给定数据集
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
n
,
y
n
)
}
\{(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\}
{ ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) }
x
i
=
(
x
i
1
;
x
i
2
;
x
i
3
;
.
.
.
;
x
i
d
)
,
代
表
样
本
;
y
i
∈
R
x_i = (x_{i1};x_{i2};x_{i3};...;x_{id}),代表样本;y_i\in R
x i = ( x i 1 ; x i 2 ; x i 3 ; . . . ; x i d ) , 代 表 样 本 ; y i ∈ R
n
n
n
d
d
d 这些特征满足线性关系,通过各个属性的线性组合就可以预测出目标值,而线性模型就是学习每个属性线性组合的方法,形成一个由样本属性到目标值的映射 。记为:
f
(
x
i
)
=
w
1
x
i
1
+
w
2
x
i
2
+
.
.
.
+
w
d
x
i
d
+
b
f(x_i)=w_1x_{i1}+w_2x_{i2}+...+w_dx_{id}+b
f ( x i ) = w 1 x i 1 + w 2 x i 2 + . . . + w d x i d + b
向量形式表示为:
f
(
x
)
=
w
T
x
+
b
f(\boldsymbol{x})=\boldsymbol{w}^T\boldsymbol{x}+b
f ( x ) = w T x + b
w
=
(
w
1
;
w
2
;
.
.
.
;
w
d
)
\boldsymbol{w}=(w_1;w_2;...;w_d)
w = ( w 1 ; w 2 ; . . . ; w d )
w
与
b
\boldsymbol{w}与b
w 与 b 线性模型形式简单、易于建模,但却蕴含着机器学习中一些重要的基本思想,许多功能更为强大的非线性模型可以在线性模型的基础上通过引入层级结构或高维映射而得。此外,由于
w
\boldsymbol{w}
w
本文主要介绍线性回归模型。
线性回归顾名思义是一个回归模型,模型的额输出是连续值 ,常常用于股票预测,房价预测等等。
进入一家房产网,可以看到房价、面积、厅室呈现以下数据:
面积(
x
1
x_1
x 1
厅室数量(
x
2
)
x_2)
x 2 )
价格
y
y
y
64
3
25
59
3
185
65
3
208
116
4
508
……
……
……
我们可以将价格和面积、厅室数量的关系习得为
f
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
f(x)=\theta_0+\theta_1x_1+\theta_2x_2
f ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2
f
(
x
)
≈
y
f(x)\approx y
f ( x ) ≈ y
根据线性模型有:数据集
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
n
,
y
n
)
}
\{(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\}
{ ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) }
x
i
=
(
x
i
1
;
x
i
2
;
x
i
3
;
.
.
.
;
x
i
d
)
,
代
表
样
本
;
y
i
∈
R
x_i = (x_{i1};x_{i2};x_{i3};...;x_{id}),代表样本;y_i\in R
x i = ( x i 1 ; x i 2 ; x i 3 ; . . . ; x i d ) , 代 表 样 本 ; y i ∈ R
n
n
n
d
d
d
f
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
.
.
.
