一、朴素贝叶斯基础知识
预备数学知识:
A. 无约束条件的优化
1、求极值问题
人工智能中最核心的数学环节是求出一个目标函数(object function)的最小值/最大值。求出一个函数最小是/最大值的方法很多,在这里我们介绍一个最经典的方法之一:直接求出极值点。这些极值点的共同特点是在这些点上的梯度为0, 如下图所示。这个图里面,有8个极值点,而且这些极值点中必然会存在最小值或者最大值(除去函数的左右最端点)。所以在这种方式下,我们通常x先求出函数的导数,然后设置成为0。之后从找出的极值点中选择使得结果为最小值/最大值的极值点。
例1:求
的最小值
对于这样的一个问题,其实我们都知道这个问题的答案是 x=1 ,基本上不需要计算就能看出来。接下来我们通过求导的方式来求一下最小值。首先对f(x)求导并把导数设置成0。
从而得到
, 求出来的是唯一的极值点,所以最后得出来的函数的最小值是
例2:
的最小值
求导之后
,即可以得到
.将这三个值代入f(x)得到
不一定所有函数的极值都可以通过设置导数为0的方式求出。也就是说,有些问题中当我们设定导数为0时,未必能直接计算出满足导数为0的点(比如逻辑回归模型),这时候就需要利用数值计算相关的技术(最典型为梯度下降法,牛顿法…)
B、带约束条件的优化-拉格朗日乘法项
例3:求
的最大值,但有个条件是
,这时候求最大值的方法是什么呢?
拉格朗日乘法项就是用来解决这类问题。我们可以把限制条件通过简单的转变加到目标函数中,这时候问题就变成了
maxmize
剩下的过程就跟上面的类似了。设定导数为0,即可以得到以下三个方程:

2. 最大似然估计(Maximum Likelihood Estimation)
假设有一枚硬币,它是不均匀的,也就是说出现正面的反面的概率是不同的。假设我们设定这枚硬币出现正面的概率为
, 这里 H指的是正面(head), 类似的还会有反面(tail)。假设我们投掷6次之后得到了以下的结果,而且我们假定每次投掷都是相互独立的事件:
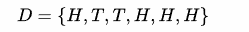
