在哈希表和 Java 的前世今生(上),掌握HashMap看这一篇就够了!!! 中,我们讲解了哈希表的原理以及JDK7 HashMap的源码及JDK7中HashMap的注意点。
在哈希表和 Java 的前世今生(中),掌握HashMap看这一篇就够了!!!中,我们讲解了JDK8 HashMap的源码,以及其与JDK7 HashMap的区别。
五、简单来看一下 Hashtable

HashMap 类大致相当于 Hashtable,只是它不同步并且允许空值。
5.1 问题 6:Hashtable 和 HashMap 的不同之处
-
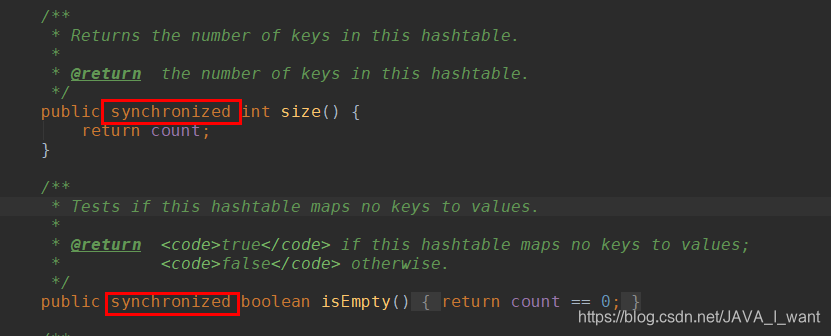
Hashtable 的方法是同步的
-
父类是 Dictionary
-
主数组长度不要求是 2 的幂
-
默认长度 11
-
Key 和 value 都不能是 null
-
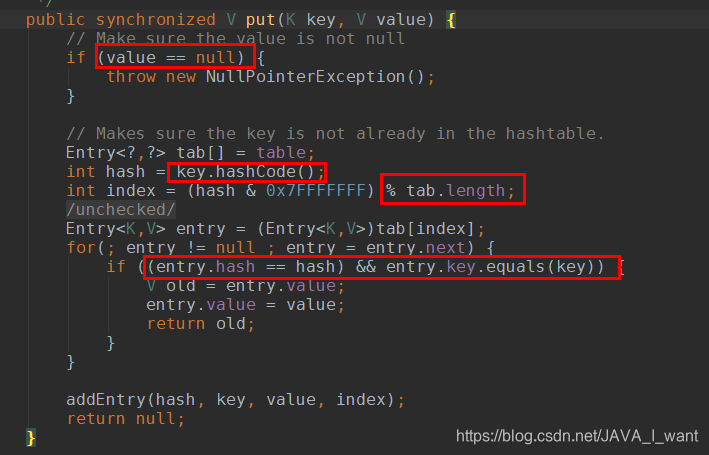
计算哈希值就是直接调用 hashCode()
-
计算存储位置就是使用%取模
-
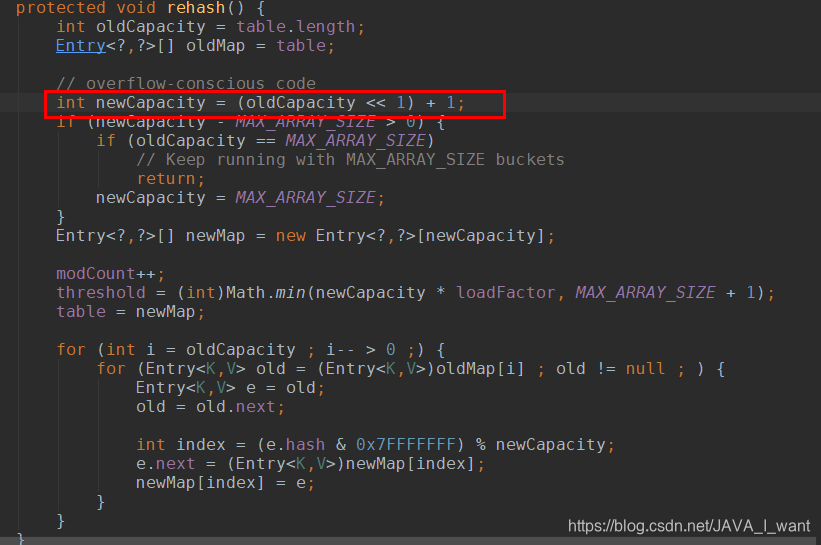
每次扩容为原来容量的 2 倍再+1
-
使用 Enumeration 进行迭代,而不是使用 Iterator(JDK1.2 才有)。
5.2 问题 7:为什么 Hashtable 主数组默认长度是 11,为何扩容 2 倍还要+1
按照哈希表的经典理论:哈希表主数组的长度应该是一个素数,这样会产生最分散的余数,尽可能减少哈希冲突。11 就是素数。扩容 2 倍肯定不是素数,+1 可能变成素数。
5.3 问题 8:Hashtable 的缺点
