模型评估
在上一章节的末尾我们提到过模型的评估,那时只是简单的求了一下百分比,那种方式只能粗略的反映模型的准确率,针对二元分类算法,我们有AUC(Area under the Curve of ROC)即ROC曲线下的面积来评估模型的好坏在计算AUC之前应该先理解下面的几个概念:
| / | 真 | 假 |
|---|---|---|
| 阳 | TP | FP |
| 阴 | TN | FN |
- 真阳性 True Positives ( TP ): 预测为 1 ,实际为 1.
- 假阳性 False Positives ( FP ): 预测为 1 ,实际为 0.
- 真阴性 True Negatives ( TN ): 预测为 0 ,实际为 0.
- 假阴性 True Negatives ( FN ): 预测为 0 ,实际为 1.
- TPR:在所有实际为 1 的样本中被正确判断为 1 的比例.
TPR = TP/( TP + FN ) - FPR: 在所有实际为 0 的样本中被错误判断为 1 的比例.
FPR = FP/( FP + TN)
有了 TPR 和 FPR就可以绘制ROC曲线了,如下图所示:
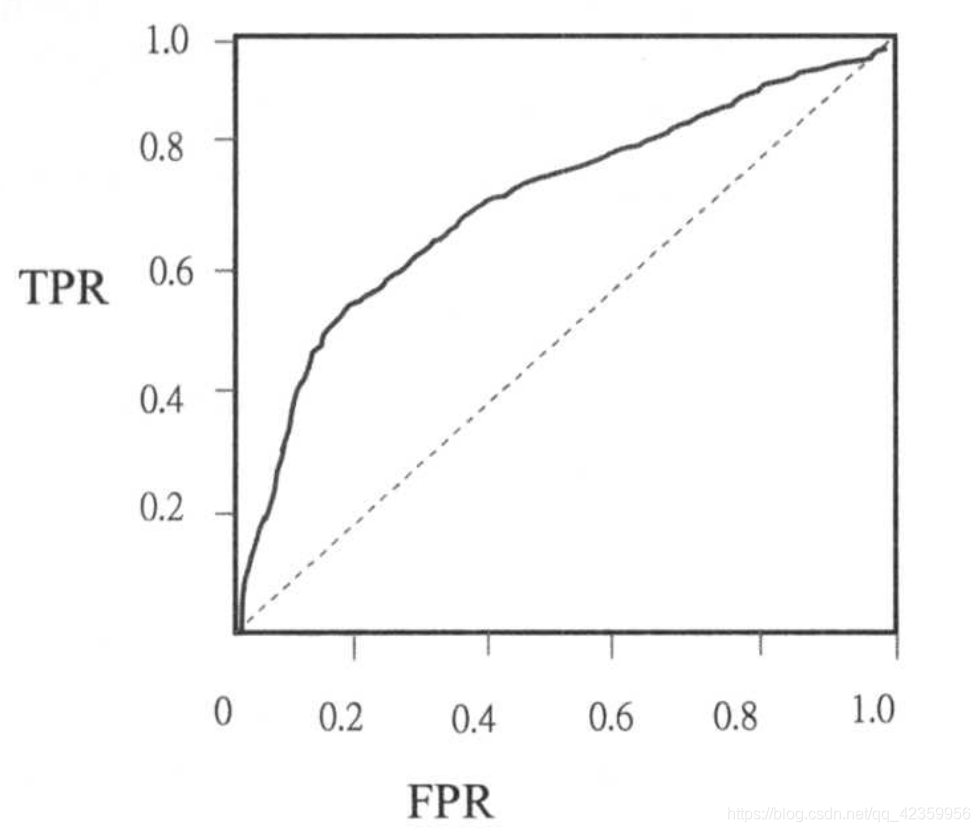
ROC曲线与XY轴正方向围成的面积即为AUC的值
1、训练模型
model = DecisionTree.trainClassifier(train_data,numClasses=2,categoricalFeaturesInfo={},impurity="entropy",maxDepth=5,maxBins=5)
2、将预测结果和真实值压缩在一起
score = model.predict(validation_data.map(lambda p:p.features))
score_and_labels = score.zip(validation_data.map(lambda p:p.label))
score_and_labels.take(5)
[(0.0, 1.0), (0.0, 0.0), (1.0, 0.0), (1.0, 0.0), (0.0, 1.0)]
3、导入评估二元分类器模型的包
from pyspark.mllib.evaluation import BinaryClassificationMetrics
# 计算模型的AUC值(ROC曲线囊括的面积)
metrics = BinaryClassificationMetrics(score_and_labels)
metrics.areaUnderROC
0.6199946682707425
4、集成二元分类的AUC值计算
def evaluationBinaryClassification(model,validation_data):
# 将验证数据的features传入通过模型进行评估,然后得到预测结果
score = model.predict(validation_data.map(lambda p:p.features))
# 构造为 (预测值,真实值) 的集合
score_and_labels = score.zip(validation_data.map(lambda p:p.label))
# 计算出评估矩阵
metrics = BinaryClassificationMetrics(score_and_labels)
# 返回矩阵的ROC曲线面积也就是AUC的值
return metrics.areaUnderROC
evaluationBinaryClassification(model,validation_data)
0.6769676269676269
5、影响模型准确率的因素
因为训练模型时我们可以改变的参数有三个,impurity(分支方式),maxDepth(树的最大深度),maxBins(每个节点的最大分支数),如果简单的将三个变量进行排列组合加枚举的方式列进行训练模型而找最大值的话,肯定准确是准确,但是太耗费资源了,所以这里采用控制变量的方法(进行单一变量原则)进行测试,分别探寻每个参数的最优解;
5.1 impurity 参数影响
5.1.2 定义训练评估模型
import time
# 训练并评估模型
def evaluationTrainModel(train_data,validation_data,impurity,maxDepth,maxBins):
# 记录开始时间
start_time = time.time()
# 根据传入参数训练模型
model = DecisionTree.trainClassifier(train_data,numClasses=2,categoricalFeaturesInfo={},impurity=impurity,maxDepth=maxDepth,maxBins=maxBins)