其中D表示所观测到的所有样本。从这个结果其实谁都可以很容易说出
,也就是出现正面的概率为4/6,其实我们在无意识中使用了最大似然估计法。接下来,我们从更严谨的角度来定义最大似然下的目标函数。
基于最大似然估计法,我们需要最大化观测到样本的概率,即p(D)。进一步可以写成:

(2)朴素贝叶斯的最大似然估计的词条分类



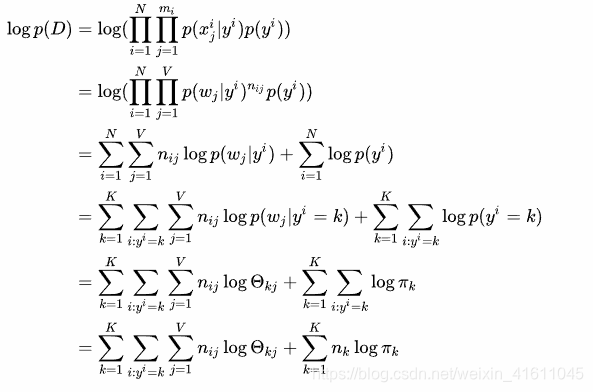



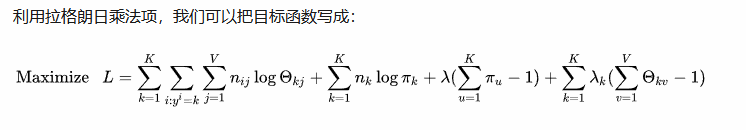




以上文章转自:https://zhuanlan.zhihu.com/p/71960086
朴素贝叶斯实战1:垃圾邮件的分类

我们将邮件分为两类,一类是正常邮件一类是垃圾邮件,一般垃圾邮件会包含一些关键词:如链接、点击等等。
我们有很多邮件的数据,并且已经知道哪些邮件是正常邮件还是垃圾邮件已经打上了数据标签,那么有邮件时便可以知道这个邮件是正常还是垃圾邮件。
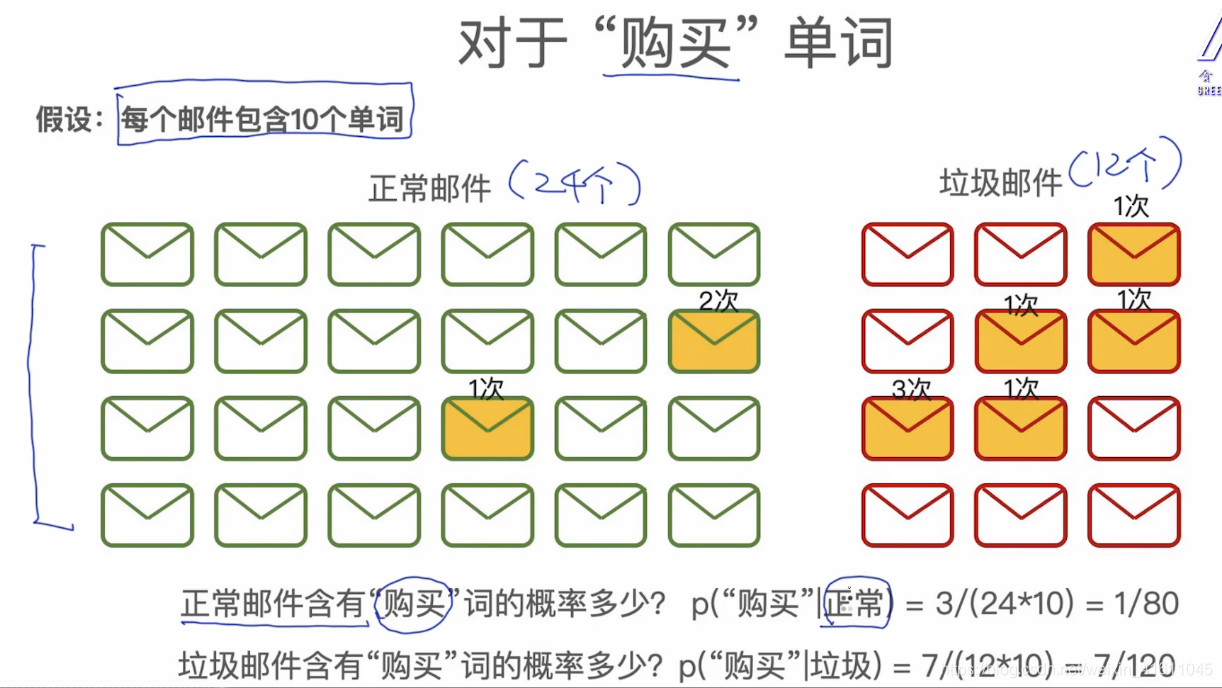
从上面的邮件中可以看出购买这个单词更容易出现在垃圾邮件的信息之中。
②对于物品这个单词
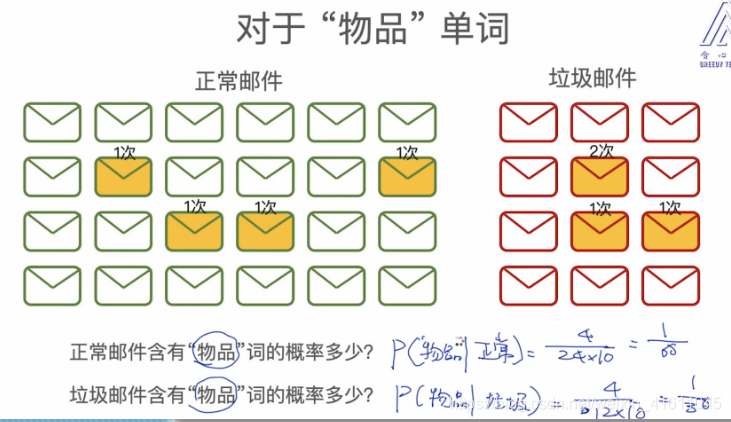
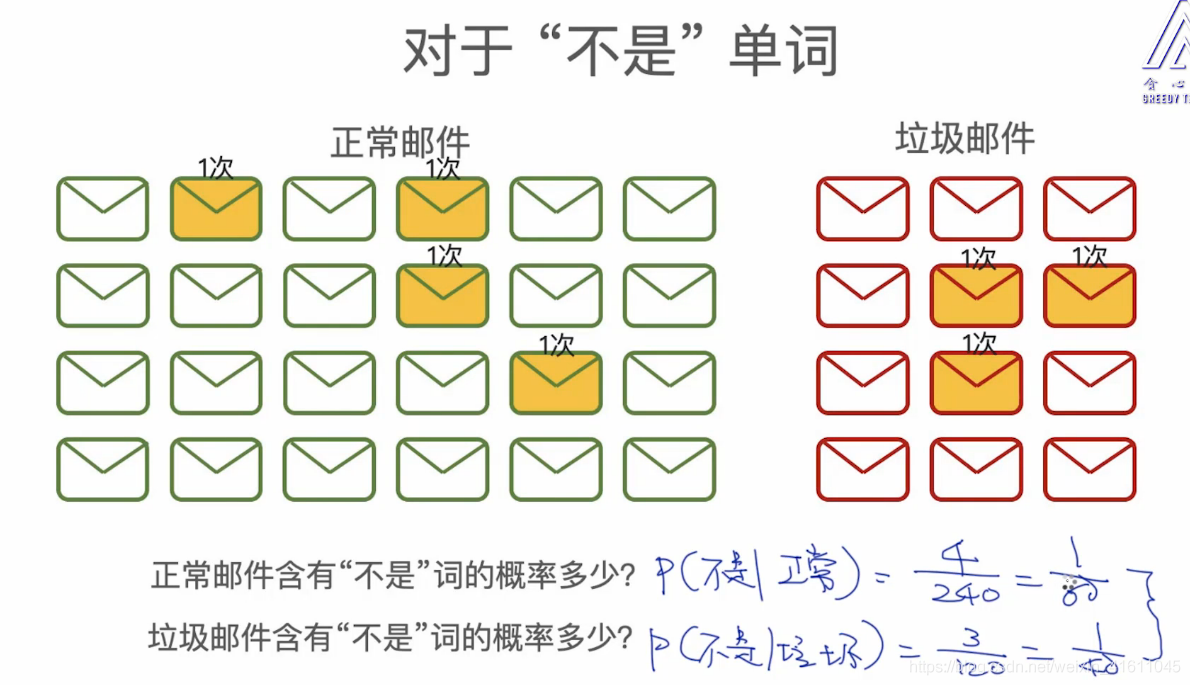
对于不是这个单词在垃圾邮件与正常邮件中出现的概率几乎相等。
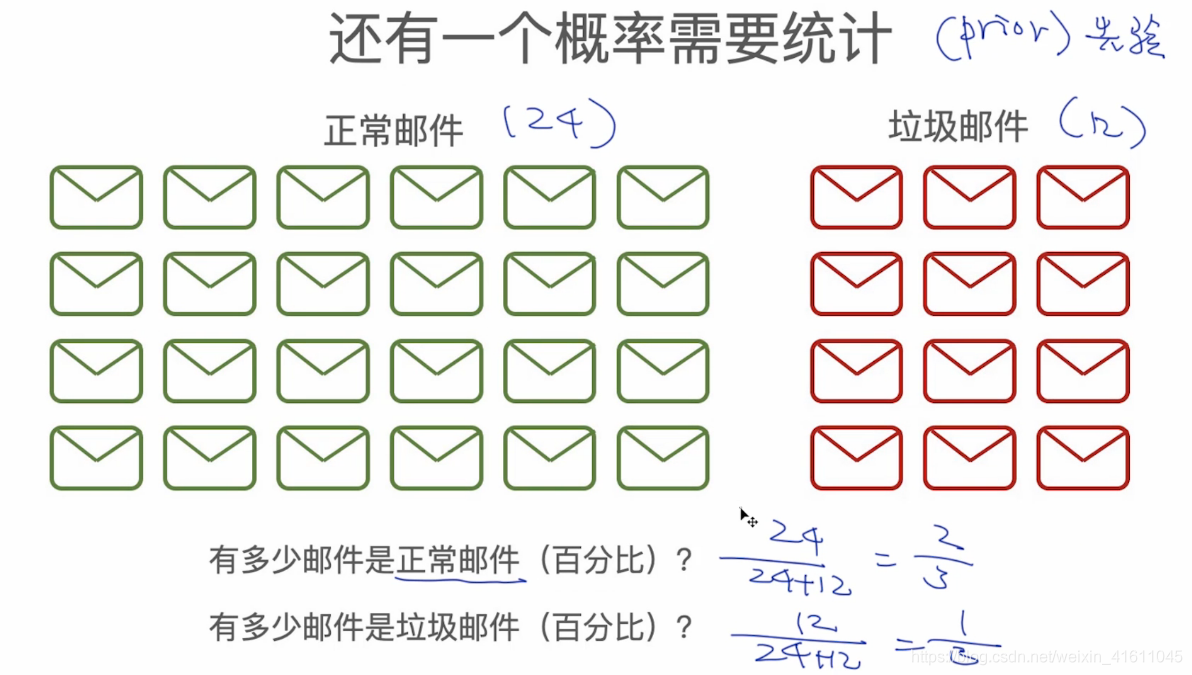
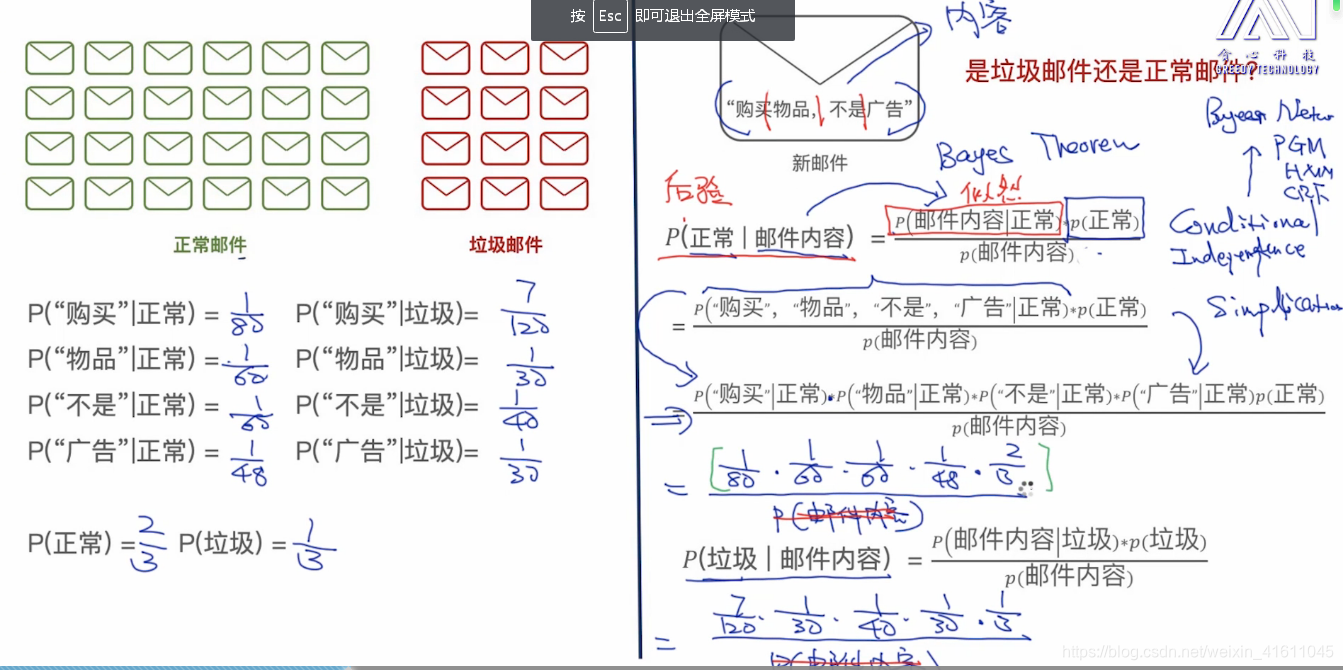
如图通过以往邮件中正常与垃圾邮件的概率计算出各个单词的词频,通过以上概率公式计算出该邮件是正常邮件的概率与该邮件是垃圾邮件的概率。
如果出现了某个词的概率等于0的情况怎么处理呢,这里采用平滑的方式进行处理

即如果分子的概率为0,则分子加1,分母为所有词语的样本总数加词频数。

案例代码:
import os
import pandas as pd
