBin<K, V>) f).putTreeVal(hash, key,value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// binCount != 0 说明上面在做链表操作
if (binCount != 0) {
// 判断是否要将链表转换为红黑树,临界值和 HashMap 一样,也是 8
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//节点数增加了 1 个
addCount(1L, binCount);
return null;
}
八、最后的总结和交流
8.1 三代 HashMap 代码行数的变化
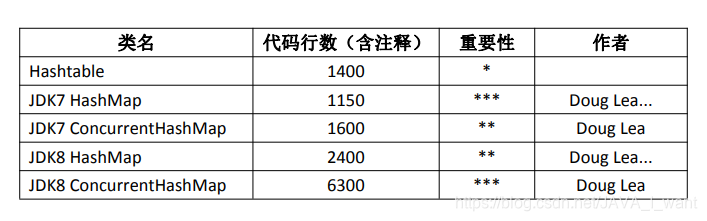
编程不识 Doug Lea,写尽 Java 也枉然。整个 JUC(java.util.concurrent)就是他的杰作。