Python--机器学习之近邻协同过滤 [最幽默、最易懂的机器学习]
更多关于机器学习的知识请加关注哟~~。若需联系博主请私信或者加博主联系方式:
QQ:3327908431
微信:ZDSL1542334210
看这儿有货:机器学习,一个跨世纪的代名词,未来科技的主创者,人工智能的鼻祖。它为什么是时代先进的代表?华为老总任正非曾经说过:“大数据时代就是统计学”,大数据人工智能时代就是机器学习,而它就是基于统计学!嘿嘿,我是不会跟你说我是统计学,大家出去别说我是统计学专业。
那么什么是协同过滤?一句话概括就是:“物以类聚人以群分”。所以你选择来看朱哥的文章!毕竟朱哥我三岁识千字,五岁背唐诗,十里乡村有名的神童!但是岁月不饶人呐(抽泣中…),可惜啊,我都18岁了(大哭…),咋们继续…
1、什么是近邻协同过滤
就是找出物品间的相似度然后根据相似度进行推荐。它分为基于物品的协同过滤和基于用户的协同过滤。说白了就是如何让更多的人买更多不同的物品,所以搞这些的都是为了两个字----赚钱(这是好事,谁不喜欢钱?你要是不喜欢可以给我!给贫困山区的孩子一点帮助吧!微信联系方式在上面,当然了也支持QQ)。
1.1 基于物品的协同过滤
简单的解释就是你看一部电影比如说《战狼2》,然后系统把另外和《战狼2》相似的电影如《战狼1》、《红海行动》推荐在主页给你,这就是基于物品的协同过滤,简记为:希望你一人买更多类似的东西。
1.2 基于用户的协同过滤
举个例子,你看小熊、亮哥是好朋友对吧,然后小熊呢喜欢看某岛国电影《牙买跌》,结果呢系统把电影《牙买跌》推荐给亮哥,这个就是基于用户的协同过滤,简记为:希望把某样东西推荐给更多性格相似的人(观众朋友你看他俩的性格就很像)。
2、相似何解
就是利用距离计算,根据历史数据计算物品间或人之间的距离,距离最近的就可以归一类,说明相似。在这里是先将数据转为二维表,如果是基于用户的就转为用户与用户间的二维表,是物品的就转为物品间对应的二维表。如有6人对6本不同的书评分如下:

从上表可以看到,每个用户对每本书的评分,那么我们要做的就是将图中空缺的值填充完整,然后排序后根据填写的值进行从大到小的推荐。那么这些空值怎么去填写呢?我们就会想到距离,没错,但是我们想到的是欧式距离,这是直接算距离来的。其实我们可以知道,每个用户都不止一维数据,所以我们更加关系的是这些用户在空间中的方向,而不是他们的普通距离,方向相同后说明这两个用户是相似的。所以我们用到余弦相关系数:
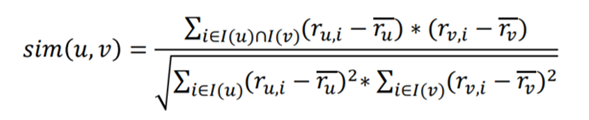
这里,我们强大的Python里面是有相对的库,所以不用手敲代码。通过该计算后得到下方的二维表。
2.1 基于用户的协同过滤相似关系图解
那么他们对应的相似关系二维表为:
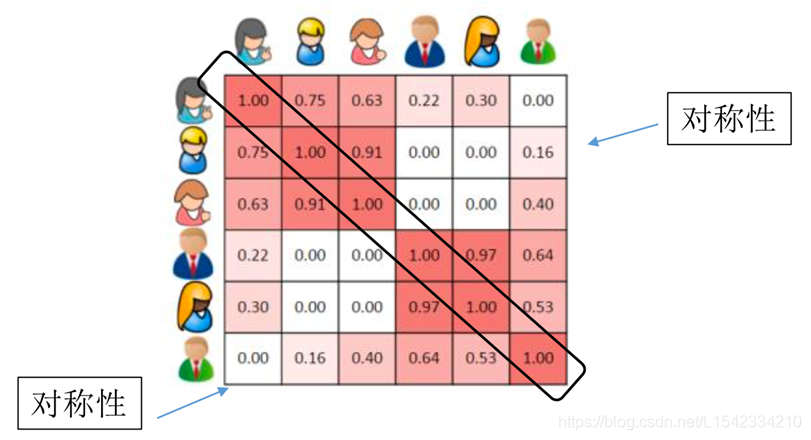
这样一来,就可以找到每个用户究竟跟多少个用户最相似了。就可以把相似的用户买的物品推荐给其他与他相似的用户。
2.2 基于物品的协同过滤相似关系图解
该表也是由用户对该书本的评分得来,因为我们要以用户的眼光来判断它们的相似度,而不是他们本身的相似度,我们的目标和眼光永远放在用户身上。
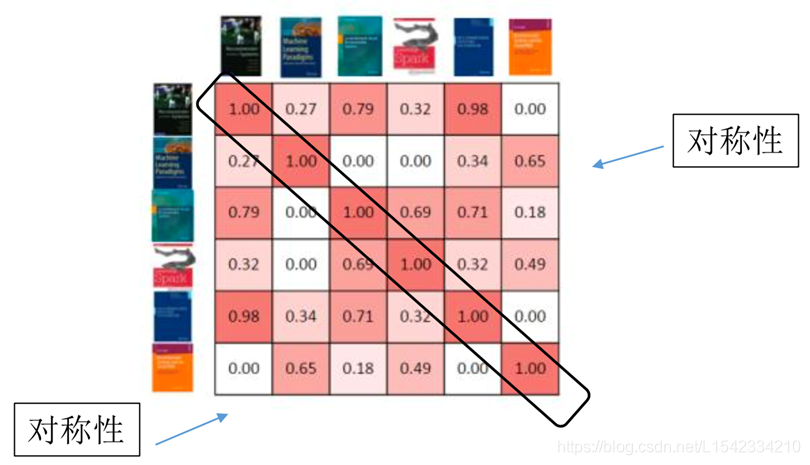
这样一来,就可以找到每个物品在用户眼光下究竟和那几个物品最相似。就可以把相似的物品推荐给他。
4、数据做基于用户的近邻协同过滤
#导包
import pandas as pd
import numpy as np
dat='example.txt' # 读入数据 该数据就是 第一张截图里面的表格数据
df = pd.read_csv(dat,header=None)
df.columns=['用户id','物品id','喜好程度'] # 修改列名
# 构建第二张截图的矩阵数据
df_pivot = df.pivot(index="用户id",columns="物品id",values="喜好程度")
freq = df_pivot.fillna(0) #将缺失值填为0
#在sklearn中有自带的余弦相似度计算函数
from sklearn.metrics.pairwise import cosine_similarity
