- 规则:微博加载先不翻页,只有往下拉,加载到一定程度,才会翻页

翻页
规律
https://weibo.com/abaoshixiong?pids=Pl_Official_MyProfileFeed__22&is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page=1#feedtop
https://weibo.com/abaoshixiong?pids=Pl_Official_MyProfileFeed__22&is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page=2#feedtop
1-5页抓取
https://weibo.com/abaoshixiong?pids=Pl_Official_MyProfileFeed__22&is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page=[1-5]#feedtop - 创建sitemap

- 大模块
Element scroll down鼠标滑动

- 进入大模块,到小模块

创建2个子模块

- 执行抓取scrape,弹出窗口,会自动刷新页面1-8页进行抓取,刷新refresh,查看
- 导出cvs文件。缺点:乱序,不全,需要加大延迟时间!加载有可能不成功!
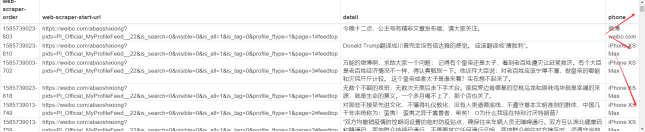
Web Scraper 抓取大V历史微博_2.7

猜你喜欢
转载自blog.csdn.net/qq_42907800/article/details/105268612
今日推荐
周排行