- 举例
①知乎高冷冷主页标题爬取
②https://www.zhihu.com/people/gao-leng-leng-61/posts - 打开Web Scraper,F12/网页右键—审查元素
- 创建Sitemap

- 进入lengleng

- Add new selector,设置selector抓取规则
①Select:爬取规则
②Element preview:页面查看爬取规则,是否选中
③Data preview:查看爬取的具体数据
④Multiple:抓取多个
⑤Delay:1000~5000值,一般2000ms即可。(新版没有)可以忽略参数

- 启动抓取程序Scrape

设置时间

start scraping,执行,弹出要爬去的页面,然后执行后,会自动关闭 - 查看页面,点击refresh
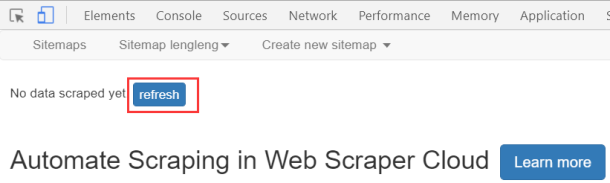
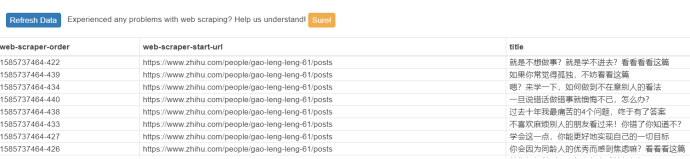
- 查看爬出的数据
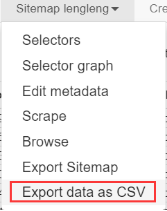
- 导出excel的csv文件到电脑
- 点击Download now!
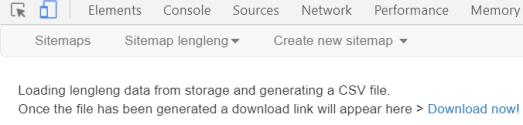
- 下载lengleng.csv,打开查看
①web-scraper-order:用于排序
②web-scraperstart-url:抓取的URL
③title:抓取的数据标题

- 问题
①不全
②无顺序
③没有翻页 - 注意
①抓取窗口,可以最小化,不可关闭
②可以同时执行启动多个Web Scraper爬虫程序 - 练习:抓取知乎评论
Web Scraper统计知乎大V文章标题_2.1

猜你喜欢
转载自blog.csdn.net/qq_42907800/article/details/105268379
今日推荐
周排行