使用XPath爬取豆瓣电影的信息
1.下载lxml库
lxml是一个非常重要的库,后面的Beautiful Soup、Scrapy框架都需要用到此库,XPath是一个解析语言,只有安装解析库才可以对网页数据进行解析
方法一:在cmd中输入 pip install lxml
方法二:在pycharm的setting中添加 lxml
2.导入需要的库
# 导入需要的库
import requests
from lxml import etree
import re
3.网页操作
①公式五步走:地址+头+request.get获得的的text+etree.HTML(html)+selector.xpath(“xxx”)
即 url +
headers +
html=requests.get(url,headers=headers).text+
selector=etree.HTML(html)+
lis=selector.xpath(“xxx”)
②XPath的用法详情见这里
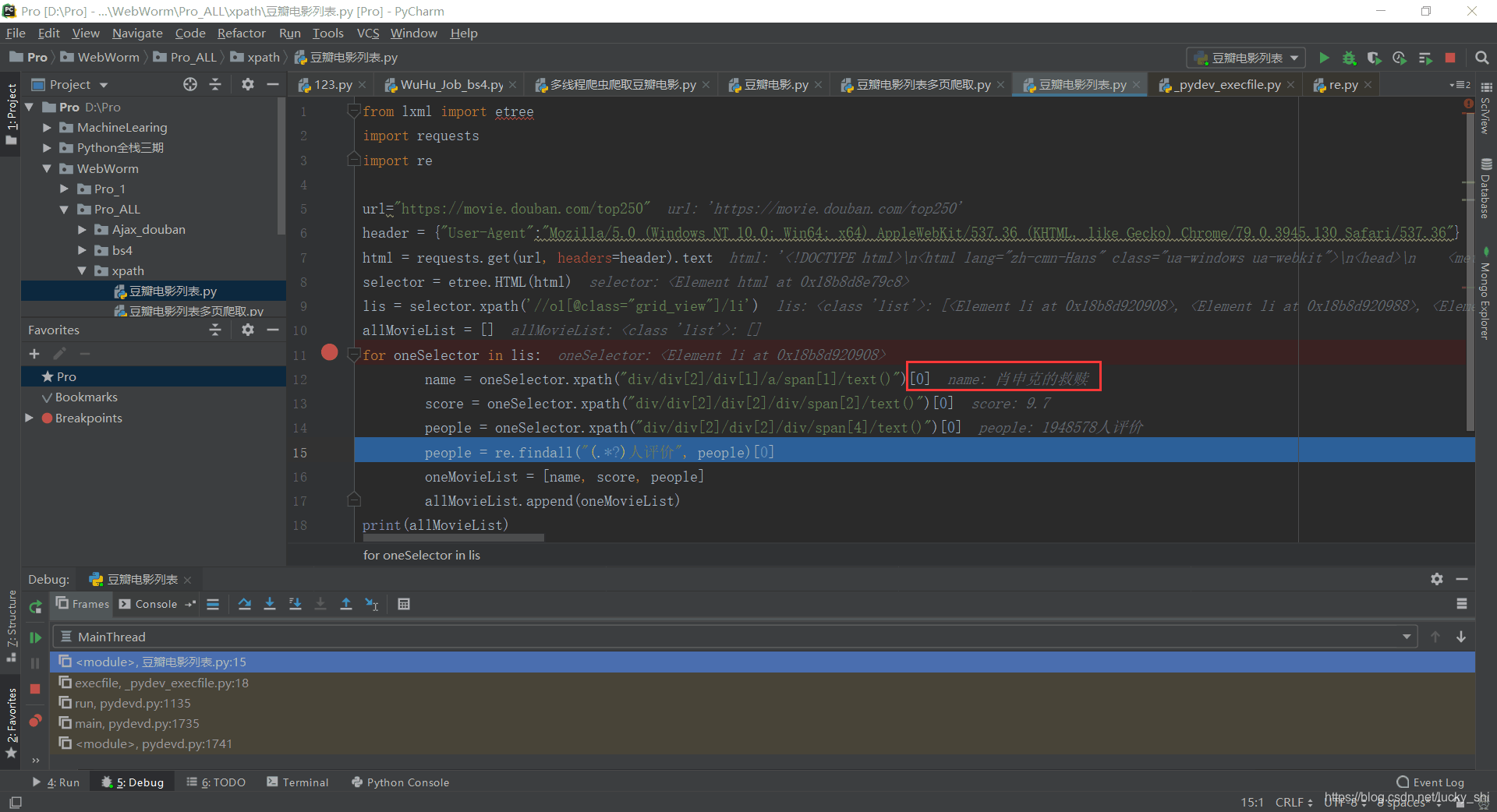
完整代码为:
from lxml import etree
import requests
import re
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector = etree.HTML(html)
lis = selector.xpath('//ol[@class="grid_view"]/li')