Hashtable 的方法使用的 synchronized 同步方法锁,非静态方法的锁是 this(当前的 Hashtable 对象,即整个哈希表)。一个线程上锁,就会锁住所有的访问同步方法的线程,并且是挡在了方法之外,效率太低。
HashMap 是非线程同步的,可以借助 Collections. synchronziedMap()保证线程安全,底层使用 synchronized 同步代码块,同步监视器也是当前的对象 this,也是锁住了整个哈希表,但是是将其他线程锁在了方法之内,同步代码之外,实际性能比 Hashtable 有提高,但是提高有限。
在大量高并发情况下如何提高集合的效率和安全呢?能否降低锁的粒度,锁住哈希表的一部分而不是全部呢?
可以的!!!
- JDK7 ConcurrentHashMap 锁住主数组的一部分(几个桶)
- JDK8 ConcurrentHashMap 锁住主数组的一部分(一个桶)
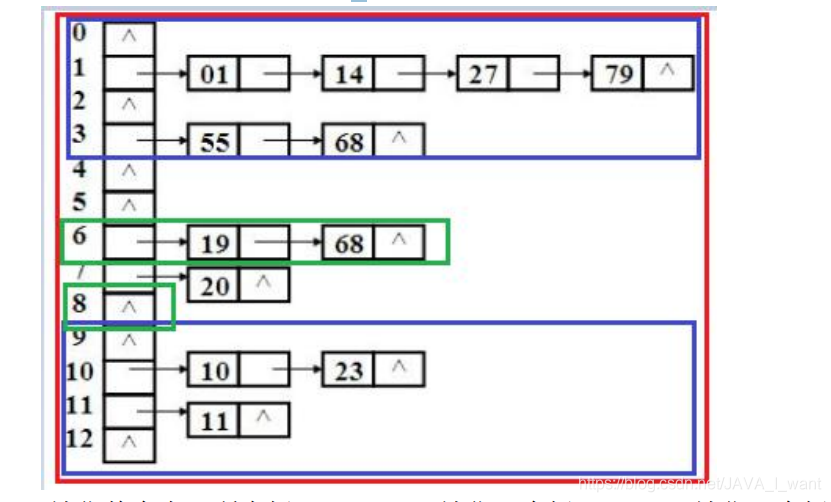
red:锁住整个表(所有桶); blue:锁住几个桶 green:锁住一个桶
六、JDK7 ConcurrentHashMap
6.1 问题 9:JDK7 ConcurrentHashMap 关键技能点
- 使用分段锁 Segment。由 Hashtable 的锁住整个表,HashMap 的不锁,到锁住表的一部分。线程同步使用的是 Lock 锁。
- 结构图:
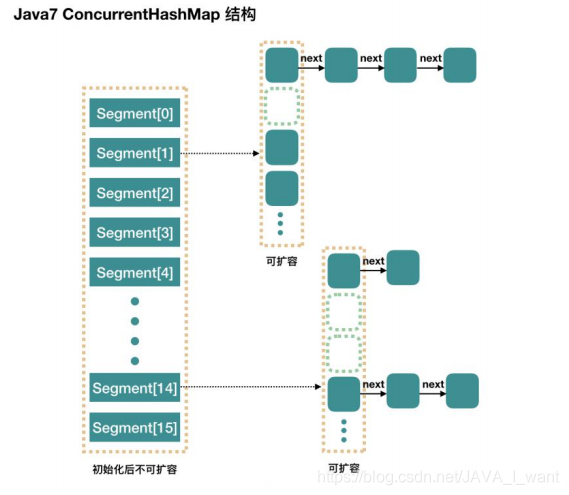
- ConcurrentHashMap 是由 Segment 数组和 HashEntry 数组结构组成。
- Segment 是一种可重入锁 ReentrantLock,在 ConcurrentHashMap 里扮演锁的角色,HashEntry 则用于存储键值对数据。