+
θ
d
x
d
=
∑
i
=
0
d
θ
i
x
i
\begin{aligned} f(x) &= \theta_0 + \theta_1x_1 + \theta_2x_2 + ... + \theta_dx_d \\ &= \sum_{i=0}^{d}\theta_ix_i \\ \end{aligned}
f ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ d x d = i = 0 ∑ d θ i x i
θ
\boldsymbol{\theta}
θ
f
(
x
)
f(x)
f ( x )
y
y
y
J
(
θ
)
=
1
2
∑
j
=
1
n
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
J(\theta)=\frac{1}{2}\sum_{j=1}^{n}(h_{\theta}(x^{(i)})-y^{(i)})^2
J ( θ ) = 2 1 j = 1 ∑ n ( h θ ( x ( i ) ) − y ( i ) ) 2
我们可以选择
θ
\theta
θ
θ
∗
=
arg
min
θ
J
(
θ
)
\boldsymbol{\theta}^*=\arg \min_{\theta}J(\boldsymbol{\theta})
θ ∗ = arg θ min J ( θ )
下面我们使用极大似然估计 ,来解释为什么要用均方误差作为性能度量。
我们可以把目标值和变量写成如下等式:
y
(
i
)
=
θ
T
x
(
i
)
+
ϵ
(
i
)
y^{(i)} = \theta^T x^{(i)}+\epsilon^{(i)}
y ( i ) = θ T x ( i ) + ϵ ( i )
ϵ
\epsilon
ϵ
ϵ
\epsilon
ϵ
p
(
ϵ
(
i
)
)
=
1
2
π
σ
e
x
p
(
−
(
ϵ
(
i
)
)
2
2
σ
2
)
p(\epsilon^{(i)}) = \frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(\epsilon^{(i)})^2}{2\sigma^2}\right)
p ( ϵ ( i ) ) = 2 π
σ 1 e x p ( − 2 σ 2 ( ϵ ( i ) ) 2 )
因此,
p
(
y
(
i
)
∣
x
(
i
)
;
θ
)
=
1
2
π
σ
e
x
p
(
−
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
2
σ
2
)
p(y^{(i)}|x^{(i)};\theta) = \frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(y^{(i)}-\theta^T x^{(i)})^2}{2\sigma^2}\right)
p ( y ( i ) ∣ x ( i ) ; θ ) = 2 π
σ 1 e x p ( − 2 σ 2 ( y ( i ) − θ T x ( i ) ) 2 )
我们建立极大似然函数,即描述数据遵从当前样本分布的概率分布函数。由于样本的数据集独立同分布,因此可以写成
L
(
θ
)
=
p
(
y
⃗
∣
X
;
θ
)
=
∏
i
=
1
n
1
2
π
σ
e
x
p
(
−
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
2
σ
2
)
L(\theta) = p(\vec y | X;\theta) = \prod^n_{i=1}\frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(y^{(i)}-\theta^T x^{(i)})^2}{2\sigma^2}\right)
L ( θ ) = p ( y
∣ X ; θ ) = i = 1 ∏ n 2 π
σ 1 e x p ( − 2 σ 2 ( y ( i ) − θ T x ( i ) ) 2 )
选择
θ
\theta
θ
为了方便计算,我们计算时通常对对数似然函数 求最大值:
l
(
θ
)
=
l
o
g
L
(
θ
)
=
l
o
g
∏
i
=
1
n
1
2
π
σ
e
x
p
(
−
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
2
σ
2
)
=
∑
i
=
1
n
l
o
g
1
2
π
σ
e
x
p
(
−
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
2
σ
2
)
=
n
l
o
g
1
2
π
σ
−
1
σ
2
⋅
1
2
∑
i
=
1
n
(
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
\begin{aligned} l(\theta) &= log L(\theta) = log \prod^n_{i=1}\frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(y^{(i)}-\theta^T x^{(i)})^2} {2\sigma^2}\right) \\ & = \sum^n_{i=1}log\frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(y^{(i)}-\theta^T x^{(i)})^2}{2\sigma^2}\right) \\ & = nlog\frac{1}{{\sqrt{2\pi}\sigma}} - \frac{1}{\sigma^2} \cdot \frac{1}{2}\sum^n_{i=1}((y^{(i)}-\theta^T x^{(i)})^2 \end{aligned}
l ( θ ) = l o g L ( θ ) = l o g i = 1 ∏ n 2 π
σ 1 e x p ( − 2 σ 2 ( y ( i ) − θ T x ( i ) ) 2 ) = i = 1 ∑ n l o g 2 π
σ 1 e x p ( − 2 σ 2 ( y ( i ) − θ T x ( i ) ) 2 ) = n l o g 2 π
σ 1 − σ 2 1 ⋅ 2 1 i = 1 ∑ n ( ( y ( i ) − θ T x ( i ) ) 2
l
(
θ
)
l(\theta)
l ( θ )
1
2
∑
i
=
1
n
(
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
\frac{1}{2}\sum^n_{i=1}((y^{(i)}-\theta^T x^{(i)})^2
2 1 ∑ i = 1 n ( ( y ( i ) − θ T x ( i ) ) 2
这一结果即均方误差,因此用这个值作为代价函数来优化模型在统计学的角度是合理的。
损失函数(Loss Function):度量单样本预测的错误程度,损失函数值越小,模型就越好。
代价函数(Cost Function):度量全部样本集的平均误差。
目标函数(Object Function):代价函数和正则化函数,最终要优化的函数。
常用的损失函数包括:
0-1损失函数;
平方损失函数;
绝对损失函数;
对数损失函数等。
均方误差;
均方根误差;
平均绝对误差等。
既然代价函数已经可以度量样本集的平均误差,为什么还要设定目标函数?