# 记录模型的训练时间
duration = time.time() - start_time
# 根据训练出的模型使用验证数据算出AUC值
AUC = evaluationBinaryClassification(model,validation_data)
return (model,duration,AUC,impurity,maxDepth,maxBins)
evaluationTrainModel(train_data,validation_data,"entropy",10,10)
(DecisionTreeModel classifier of depth 10 with 591 nodes,
0.641793966293335,
0.6459731773005045,
'entropy',
10,
10)
5.1.3创建模型评估矩阵
maxBinsList = [10]
maxDepthList = [10]
impurityList = ["gini","entropy"]
# 排列组合参数进行构造评估矩阵
metrics = [
evaluationTrainModel(train_data,validation_data,impurity,maxDepth,maxBins)
for maxBins in maxBinsList
for maxDepth in maxDepthList
for impurity in impurityList]
metrics
[(DecisionTreeModel classifier of depth 10 with 699 nodes,
0.7073895931243896,
0.6269453519453518,
'gini',
10,
10),
(DecisionTreeModel classifier of depth 10 with 673 nodes,
0.7021915912628174,
0.63500891000891,
'entropy',
10,
10)]
5.1.4 将矩阵转换为DataFrame
import pandas as pd
# 转换为pandans的DataFrame
df = pd.DataFrame(data=metrics,index=impurityList,columns=["Model","Duration","AUC","Impurity","maxDepth","maxBins"])
df
| Model | Duration | AUC | Impurity | maxDepth | maxBins | |
|---|---|---|---|---|---|---|
| gini | DecisionTreeModel classifier of depth 10 with ... | 0.707390 | 0.626945 | gini | 10 | 10 |
| entropy | DecisionTreeModel classifier of depth 10 with ... | 0.702192 | 0.635009 | entropy | 10 | 10 |
5.1.5 绘制图像
关于绘制图像和pyplot的一些常用方法可以参照博主的另一篇文章:
Pyplot 常见绘图方法
from matplotlib import pyplot as plt
# 绘制时间曲线
plt.plot(df["Duration"],ls="-",lw=2,c="r",label="Duration",marker="o")
# 绘制模型AUC分数柱
plt.bar(df["Impurity"],df["AUC"],ls="-",lw=2,color="c",label="AUC")
# 显示图例
plt.legend()
# 设置x轴方向的范围
plt.xlim(-1,2)
# 设置 y轴方向范围
plt.ylim(0.6,0.75)
# 绘制网格
plt.grid(ls=":",lw=1,c="gray")
# impurity = 'entropy'
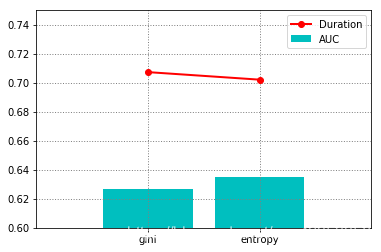
通过图像我们可以很明显的看出entropy (熵) 用来作为分支的依据,无论是从模型训练时间上,和模型的准确率都比 “gini” 要好一些,所以分支方法就可以选定为"entropy"了
5.2 maxDepth参数影响
maxBinsList = [10]
maxDepthList = [i for i in range(1,21)]
impurityList = ["entropy"]
metrics = [