- 一个 ConcurrentHashMap 里包含一个 Segment 数组,Segment 的结构和 HashMap 类似,是一种数组和链表结构。一个 Segment 里包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素。每个Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得它对应的 Segment 锁。
6.2 问题 10:JDK7 ConcurrentHashMap 通过无参构造方法创建对象的结果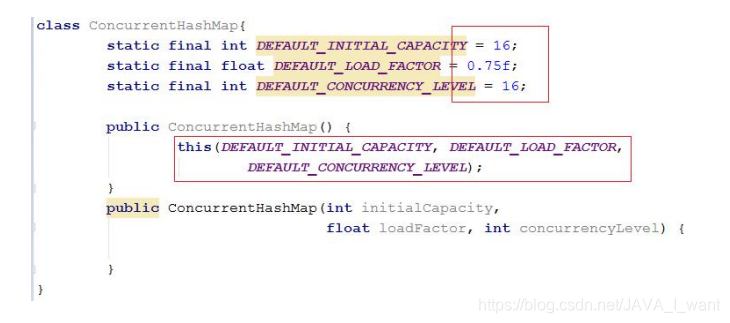
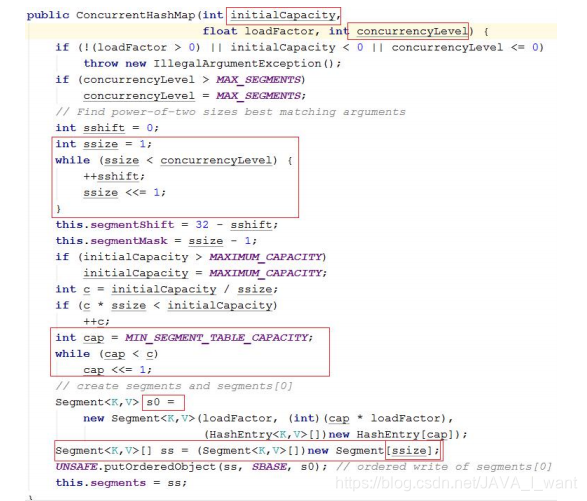
- initialCapacity:初始容量,这个值指的是整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 Segment
- loadFactor:加载因子。Segment 数组不扩容,所以是针对每个 Segment内部的加载因子。
- concurrencyLevel:并发级别,segment 数组容量,默认 16。要求是 2的幂。
- SEGMENT_TABLE_CAPACITY:每个 Segment 的内部数组的容量,最小是 2。可以扩容,必须是 2 的幂。每次扩容 100%。(int newCapacity =oldCapacity << 1;)
- 采用无参数构造方法创建对象后的内存结构如图所示(不包含蓝色部分)。Segment 数组长度 16,只给 segments[0]分配空间。发现每个 Segment其实就是一个HashMap,其中的数组 table 的容量是 2。

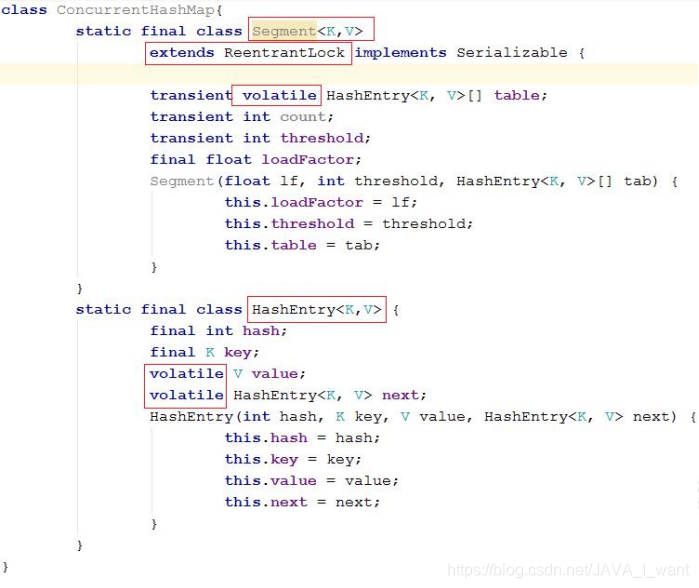