当模型复杂度增加时,有可能对训练集可以拟合的很好,但是测试集的效果不好,出现了过拟合现象,这就出现了所谓的“结构化风险”。结构风险最小化即为了防止过拟合而提出来的策略,定义模型复杂度为
J
(
F
)
J(F)
J ( F )
m
i
n
f
∈
F
1
n
∑
i
=
1
n
L
(
y
i
,
f
(
x
i
)
)
+
λ
J
(
F
)
\underset{f\in F}{min}\, \frac{1}{n}\sum^{n}_{i=1}L(y_i,f(x_i))+\lambda J(F)
f ∈ F min n 1 i = 1 ∑ n L ( y i , f ( x i ) ) + λ J ( F )
例如有以上6个房价和面积关系的数据点,可以看到,当设定
f
(
x
)
=
∑
j
=
0
5
θ
j
x
j
f(x)=\sum_{j=0}^{5}\theta_jx_j
f ( x ) = ∑ j = 0 5 θ j x j 模型复杂度产生的主要原因是
θ
\theta
θ
L1正则指的就是把每个参数的绝对值作为惩罚项加入到目标函数中。
J
(
θ
)
=
1
2
∑
i
=
1
n
L
(
y
i
,
f
(
x
i
)
)
+
λ
∑
j
=
1
d
∣
θ
j
∣
J(\boldsymbol{\theta})=\frac{1}{2}\sum\limits_{i=1}^nL(y_i,f(x_i))+\lambda\sum_{j=1}^d|\theta_j|
J ( θ ) = 2 1 i = 1 ∑ n L ( y i , f ( x i ) ) + λ j = 1 ∑ d ∣ θ j ∣
L2正则指的是把每个参数的平方作为惩罚项加入到目标函数中。
J
(
θ
)
=
1
2
∑
i
=
1
n
L
(
y
i
,
f
(
x
i
)
)
+
λ
∑
j
=
1
d
(
θ
j
)
2
J(\boldsymbol{\theta})=\frac{1}{2}\sum\limits_{i=1}^nL(y_i,f(x_i))+\lambda\sum_{j=1}^d(\theta_j)^2
J ( θ ) = 2 1 i = 1 ∑ n L ( y i , f ( x i ) ) + λ j = 1 ∑ d ( θ j ) 2
Elastic Net回归指的是将L1正则和L2正咋按一定比例混合起来。
J
(
θ
)
=
1
2
∑
i
=
1
n
L
(
y
i
,
f
(
x
i
)
)
+
λ
(
ρ
∑
j
=
1
d
∣
θ
j
∣
+
(
1
−
ρ
)
∑
j
=
1
d
(
θ
j
)
2
)
J(\boldsymbol{\theta})=\frac{1}{2}\sum\limits_{i=1}^nL(y_i,f(x_i))+\lambda(\rho\sum_{j=1}^d|\theta_j|+(1-\rho)\sum_{j=1}^d(\theta_j)^2)
J ( θ ) = 2 1 i = 1 ∑ n L ( y i , f ( x i ) ) + λ ( ρ j = 1 ∑ d ∣ θ j ∣ + ( 1 − ρ ) j = 1 ∑ d ( θ j ) 2 ) L1正则会趋向于产生少量的特征,其他的特征都是0,而L2正则会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。在所有特征中只有少数特征起重要作用的情况下,选择Lasso比较合适,因为它能自动选择特征。而如果所有特征中,大部分特征都能起作用,而且起的作用很平均,那么使用Ridge也许更合适。
设定初始参数
θ
\theta
θ
J
(
θ
)
J(\theta)
J ( θ )
θ
j
:
=
θ
j
−
α
∂
J
(
θ
)
∂
θ
\theta_j:=\theta_j-\alpha\frac{\partial{J(\theta)}}{\partial\theta}
θ j : = θ j − α ∂ θ ∂ J ( θ )
其中导数为:
∂
J
(
θ
)
∂
θ
=
∂
∂
θ
j
1
2
∑
i
=
1
n
(
f
θ
(
x
)
(
i
)
−
y
(
i
)
)
2
=
2
∗
1
2
∑
i
=
1
n
(
f