# 读取spam.csv文件
pd.set_option('display.max_rows',1000) # console 显示1000行
pd.set_option('display.max_columns',1000) # console显示1000列
os.chdir("F:\\68元AI课程学习\贝叶斯文本分类")
df = pd.read_csv("spam .csv", encoding='latin')
df.head()
v1 v2
0 ham Go until jurong point, crazy… Available only …
1 ham Ok lar… Joking wif u oni…
2 spam Free entry in 2 a wkly comp to win FA Cup fina…
3 ham U dun say so early hor… U c already then say…
4 ham Nah I don’t think he goes to usf, he lives aro…
数据的结构如上:基本分为两个部分,v1邮件的标签harm垃圾邮件,sparm正常邮件。
#重命名数据中的v1、v2列,使得拥有更好的可读性
df.rename(columns={"v1":"label","v2":"Text"},inplace=True)
df.head()
label Text
0 ham Go until jurong point, crazy… Available only …
1 ham Ok lar… Joking wif u oni…
2 spam Free entry in 2 a wkly comp to win FA Cup fina…
3 ham U dun say so early hor… U c already then say…
4 ham Nah I don’t think he goes to usf, he lives aro…
#重新定义harm,spam标签,如果分别将其设为0和1
df["numlabel"]=df["label"].map({'ham':0,"spam":1})
df.head()
label Text numlabel
0 ham Go until jurong point, crazy… Available only … 0
1 ham Ok lar… Joking wif u oni… 0
2 spam Free entry in 2 a wkly comp to win FA Cup fina… 1
3 ham U dun say so early hor… U c already then say… 0
4 ham Nah I don’t think he goes to usf, he lives aro… 0
#统计有多少个ham,有多少个spam
print("ham的数量:",len(df[df["label"]=="ham"]),"spam的数量",len(df[df["label"]=="ham"]))
print("总样本数",len(df))
ham的数量: 4825 spam的数量 4825
总样本数 5572
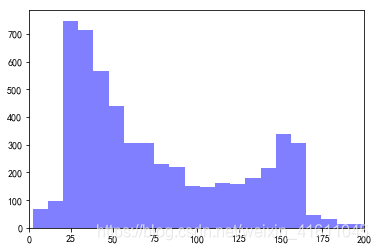
#计算每行的信息长度
text_lengths=[len(df.loc[i,"Text"]) for i in range(len(df))]
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.pyplot as plt
#利用直方图画出字段的长度,其中x轴代表字段长度出现的频率,y轴代表字段长度
plt.hist(text_lengths, 100, facecolor='blue', alpha=0.5)
plt.xlim([0,200])
plt.show()
#导入英文呢的停用词库
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import CountVectorizer
import nltk
nltk.download("stopwords")
# what is stop wordS? he she the an a that this ...设定停用词为英文
stopset=set(stopwords.words("english"))
# 构建文本的向量 (基于词频的表示)
vectorizer = CountVectorizer(stop_words=stopset,binary=True)
# sparse matrix
#将X训练成向量的形式
X = vectorizer.fit_transform(df.Text)
y = df.numlabel
print(X)
# 把数据分成训练数据和测试数据
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=100)
print ("训练数据中的样本个数: ", X_train.shape[0], "测试数据中的样本个数: ", X_test.shape[0])
建模与训练
# 利用朴素贝叶斯做训练
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
#其中alpha为公式中的平滑系数,fit_prior为是否计算先验概率
clf = MultinomialNB(alpha=1.0, fit_prior=True)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("accuracy on test data: ", accuracy_score(y_test, y_pred))
# 打印混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_pred, labels=[0, 1])
accuracy on test data: 0.9757847533632287
array([[952, 18],
[9, 136]], dtype=int64)