allMovieList = []
for oneSelector in lis:
name = oneSelector.xpath("div/div[2]/div[1]/a/span[1]/text()")[0]
score = oneSelector.xpath("div/div[2]/div[2]/div/span[2]/text()")[0]
people = oneSelector.xpath("div/div[2]/div[2]/div/span[4]/text()")[0]
people = re.findall("(.*?)人评价", people)[0]
# people = re.sub('\D','',people)
oneMovieList = [name, score, people]
allMovieList.append(oneMovieList)
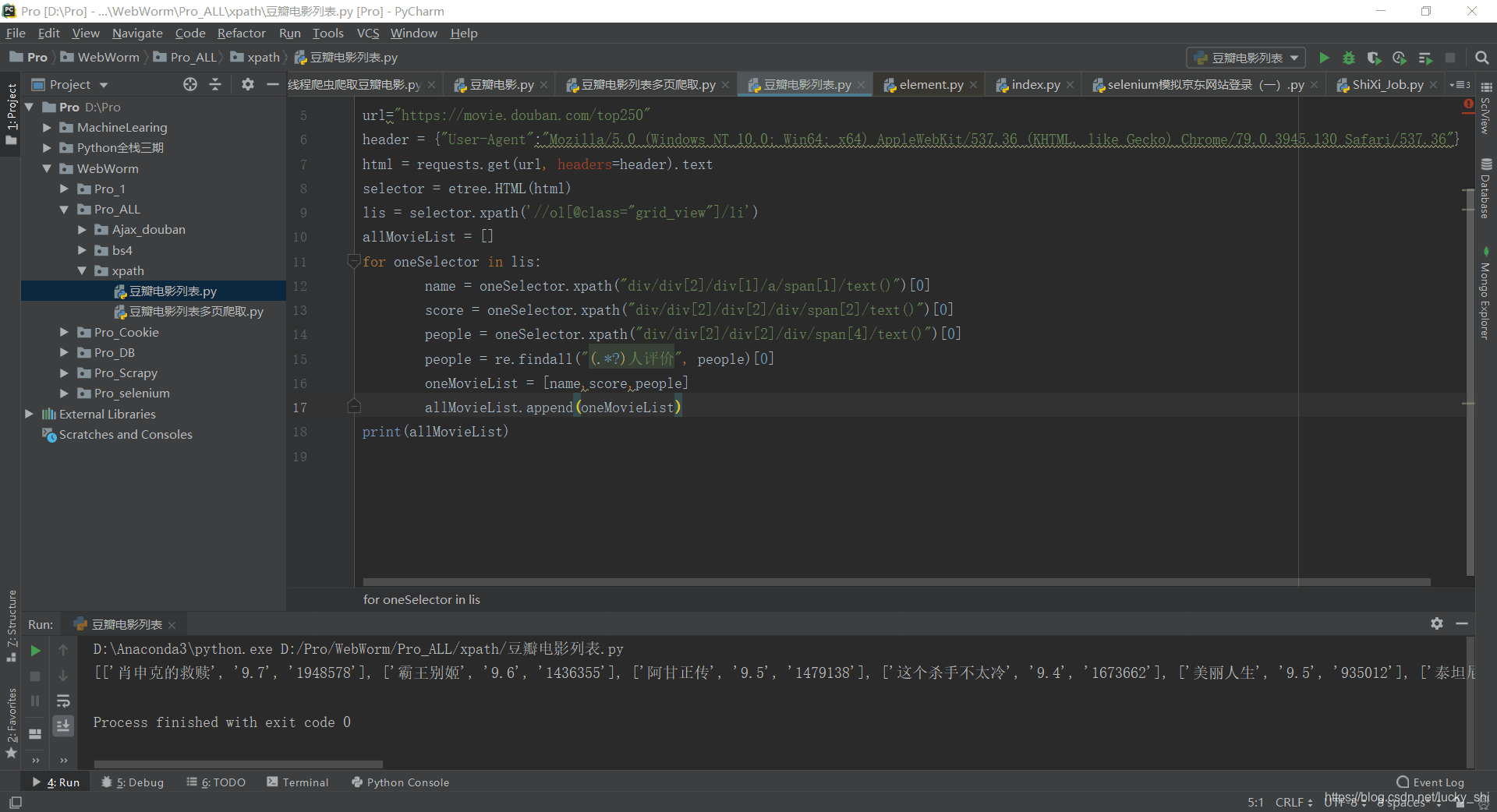
print(allMovieList)
运行结果为
4.上述代码中细节分析
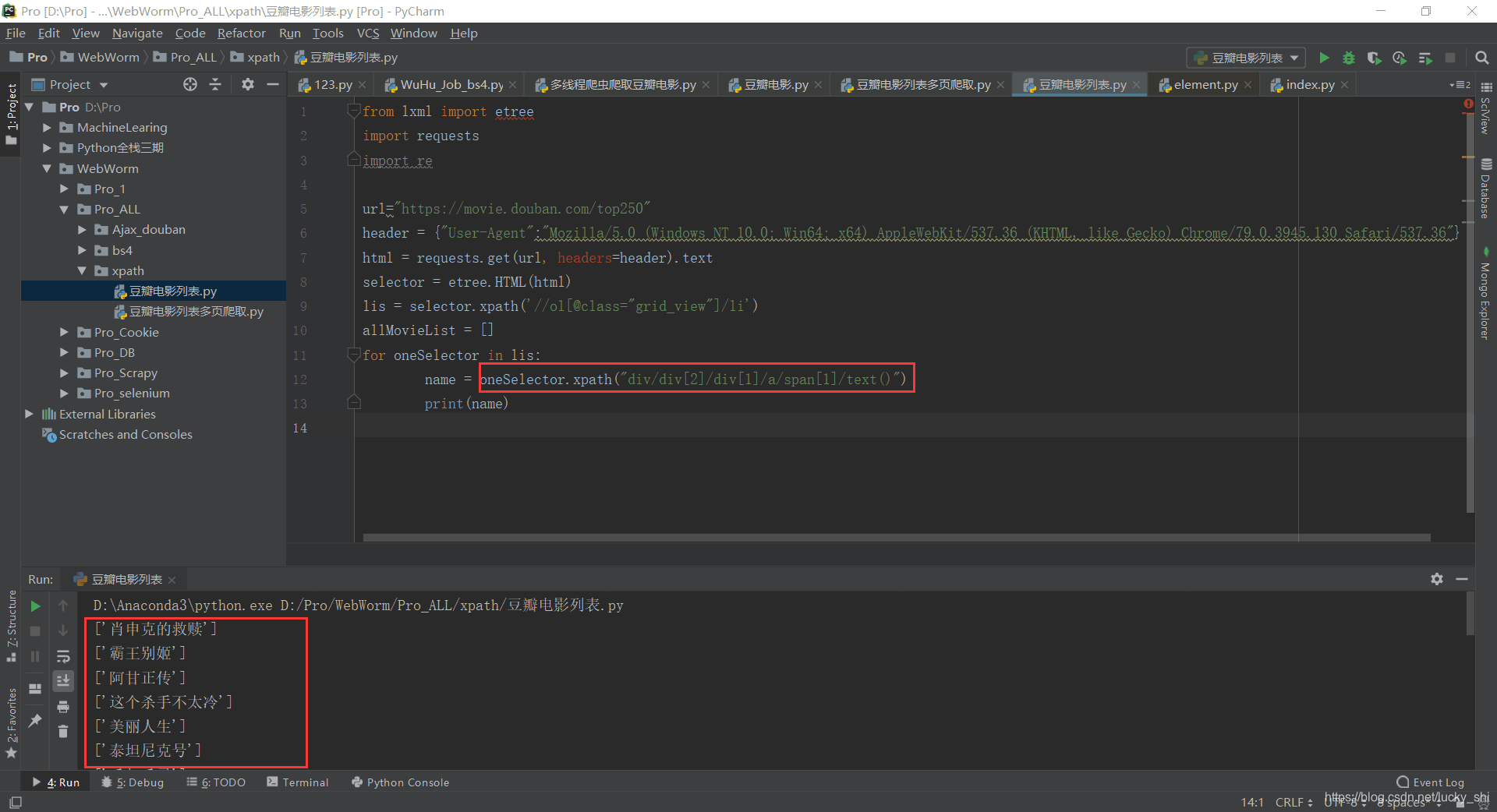
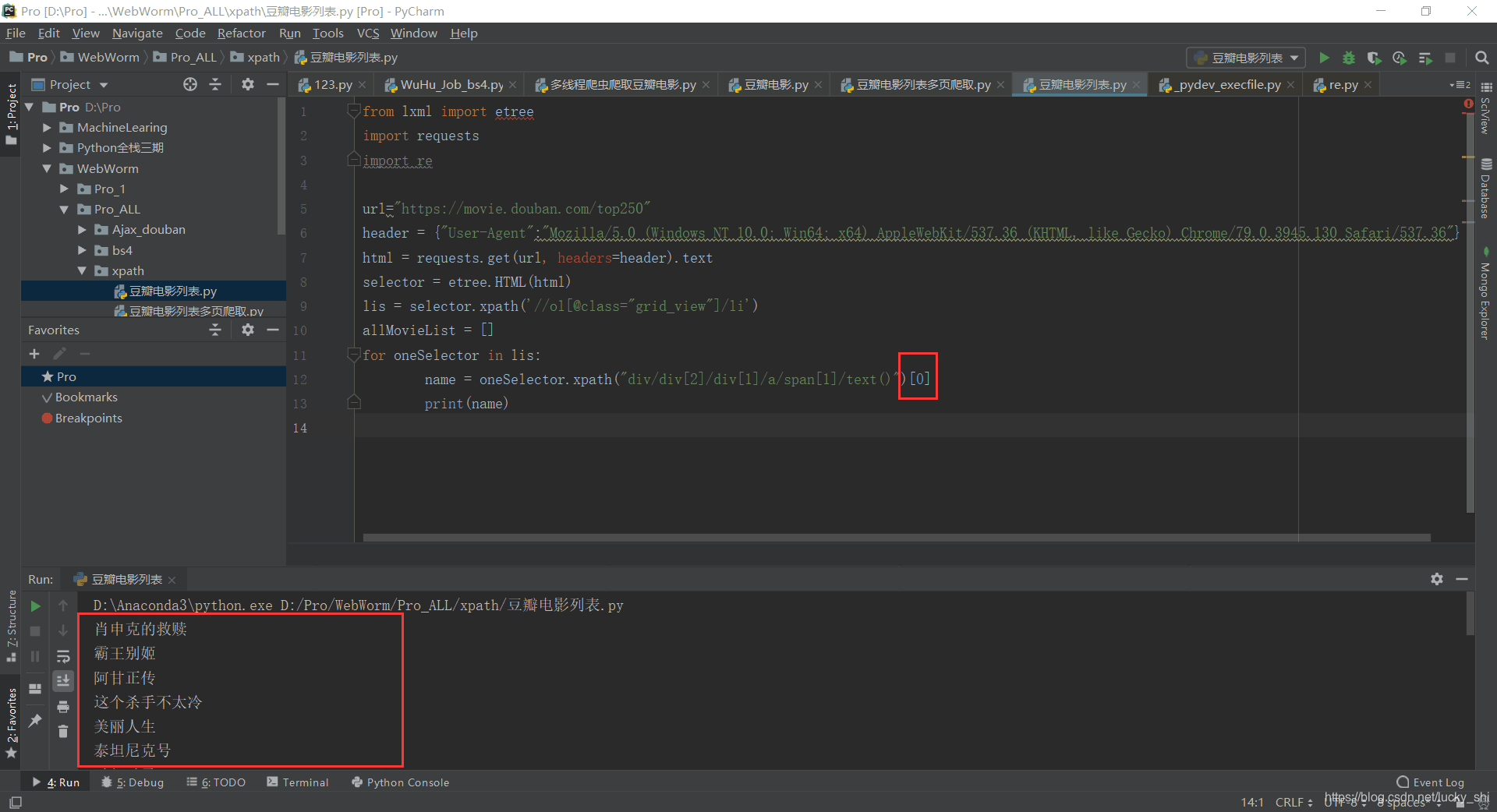
①title中[0], score中[0], people中[0]的作用
只保留文字部分,去除中括号和引号
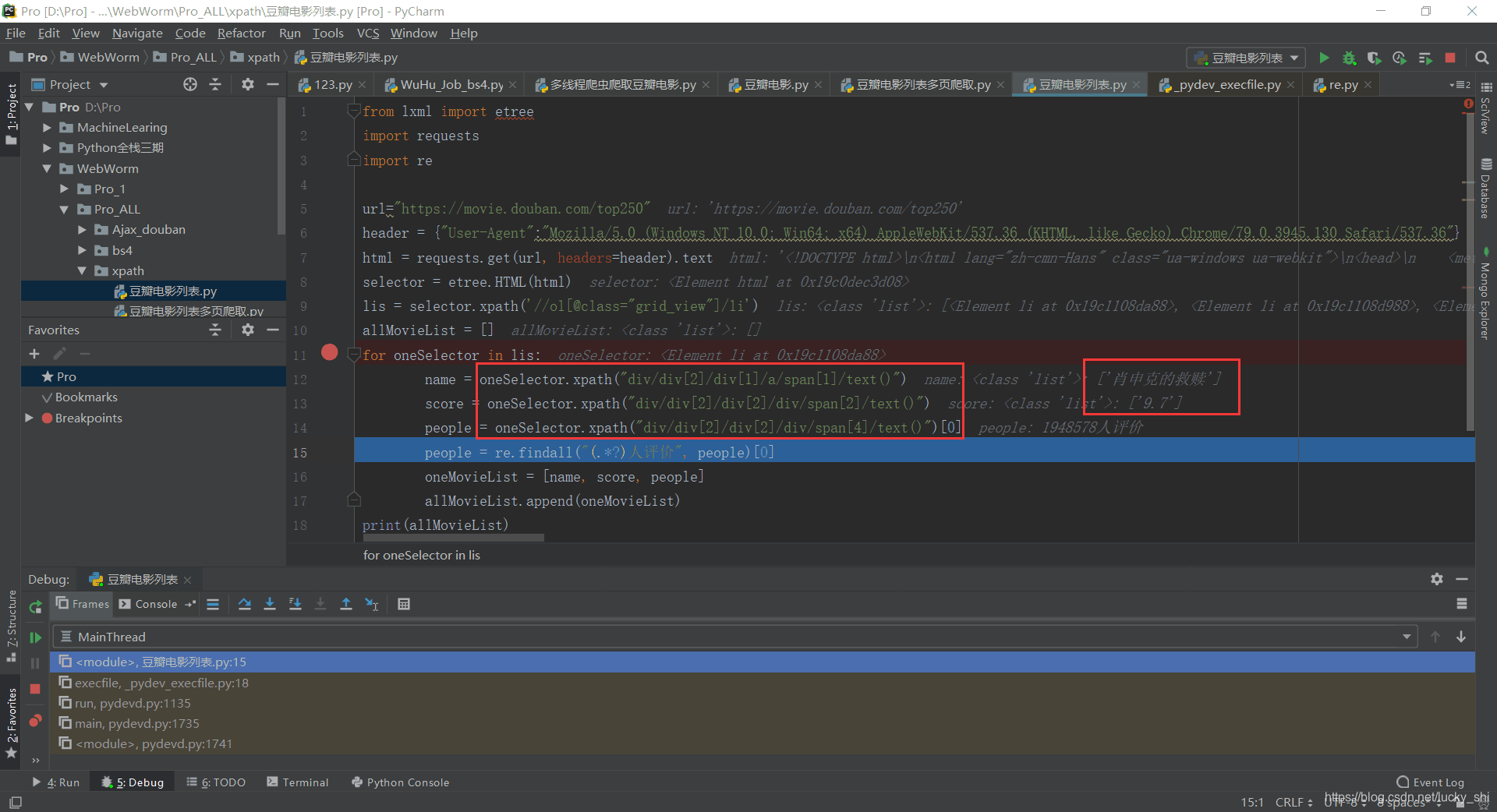
②people = re.findall("(.*?)人评价", people)[0]
报错:
people = oneSelector.xpath("div/div[2]/div[2]/div/span[4]/text()")
# ['1948578人评价']
people = re.findall("(.*?)人评价", people)[0]
# 报错
正确运行:
people = oneSelector.xpath("div/div[2]/div[2]/div/span[4]/text()")[0]
# 1948578人评价
people = re.findall("(.*?)人评价", people)[0]
# 1948578
要使用正则表达式re.findall()方法的前提是不含有中括号或则引号之类的符号,否则就会报错