θ
(
x
)
(
i
)
−
y
(
i
)
)
∗
∂
∂
θ
j
(
f
θ
(
x
)
(
i
)
−
y
(
i
)
)
=
∑
i
=
1
n
(
f
θ
(
x
)
(
i
)
−
y
(
i
)
)
∗
∂
∂
θ
j
(
∑
j
=
0
d
θ
j
x
j
(
i
)
−
y
(
i
)
)
)
=
∑
i
=
1
n
(
f
θ
(
x
)
(
i
)
−
y
(
i
)
)
x
j
(
i
)
\begin{aligned} \frac{\partial{J(\theta)}}{\partial\theta} &= \frac{\partial}{\partial\theta_j}\frac{1}{2}\sum_{i=1}^{n}(f_\theta(x)^{(i)}-y^{(i)})^2 \\ &= 2*\frac{1}{2}\sum_{i=1}^{n}(f_\theta(x)^{(i)}-y^{(i)})*\frac{\partial}{\partial\theta_j}(f_\theta(x)^{(i)}-y^{(i)}) \\ &= \sum_{i=1}^{n}(f_\theta(x)^{(i)}-y^{(i)})*\frac{\partial}{\partial\theta_j}(\sum_{j=0}^{d}\theta_jx_j^{(i)}-y^{(i)}))\\ &= \sum_{i=1}^{n}(f_\theta(x)^{(i)}-y^{(i)})x_j^{(i)} \\ \end{aligned}
∂ θ ∂ J ( θ ) = ∂ θ j ∂ 2 1 i = 1 ∑ n ( f θ ( x ) ( i ) − y ( i ) ) 2 = 2 ∗ 2 1 i = 1 ∑ n ( f θ ( x ) ( i ) − y ( i ) ) ∗ ∂ θ j ∂ ( f θ ( x ) ( i ) − y ( i ) ) = i = 1 ∑ n ( f θ ( x ) ( i ) − y ( i ) ) ∗ ∂ θ j ∂ ( j = 0 ∑ d θ j x j ( i ) − y ( i ) ) ) = i = 1 ∑ n ( f θ ( x ) ( i ) − y ( i ) ) x j ( i )
θ
j
=
θ
j
+
α
∑
i
=
1
n
(
y
(
i
)
−
f
θ
(
x
)
(
i
)
)
x
j
(
i
)
\theta_j = \theta_j + \alpha\sum_{i=1}^{n}(y^{(i)}-f_\theta(x)^{(i)})x_j^{(i)}
θ j = θ j + α i = 1 ∑ n ( y ( i ) − f θ ( x ) ( i ) ) x j ( i )
注:下标j表示第
j
j
j
i
i
i
i
i
i
将所有的参数以向量形式表示,可得:
θ
=
θ
+
α
∑
i
=
1
n
(
y
(
i
)
−
f
θ
(
x
)
(
i
)
)
x
(
i
)
\theta = \theta + \alpha\sum_{i=1}^{n}(y^{(i)}-f_\theta(x)^{(i)})x^{(i)}
θ = θ + α i = 1 ∑ n ( y ( i ) − f θ ( x ) ( i ) ) x ( i )
由于这个方法中,参数在每一个数据点上同时进行了移动,因此称为批梯度下降法,对应的,我们可以每一次让参数只针对一个数据点进行移动,即:
θ
=
θ
+
α
(
y
(
i
)
−
f
θ
(
x
)
(
i
)
)
x
(
i
)
\theta = \theta + \alpha(y^{(i)}-f_\theta(x)^{(i)})x^{(i)}
θ = θ + α ( y ( i ) − f θ ( x ) ( i ) ) x ( i )
这个算法成为随机梯度下降法,随机梯度下降法的好处是,当数据点很多时,运行效率更高;缺点是,因为每次只针对一个样本更新参数,未必找到最快路径达到最优值,甚至有时候会出现参数在最小值附近徘徊而不是立即收敛。但当数据量很大的时候,随机梯度下降法经常优于批梯度下降法。
当
J
J
J
θ
\theta
θ
