朴素贝叶斯模型
二分类问题:训练集:知道内容,知道标签

主要就是统计一些单词出现的次数

垃圾邮件的分类:
现在我竹东统计一下:购买,单词的一些性质
给定了训练数据,有正常邮件和垃圾邮件:搜集数据
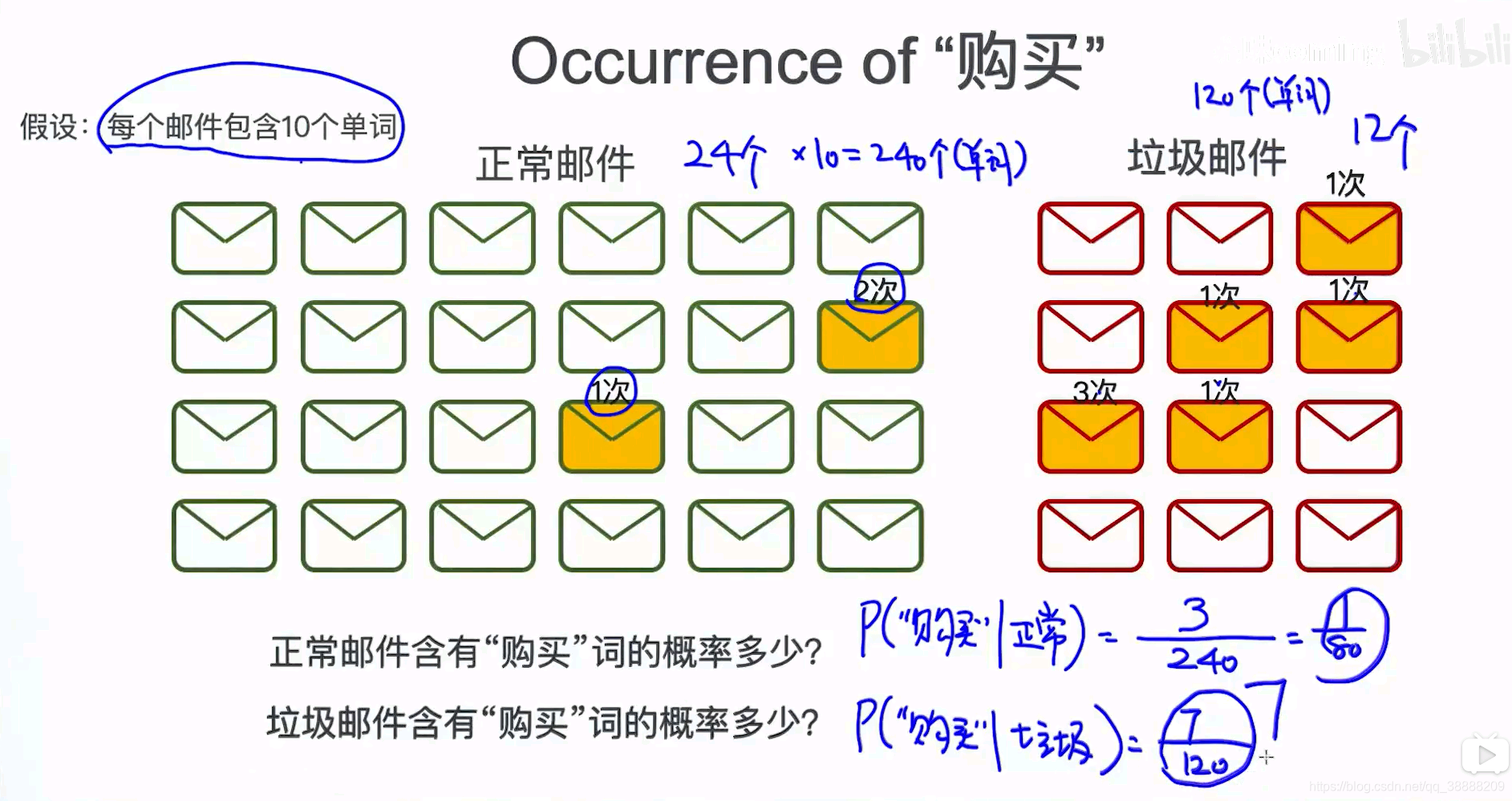
再来看一下:物品,这个单词



等等等
所以,我需要有一个 Vocab 词典库,然后对每一个单词都进行上面那个概率操作,找出敏感词。
可能会进行上万次操作。
在训练数据当中会得到先验知识

回顾:朴素贝叶斯 条件独立


P(正常)是先验概率
先对原始邮件用分词工具进行分词

案例分析:
- 训练模型
求先验概率、构建词库、求词库中每个单词在垃圾、正常中的概率(用上平滑项Add-one) - 预测
预测现在发送过来的邮件,给定的邮件是垃圾、正常的概率。
如果词库很大,上万个单词,最后连乘的时候会溢出,所以取个Log。所以一般小数连乘的时候,我都会用Log一下