认识 Segment 和 HashEntry:
- Segment 其实就是之前的一个 HashMap,本身继承了 ReentrantLock,可以直接复用加锁、解锁等操作
- HashEntry 就是 HashMap 中的 Entry,是链表的节点类型,存储具体的键值对信息。
- 注意:Segment 的 table、HashEntry 的 value、next 都使用 volatile修饰,其修改在各个线程之间具有可见性。
6.3 JDK7 ConcurrentHashMap 源码阅读
- put 操作:
-
计算 key 所在的 Segments 数组的索引 j。如果 segments[j]==null,需要先分配空间。
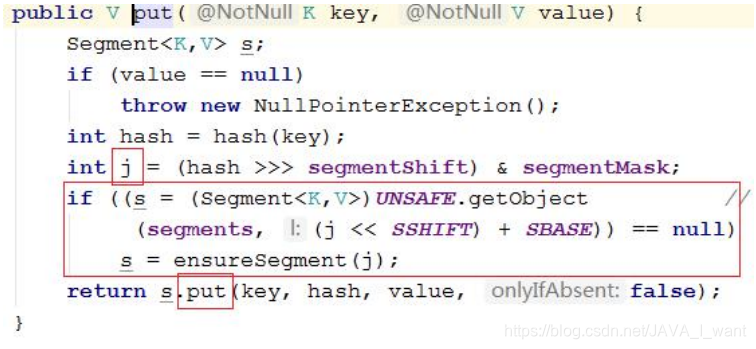
-
计算 key 所在的 HashEntry 数组的索引,并完成添加操作(使用 Lock 锁保证并发安全)
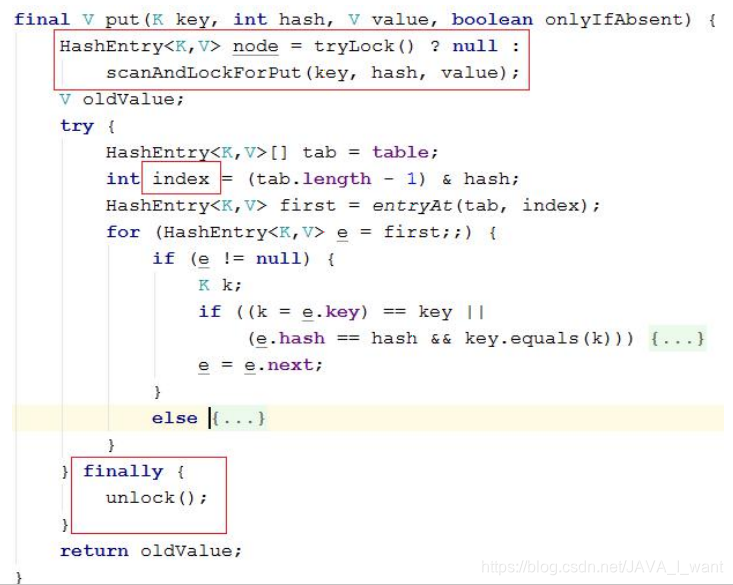
-
注 意 1 : 新 的 节 点 会 添 加 到 链 表 的 头 部 ( JDK7 的 HashMap 和ConcurrentHashMap 都是添加到头部)。
-
注意 2:添加了新节点再判断是否扩容(JDK7 的 HashMap 是先判断是否扩容,再添加)。
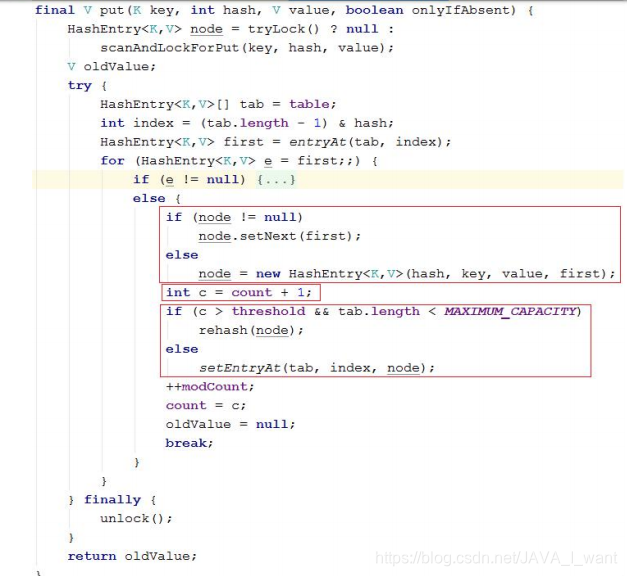
- get 操作:
- 计算 key 所在的 Segments 数组的索引 j。如果是 null,直接返回 null,不存在。
- 计算 key 所在的 HashEntry 数组的索引。找到了返回 HashEntry 的value,找不到,返回 null。