梯度下降法的缺陷:如果函数为非凸函数,有可能找到的并非全局最优值,而是局部最优值。批量梯度下降法(BGD)、随机梯度下降法(SGD)和小批量梯度下降法(MBGD)对比:
1.批量梯度下降法 是最原始的形式,它是指在每一次迭代时使用所有样本来进行梯度的更新。优点 :
一次迭代是对所有样本进行计算,此时利用矩阵进行操作,可实现并行。
由全数据集确定的方向能更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时,一定能找到全局最优。
缺点 :
当样本数目较大时,每迭代一次就要对所有样本进行计算,训练过程慢。
2.随机梯度下降法 不同于批量梯度下降,随机梯度下降是每次迭代使用一个样本来对参数进行更新。使得训练速度加快。优点 :
一次迭代只对一个样本进行计算,然后更新参数,训练速度大大加快。
缺点 :
准确率下降,即使是凸函数也不一定能收敛到全局最优。
单个样本不能代表训练集的总体趋势,每次只计算一个样本,不易于并行计算。
3.小批量梯度下降,是对批量梯度下降以及随机梯度下降的一个折中办法。其思想是:每次迭代 使用batch_size 个样本来对参数进行更新。优点 :
通过矩阵运算,每一个batch更新网络参数速度比单个样本慢不了多少。
每次使用一个batch,可以大大减少收敛所需要的迭代次数,更接近梯度下降的效果。
可以实现并行计算
缺点 :
每一个batch的大小选择可能会造成一些问题。
令
X
=
[
(
x
(
1
)
)
T
(
x
(
2
)
)
T
…
(
x
(
n
)
)
T
]
X = \left[ \begin{array} {cccc} (x^{(1)})^T\\ (x^{(2)})^T\\ \ldots \\ (x^{(n)})^T \end{array} \right]
X = ⎣ ⎢ ⎢ ⎡ ( x ( 1 ) ) T ( x ( 2 ) ) T … ( x ( n ) ) T ⎦ ⎥ ⎥ ⎤
其中,
x
(
i
)
=
[
x
1
(
i
)
x
2
(
i
)
…
x
d
(
i
)
]
x^{(i)} = \left[ \begin{array} {cccc} x_1^{(i)}\\ x_2^{(i)}\\ \ldots \\ x_d^{(i)} \end{array} \right]
x ( i ) = ⎣ ⎢ ⎢ ⎢ ⎡ x 1 ( i ) x 2 ( i ) … x d ( i ) ⎦ ⎥ ⎥ ⎥ ⎤
由于
Y
=
[
y
(
1
)
y
(
2
)
…
y
(
n
)
]
Y = \left[ \begin{array} {cccc} y^{(1)}\\ y^{(2)}\\ \ldots \\ y^{(n)} \end{array} \right]
Y = ⎣ ⎢ ⎢ ⎡ y ( 1 ) y ( 2 ) … y ( n ) ⎦ ⎥ ⎥ ⎤
h
θ
(
x
)
h_\theta(x)
h θ ( x )
h
θ
(
x
)
=
X
θ
h_\theta(x)=X\theta
h θ ( x ) = X θ
对于向量来说,有
z
T
z
=
∑
i
z
i
2
z^Tz = \sum_i z_i^2
z T z = i ∑ z i 2
因此可以把损失函数写作
J
(
θ
)
=
1
2
(
X
θ
−
Y
)
T
(
X
θ
−
Y
)
J(\theta)=\frac{1}{2}(X\theta-Y)^T(X\theta-Y)
J ( θ ) = 2 1 ( X θ − Y ) T ( X θ − Y )
为最小化
J
(
θ
)
J(\theta)
J ( θ )
θ
\theta
θ
∂
J
(
θ
)
∂
θ
=
∂
∂
θ
1
2
(
X
θ
−
Y
)
T
(
X
θ
−
Y
)
=
1
2
∂
∂
θ
(
θ
T
X
T
X
θ
−
Y
T
X
θ
−
θ
T
X
T
Y
−
Y
T
Y
)
\begin{aligned} \frac{\partial{J(\theta)}}{\partial\theta} &= \frac{\partial}{\partial\theta} \frac{1}{2}(X\theta-Y)^T(X\theta-Y) \\ &= \frac{1}{2}\frac{\partial}{\partial\theta} (\theta^TX^TX\theta - Y^TX\theta-\theta^T X^TY - Y^TY) \\ \end{aligned}
