1. 正态分布
(1)概念
正态分布(英语:normal distribution)又名高斯分布(英语:Gaussian distribution),是一个非常常见的连续概率分布。则其概率密度函数为
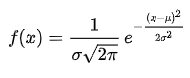
若随机变量X服从一个数学期望为μ、方差为σ^2的正态分布,记为N(μ,σ^2)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。
(2)应用
正态分布在统计学上十分重要,经常用在自然和社会科学来代表一个不明的随机变量,或生成各种不同的随机数
(3)代码与图像
自定义一个正态分布函数,画出一个均值是3,标准差是2的正态分布图
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 正态分布的概率密度函数。可以理解成 x 是 mu(均值)和 sigma(标准差)的函数
def normfun(x,mu,sigma):
pdf = np.exp(-((x - mu)**2)/(2*sigma**2)) / (sigma * np.sqrt(2*np.pi))
return pdf
x = np.linspace(-3,9,1000)
mu=3
sigma= 2
y = [normfun(i,mu,sigma) for i in x]
plt.scatter(x,y,1)
这么经典的函数其实我们没必要亲自写,下面将生成100000个服从标准正态分布的随机数,使用直方图画出来,并其对行拟合(披上红色的外衣)
# 随机生成10万个数
data = np.random.randn(100000)
#画出直方图,长度表示类别的频数,宽度表示表示类别
plt.hist(data,bins=50, density=1) # density表示是否将得到的直方图向量归一化,可选项,默认为0,代表不归一化,显示频数。normed=1,表示归一化,显示频率
x = np.linspace(-5,5,50)
# 拟合曲线
y = norm.pdf(x, 0, 1)
plt.plot(x, y,'r--') 
2. softmax 函数
(1)概念
在数学,尤其是概率论和相关领域中,Softmax函数,或称归一化指数函数,是逻辑函数的一种推广。它能将一个含任意实数的K维的向量Z的“压缩”到另一个K维实向量中,使得每一个元素的范围都在(0,1)之间,并且所有元素的和为1。

我们知道指数函数的值域取值范围是零到正无穷。与概率取值相似的地方是它们都是非负实数。那么我们可以1)利用指数函数将多分类结果映射到零到正无穷;2)然后进行归一化处理,便得到了近似的概率。softmax如何将多分类输出转换为概率,可以分为两步:
- 分子:通过指数函数,将实数输出映射到零到正无穷。
- 分母:将所有结果相加,进行归一化。
(2)应用
用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类
(3)代码与图像
import math
import matplotlib.pyplot as plt
def softmax(X):
X_exp = [math.exp(i) for i in X]
return [math.exp(i)/sum(X_exp) for i in X]
def fake_softmax(X):
# 如果只用分子除以总数,进行比较看看呢
return [i/sum(X) for i in X]
X = [1,2,5]
Y1 = softmax(X) # [0.01714782554552039, 0.04661262257797389, 0.9362395518765058]
Y2 = fake_softmax(X) # [0.125, 0.25, 0.625], 可以看到使用softmax对其进行了两极化,让高的更高,低的更低
print(f'sum = {sum(Y1)}')
plt.pie(Y1)
plt.show()