evaluationTrainModel(train_data,validation_data,impurity,maxDepth,maxBins)
for maxBins in maxBinsList
for maxDepth in maxDepthList
for impurity in impurityList]
df = pd.DataFrame(data=metrics,index=maxDepthList,columns=["Model","Duration","AUC","Impurity","maxDepth","maxBins"])
# 绘制时间曲线
plt.plot(df["Duration"],ls="-",lw=2,c="r",label="Duration")
# 绘制模型AUC分数柱
plt.bar(df["maxDepth"],df["AUC"],ls="-",lw=2,color="c",label="AUC",tick_label=df["maxDepth"])
# 显示图例
plt.legend()
# 设置x轴方向的范围
plt.xlim(0,21)
# 设置 y轴方向范围
plt.ylim(0.4,0.7)
# 绘制网格
plt.grid(ls=":",lw=1,c="gray")
# maxDepth = 8
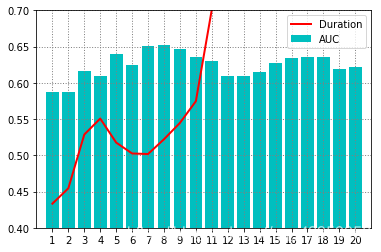
从图中可以看到模型训练时间随树的深度增加而增加,但是我们发现深度在4~10时,模型训练时间有一段低谷时期,而且碰巧的是AUC的值也在这一个区间内达到了最大,所以我们就选择8作为maxDepth的最优解
5.3 maxBins参数影响
maxBinsList = [i for i in range(2,21)]
maxDepthList = [8]
impurityList = ["entropy"]
metrics = [
evaluationTrainModel(train_data,validation_data,impurity,maxDepth,maxBins)
for maxBins in maxBinsList
for maxDepth in maxDepthList
for impurity in impurityList]
df = pd.DataFrame(data=metrics,index=maxBinsList,columns=["Model","Duration","AUC","Impurity","maxDepth","maxBins"])
# 绘制时间曲线
plt.plot(df["Duration"],ls="-",lw=2,c="r",label="Duration")
# 绘制模型AUC分数柱
plt.bar(df["maxBins"],df["AUC"],ls="-",lw=2,color="c",label="AUC",tick_label=df["maxBins"])
# 显示图例
plt.legend()
# 设置x轴方向的范围
plt.xlim(0,21)
# 设置 y轴方向范围
plt.ylim(0.6,0.7)
# 绘制网格
plt.grid(ls=":",lw=1,c="gray")
# maxBins = 7
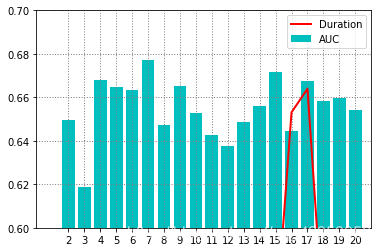
从图中可以看到,基本上模型的训练时间和每个节点的最大分支数没太大的关系,单个模型的训练时间基本都在 0.6s 以下,所以我们仅需找AUC值最大的点即可,那就是maxBins = 7 时
6、模型最终结果
6.1 导入测试文件的数据
def loadTestData(sc):
raw_data_and_header = sc.textFile("file:/home/zh123/.jupyter/workspace/stumbleupon/test.tsv")
# 文件头部
header_data = raw_data_and_header.first()
# 取头
raw_non_header_data = raw_data_and_header.filter(lambda l:l != header_data)
# 去引号
raw_non_quot_data = raw_non_header_data.map(lambda s:s.replace("\"",""))
# 最终测试文件数据
data = raw_non_quot_data.map(lambda l:l.split("\t"))
# 初始化类型映射字典
categories_dict = data.map(lambda fields:fields[3]).distinct().zipWithIndex().collectAsMap()