∂ θ ∂ J ( θ ) = ∂ θ ∂ 2 1 ( X θ − Y ) T ( X θ − Y ) = 2 1 ∂ θ ∂ ( θ T X T X θ − Y T X θ − θ T X T Y − Y T Y )
∂
J
(
θ
)
∂
θ
=
1
2
∂
∂
θ
(
θ
T
X
T
X
θ
−
2
θ
T
X
T
Y
−
Y
T
Y
)
\begin{aligned} \frac{\partial{J(\theta)}}{\partial\theta} &= \frac{1}{2}\frac{\partial}{\partial\theta} (\theta^TX^TX\theta - 2\theta^T X^TY - Y^TY) \\ \end{aligned}
∂ θ ∂ J ( θ ) = 2 1 ∂ θ ∂ ( θ T X T X θ − 2 θ T X T Y − Y T Y )
令偏导数等于零,由于最后一项和
θ
\theta
θ
∂
J
(
θ
)
∂
θ
=
1
2
∂
∂
θ
θ
T
X
T
X
θ
−
∂
∂
θ
θ
T
X
T
Y
\frac{\partial{J(\theta)}}{\partial\theta} = \frac{1}{2}\frac{\partial}{\partial\theta} \theta^TX^TX\theta - \frac{\partial}{\partial\theta} \theta^T X^TY
∂ θ ∂ J ( θ ) = 2 1 ∂ θ ∂ θ T X T X θ − ∂ θ ∂ θ T X T Y
利用矩阵求导性质:
∂
x
⃗
T
α
∂
x
⃗
=
α
\frac{\partial \vec x^T\alpha}{\partial \vec x} =\alpha
∂ x
∂ x
T α = α
∂
A
T
B
∂
x
⃗
=
∂
A
T
∂
x
⃗
B
+
∂
B
T
∂
x
⃗
A
\frac{\partial A^TB}{\partial \vec x} = \frac{\partial A^T}{\partial \vec x}B + \frac{\partial B^T}{\partial \vec x}A
∂ x
∂ A T B = ∂ x
∂ A T B + ∂ x
∂ B T A
∂
∂
θ
θ
T
X
T
X
θ
=
∂
∂
θ
(
X
θ
)
T
X
θ
=
∂
(
X
θ
)
T
∂
θ
X
θ
+
∂
(
X
θ
)
T
∂
θ
X
θ
=
2
X
T
X
θ
\begin{aligned} \frac{\partial}{\partial\theta} \theta^TX^TX\theta &= \frac{\partial}{\partial\theta}{(X\theta)^TX\theta}\\ &= \frac{\partial (X\theta)^T}{\partial\theta}X\theta + \frac{\partial (X\theta)^T}{\partial\theta}X\theta \\ &= 2X^TX\theta \end{aligned}
∂ θ ∂ θ T X T X θ = ∂ θ ∂ ( X θ ) T X θ = ∂ θ ∂ ( X θ ) T X θ + ∂ θ ∂ ( X θ ) T X θ = 2 X T X θ
∂
J
(
θ
)
∂
θ
=
X
T
X
θ
−
X
T
Y
\frac{\partial{J(\theta)}}{\partial\theta} = X^TX\theta - X^TY
∂ θ ∂ J ( θ ) = X T X θ − X T Y
令导数等于零,
X
T
X
θ
=
X
T
Y
X^TX\theta = X^TY
X T X θ = X T Y
θ
=
(
X
T
X
)
(
−
1
)
X
T
Y
\theta = (X^TX)^{(-1)}X^TY
θ = ( X T X ) ( − 1 ) X T Y
若
(