3. Sigmoid 函数
(1)概念
在二分类问题模型:例如逻辑回归「Logistic Regression」、神经网络「Neural Network」等,真实样本的标签为 [0,1],分别表示负类和正类。模型的最后通常会经过一个 Sigmoid 函数,输出一个概率值,这个概率值反映了预测为正类的可能性:概率越大,可能性越大。logistic函数也就是经常说的sigmoid函数,它的几何形状也就是一条sigmoid曲线(S型曲线)。A logistic function or logistic curve is a common “S” shape (sigmoid curve). 也就是说,sigmoid把一个值映射到0-1之间。公式如下:
![]()
该函数具有如下的特性:当x趋近于负无穷时,y趋近于0;当x趋近于正无穷时,y趋近于1;当x= 0时,y=0.5.
优点:
- 1.Sigmoid函数的输出映射在(0,1)之间,单调连续,输出范围有限,优化稳定,可以用作输出层。
- 2.求导容易,处处可导,导数为:f′(x)=f(x)(1−f(x)), 非常有用
缺点:
- 1.由于其软饱和性,容易产生梯度消失,导致训练出现问题。
- 2.其输出并不是以0为中心的。
(2)应用
logistic函数在统计学和机器学习领域应用最为广泛或者最为人熟知的肯定是逻辑回归模型了。逻辑回归(Logistic Regression,简称LR)作为一种对数线性模型(log-linear model)被广泛地应用于分类和回归场景中。此外,logistic函数也是神经网络最为常用的激活函数,即sigmoid函数。
机器学习中一个重要的预测模型逻辑回归(LR)就是基于Sigmoid函数实现的。LR模型的主要任务是给定一些历史的{X,Y}
其中X是样本n个特征值,Y的取值是{0,1}代表正例与负例
通过对这些历史样本的学习,从而得到一个数学模型,给定一个新的X,能够预测出Y。LR模型是一个二分类模型,即对于一个X,预测其发生或不发生。
但事实上,对于一个事件发生的情况,往往不能得到100%的预测,因此LR可以得到一个事件发生的可能性,超过50%则认为事件发生,低于50%则认为事件不发生
从LR的目的上来看,在选择函数时,有两个条件是必须要满足的:
- 取值范围在0~1之间。
- 对于一个事件发生情况,50%是其结果的分水岭,选择函数应该在0.5中心对称。
从这两个条件来看,Sigmoid很好的符合了LR的需求。
(3)代码与图像
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1.0/(1+np.exp(-x))
X = np.arange(-10,11)
Y = [sigmoid(i) for i in X]
plt.plot(X,Y,1)
Softmax 与 Sigmoid的区别
softmax与Sigmoid函数都是将实际值映射到[0,1]的区间,用来做分类。区别如下:
- softmax可用于多分类,比如给出一个颜色[0.7, 0.2, 0.1],它可以在红、绿、蓝三类中得出它是红色,它必须算出每个类别的概率。
- Sigmoid 用于二分类,非黑即白的那种,如果给出一个颜色,它是白色概率为0.6,它那就是白色, 不管算出黑色的概率为多少。
| Softmax | Sigmoid | |
| 公式 | |
|
| 本质 | 离散概率分布 | 非线性映射 |
| 任务 | 多分类 | 二分类 |
| 定义域 | 某个一维向量 | 单个数值 |
| 值域 | [0,1] | (0,1) |
| 结果之和 | 一定为1 | 为某个正数 |
4. 交叉熵损失函数「Cross Entropy Loss」
(1)概念
在模型训练中,我们需要衡量价格预测值与真实值之间的误差。通常我们会选取一个非负数作为误差,且数值越小表示误差越小。公式如下:
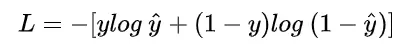
假设当真实标签的值为y=1时,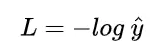
这时候,L 与预测输出的关系如下图所示:

也就是说,预测的输出越是接近1,那么损失函数L的值越小。
当 y=0时,![]()
L 与预测输出的关系如下图所示:

同样,预测输出越接近真实样本标签 0,损失函数 L 越小;预测函数越接近 1,L 越大。函数的变化趋势也完全符合实际需要的情况。
从图形中我们可以发现:预测输出与 y 差得越多,L 的值越大,也就是说对当前模型的 “ 惩罚 ” 越大,而且是非线性增大,是一种类似指数增长的级别。这是由 log 函数本身的特性所决定的。这样的好处是模型会倾向于让预测输出更接近真实样本标签 y。
(2)应用
主要用于在机器学习或深度学中,判断预测输出的值与真实的标签的误差,损失函数 L 越小越好。