# 这里是因为我前面训练过程中没有保存那时的类型映射字典,所以这里就补了两位不然会报错
categories_dict.update({"t1":-1,"t2":-1})
label_point_rdd = data.map(lambda fields:(
fields[0],
extract_features(fields,categories_dict,len(fields))
))
return label_point_rdd
test_file_data = loadTestData(sc)
print(test_file_data.take(1))
print(test_file_data.count())
[('http://www.lynnskitchenadventures.com/2009/04/homemade-enchilada-sauce.html', array([0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 4.43906000e-01, 2.55813954e+00,
3.89705882e-01, 2.57352941e-01, 4.41176470e-02, 2.20588240e-02,
4.89572471e-01, 0.00000000e+00, 0.00000000e+00, 6.71428570e-02,
0.00000000e+00, 2.30285215e-01, 1.99438202e-01, 1.00000000e+00,
1.00000000e+00, 1.50000000e+01, 0.00000000e+00, 5.64300000e+03,
1.36000000e+02, 3.00000000e+00, 2.42647059e-01, 8.05970150e-02]))]
3171
6.2 加载模型
# 使用最终确认的的参数进行训练模型
model = evaluationTrainModel(train_data,validation_data,impurity="entropy",maxDepth=8,maxBins=7)[0]
6.3 随机选择10组数据进行预测
# 从测试文件集中随机抽取10个数据
for f in test_file_data.randomSplit([10,3171-10])[0].collect():
# 打印网站名称和预测结果
print(f[0],bool(model.predict(f[1])))
http://culinarycory.com/2008/12/30/pear-apple-crumb-pie/ True
http://mobile.seriouseats.com/2011/03/ramen-hacks-30-easy-ways-to-upgrade-your-instant-noodles-japanese-what-to-do-with-ramen.html False
http://blogs.babble.com/family-kitchen/2011/10/03/halloween-hauntingly-beautiful-candied-apples/ True
http://www.ivillage.com/paprika-potato-frittata-0/3-r-60973 True
http://www.goodlifeeats.com/2011/06/chocolate-covered-brownie-ice-cream-sandwich-recipe.html False
http://redux.com/stream/item/2071196/Two-Women-Fight-for-a-Parking-Spot-Then-Brilliance-Happens False
http://news.boloji.com/2008/10/25084.htm False
http://azoovo.com/a-corporate-web-design/ True
http://funstuffcafe.com/need-to-want-less False
http://www.insidershealth.com/article/nestle_cookie_dough_recall/3601 False
http://bakingbites.com/category/recipes/bar-cookies/ True
上面即是我们预测的结果,格式为(url, 是否为长期推荐网页),我们可以人为的点击网页链接进行查看网页是否和后面预测的结果一样属于 非/可以 长期推荐的网页;
最后网页分类的项目到此就完结了 撒花!
博客中有问题的地方欢迎大佬指出,当然还有疑问的小伙伴也可以私聊或者评论区留言哟!
最重要还是 点赞!评论!收藏!三连哦,谢谢.