user_similar = cosine_similarity(freq_matrix)
##画热力图来看一下,比较好看
import matplotlib.pyplot as plt
import seaborn as sns
sns.heatmap(user_similar,annot=True,cbar=False)
plt.show(); #热力图
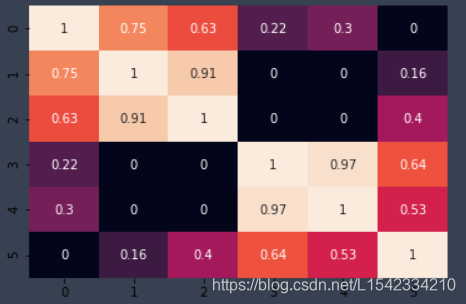
颜色越浅,代表相似性越差。
假如说我们现在想给第3个用户推荐第5个商品,计算其得分
user_id_action = freq_matrix[2,:] #取出第三个用户的评分向量
item_id_action = freq_matrix[:,4] #取出用户对第五个物品的评分向量
#假如说我们现在想要找出和该用户最相似的三个用户 k=3
#那么应该从这个user_similar 矩阵中提取出三个最大的值,所对应的用户
k = 3
score = 0 #用于计算评分的分子
weight = 0 #用于计算评分的分母 最终得分为 score/weight,因为给用户相似度一个权重
user_id = 2 #第三个用户
item_id = 4 #第五个用户
similar_index =np.argsort(user_similar[user_id])[::-1][1:k+1] #索引出和第三个用户相似的前三个用户
similar_index # 结果为 1,0,5 说明1,0,5在第五个物品选择上和第三位用户最相似
计算用户评分平均值
因为评分的值差距太大,而权重的取值为0-1,不好给权重,所以将评分标准化,使用标准化后的数据:
#构建一个基于用户和物品的推荐
def Recommendation_mean(user_id,item_id,similar,k=10):
"""减去平均数的计算方法:
user_id:输入用户ID
item_id:物品ID
similar:计算好余弦距离后的矩阵
k:以计算几个最相近的用户,默认值为10"""
score = 0
weight = 0
user_id_action = freq_matrix[user_id,:] #用户user_id 对所有商品的行为评分
item_id_action = freq_matrix[:,item_id] #物品item_id 得到的所有用户评分
user_id_similar = similar[user_id,:] #用户user_id 对所有用户的相似度
similar_index = np.argsort(user_id_similar)[-(k+1):-1] #最相似的k个用户的index(除了自己)
user_id_i_mean = np.sum(user_id_action)/user_id_action[user_id_action!=0].size# 算出平均值
for j in similar_index :
if item_id_action[j]!=0: #找到物品评分不为零的值
user_id_j_action = freq_matrix[j,:]
user_id_j_mean = np.sum(user_id_j_action)/user_id_j_action[user_id_j_action!=0].size
score += user_id_similar[j]*(item_id_action[j]-user_id_j_mean) #计算该物品的评分均值
weight += abs(user_id_similar[j]) # 得到权重
if weight==0:
return 0
else:
return user_id_j_mean + score/float(weight) #计算最终得分
构建预测函数,将每一个用户对应每一个物品的分数填写完整
#构建预测函数
def predict_mean(user_similar):
"""预测函数的功能: 传入相似度矩阵, 通过对每个用户和每个物品进行计算, 计算出一个推荐矩阵"""
user_count = freq_matrix.shape[0]#用户数