- 查询不加锁,但是支持并发查询。需要使用 UNSAFE 的方法

- size()操作:
- 有些方法需要跨段,比如 size()和 containsValue()。需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。
- 这里“按顺序”是很重要的,否则极有可能出现死锁
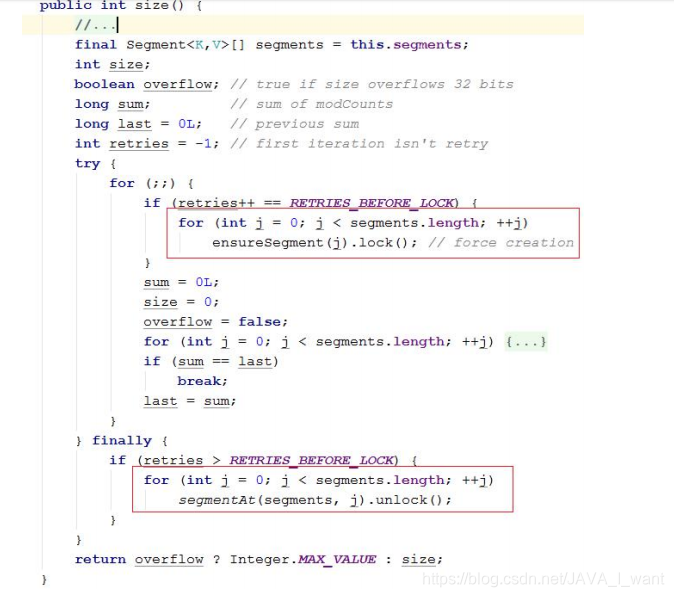
6.4 问题 11:Unsafe 类是怎么回事
- Unsafe 类是在 sun.misc 包下,不属于 Java 标准。但是很多 Java 的基础类库,包括一些被广泛使用的高性能开发库都是基于 Unsafe 类开发的,比如Netty、Hadoop、Kafka 等。
- 使用 Unsafe 可用来直接访问系统内存资源并进行自主管理,大部分 API 都是 native 的方法。Unsafe 类在提升 Java 运行效率,增强 Java 语言底层操作能力方面起了很大的作用。
- Unsafe 可认为是 Java 中留下的后门,提供了一些低层次操作,如直接内存访问、线程调度等。官方并不建议使用 Unsafe。
6.5 问题 12:JDK7 ConcurrentHashMap 的缺点是什么
- 结构复杂了:由一个 Segment 数组和多个 HashEntry 组成的两级结构组成
- 查询效率低了:需要先查询到 Segment 的索引,再查询到 HashEntry 的索引。统计 size()需要遍历整个 Segment 数组。
- 锁的粒度也不算小:concurrentLevel(并发数)基本上是固定的,其实还是锁住了一个哈希表,哪怕是一个小的 HashMap。能否只锁住 HashMap 的一个桶呢?concurrentLevel 就可以和数组大小保持一致了。