X
T
X
)
(X^TX)
( X T X )
(
X
T
X
)
(X^TX)
( X T X )
λ
\lambda
λ
X
T
X
+
λ
I
X^TX+\lambda I
X T X + λ I
θ
=
(
X
T
X
+
λ
I
)
(
−
1
)
X
T
Y
\theta = (X^TX+\lambda I)^{(-1)}X^TY
θ = ( X T X + λ I ) ( − 1 ) X T Y
f
(
θ
)
′
=
f
(
θ
)
Δ
,
Δ
=
θ
0
−
θ
1
f(\theta)' = \frac{f(\theta)}{\Delta},\Delta = \theta_0 - \theta_1
f ( θ ) ′ = Δ f ( θ ) , Δ = θ 0 − θ 1
可
求
得
,
θ
1
=
θ
0
−
f
(
θ
0
)
f
(
θ
0
)
′
可求得,\theta_1 = \theta_0 - \frac {f(\theta_0)}{f(\theta_0)'}
可 求 得 , θ 1 = θ 0 − f ( θ 0 ) ′ f ( θ 0 )
重复迭代,可以让逼近取到
f
(
θ
)
f(\theta)
f ( θ )
当我们对损失函数
l
(
θ
)
l(\theta)
l ( θ )
l
′
(
θ
)
l'(\theta)
l ′ ( θ )
θ
:
=
θ
−
l
′
(
θ
)
l
′
′
(
θ
)
\theta :=\theta-\frac{l'(\theta)}{l''(\theta)}
θ : = θ − l ′ ′ ( θ ) l ′ ( θ )
当
θ
是
向
量
值
的
时
候
,
θ
:
=
θ
−
H
−
1
Δ
θ
l
(
θ
)
当\theta是向量值的时候,\theta :=\theta - H^{-1}\Delta_{\theta}l(\theta)
当 θ 是 向 量 值 的 时 候 , θ : = θ − H − 1 Δ θ l ( θ )
其中,
Δ
θ
l
(
θ
)
\Delta_{\theta}l(\theta)
Δ θ l ( θ )
l
(
θ
)
l(\theta)
l ( θ )
θ
i
\theta_i
θ i
H
H
H
J
(
θ
)
J(\theta)
J ( θ )
H
i
j
=
∂
2
l
(
θ
)
∂
θ
i
∂
θ
j
H_{ij} = \frac{\partial ^2l(\theta)}{\partial\theta_i\partial\theta_j}
H i j = ∂ θ i ∂ θ j ∂ 2 l ( θ )
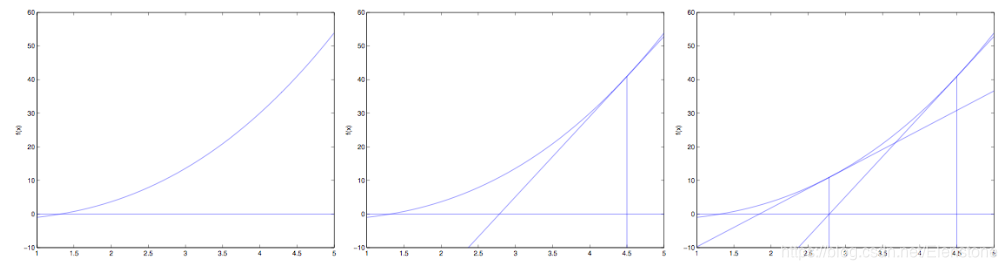
问题:请用泰勒展开法推导牛顿法公式。
Answer:将
f
(
x
)
f(x)
f ( x )
f
(
x
)
=
f
(
x
0
)
+
f
′
(
x
0
)
(
x
−
x
0
)
+
1
2
f
′
′
(
x
0
)
(
x
−
x
0
)
2
f(x) = f(x_0) + f'(x_0)(x - x_0)+\frac{1}{2}f''(x_0)(x - x_0)^2
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + 2 1 f ′ ′ ( x 0 ) ( x − x 0 ) 2
对上式求导,并令导数等于0,求得x值
f
′
(
x
)
=
f
′
(
x
0
)
+
f
′
′
(
x
0
)
x
−
f
′
′
(
x
0
)
x
0
=
0
f'(x) = f'(x_0) + f''(x_0)x -f''(x_0)x_0 = 0
f ′ ( x ) = f ′ ( x 0 ) + f ′ ′ ( x 0 ) x − f ′ ′ ( x 0 ) x 0 = 0
可以求得,
x
=
x
0
−
f
′
(
x
0
)
f
′
′
(
x
0
)
x = x_0 - \frac{f'(x_0)}{f''(x_0)}
x = x 0 − f ′ ′ ( x 0 ) f ′ ( x 0 )
牛顿法的收敛速度非常快,但海森矩阵的计算较为复杂,尤其当参数的维度很多时,会耗费大量计算成本。我们可以用其他矩阵替代海森矩阵,用拟牛顿法进行估计,