item_count = freq_matrix.shape[1]#商品数
predic_matrix = np.zeros((user_count,item_count))
print(user_count)
for user_id in range(user_count):
print(user_id)
for item_id in range(item_count):
if freq_matrix[user_id,item_id] == 0:
#print (user_id,item_id)
predic_matrix[user_id,item_id] = Recommendation_mean(user_id,item_id,user_similar) #调用函数,求出每一个空值对应的分数,如果数据太大时间会很长。
return predic_matrix #返回一个填补完空值的得分表
得到分数矩阵
user_prediction_matrix = predict_mean(user_similar) #得到每一个用户对应每一个物品的分数
user_prediction_matrix

取出前几个推荐的物品
def get_topk(group,n):
# 返回排序后的前n个值
return group.sort_values("推荐指数",ascending=False)[:n]
def get_recommendation(user_prediction_matrix,n=5):
# 将用户预测数据, 构建成一个DataFrame
recommendation_df = pd.DataFrame(user_prediction_matrix,columns=freq.columns,index=freq.index)
# 将数据进行转换
recommendation_df = recommendation_df.stack().reset_index() # reset_index重置索引stack将其行索引变成列索引
# 对列名进行修改
recommendation_df.rename(columns={0:"推荐指数"},inplace=True)
# 根据用户ID列进行分组
grouped = recommendation_df.groupby("用户id")
# 得到分组后的前几个数据
topk = grouped.apply(get_topk,n=n) #的返回值就是func()的返回值
# 删除掉用户ID列
topk = topk.drop(["用户id"],axis=1)
# 删除掉多余的索引
topk.index = topk.index.droplevel(1)
# 索引重排
topk.reset_index(inplace=True)
return topk
调用函数
n=5 #取出前5个 要几个就修改这里就可以了
get_recommendatios=get_recommendation(user_prediction_matrix,n)
get_recommendatios #得到每个用户的前5个推荐的书本编号
说明:如果要做基于物品的临近协同过滤,只需要将df_pivot 转置一下就可以了,代码一样,就不一一赘述。
5、文末彩蛋–轻松一刻
大家都知道嘛,我好朋友亮哥是出了名的吵嘴王,这不是之前国庆假期嘛,我寻思着没事去他家找他玩,我两就在看电影,这结果呢,他爸出来了,看他在玩就说:“都快25岁的人了,还一事无成,成天就知道玩,看看别人家的旺财跟你一样大都开公司了。”然后我亮哥当时就不乐意了,回了一句,给我吓坏了,他说“那你跟马云还一样大呢,看看人家…”结果他老爸顿时无声,瞪大眼睛看他,说道:“马云之所以厉害,因为他有一个好儿子…还有一些正能量的好朋友…”。所以说真是有其父必有其子,他爷俩都挺能吵的,就是这么个情况。
今天到这里就结束了哟//每篇文章都有文末彩蛋–轻松一刻哟~加关注学习更多机器学习知识!谢谢观看,我是Jetuser-data
链接: [https://blog.csdn.net/L1542334210]
CSND:L1542334210

祝大家工作顺利!阖家欢乐!