拟牛顿法的思路是用一个矩阵替代计算复杂的海森矩阵H,因此要找到符合H性质的矩阵。
要求得海森矩阵符合的条件,同样对泰勒公式求导
f
′
(
x
)
=
f
′
(
x
0
)
+
f
′
′
(
x
0
)
x
−
f
′
′
(
x
0
)
x
0
f'(x) = f'(x_0) + f''(x_0)x -f''(x_0)x_0
f ′ ( x ) = f ′ ( x 0 ) + f ′ ′ ( x 0 ) x − f ′ ′ ( x 0 ) x 0
令
x
=
x
1
x = x_1
x = x 1
f
′
(
x
1
)
=
f
′
(
x
0
)
+
f
′
′
(
x
0
)
x
1
−
f
′
′
(
x
0
)
x
0
f'(x_1) = f'(x_0) + f''(x_0)x_1 - f''(x_0)x_0
f ′ ( x 1 ) = f ′ ( x 0 ) + f ′ ′ ( x 0 ) x 1 − f ′ ′ ( x 0 ) x 0
更一般的,
f
′
(
x
k
+
1
)
=
f
′
(
x
k
)
+
f
′
′
(
x
k
)
x
k
+
1
−
f
′
′
(
x
k
)
x
k
f'(x_{k+1}) = f'(x_k) + f''(x_k)x_{k+1} - f''(x_k)x_k
f ′ ( x k + 1 ) = f ′ ( x k ) + f ′ ′ ( x k ) x k + 1 − f ′ ′ ( x k ) x k
f
′
(
x
k
+
1
)
−
f
′
(
x
k
)
=
f
′
′
(
x
k
)
(
x
k
+
1
−
x
k
)
=
H
(
x
k
+
1
−
x
k
)
f'(x_{k+1}) - f'(x_k) = f''(x_k)(x_{k+1}- x_k)= H(x_{k+1}- x_k)
f ′ ( x k + 1 ) − f ′ ( x k ) = f ′ ′ ( x k ) ( x k + 1 − x k ) = H ( x k + 1 − x k )
x
k
x_k
x k
即找到矩阵G,使得它符合上式。
均方误差(MSE):
1
m
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
\frac{1}{m}\sum^{m}_{i=1}(y^{(i)} - \hat y^{(i)})^2
m 1 ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2
均方根误差(RMSE):
M
S
E
=
1
m
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
\sqrt{MSE} = \sqrt{\frac{1}{m}\sum^{m}_{i=1}(y^{(i)} - \hat y^{(i)})^2}
M S E
= m 1 ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2
平均绝对误差(MAE):
1
m
∑
i
=
1
m
∣
(
y
(
i
)
−
y
^
(
i
)
∣
\frac{1}{m}\sum^{m}_{i=1} | (y^{(i)} - \hat y^{(i)} |
m 1 ∑ i = 1 m ∣ ( y ( i ) − y ^ ( i ) ∣
但以上评价指标都无法消除量纲不一致而导致的误差值差别大的问题,最常用的指标是
R
2
R^2
R 2
R
2
:
=
1
−
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
∑
i
=
1
m
(
y
ˉ
−
y
^
(
i
)
)
2
=
1
−
1
m
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
1
m
∑
i
=
1
m
(
y
ˉ
−
y
^
(
i
)
)
2
=
1
−
M
S
E
V
A
R
R^2: = 1-\frac{\sum^{m}_{i=1}(y^{(i)} - \hat y^{(i)})^2}{\sum^{m}_{i=1}(\bar y - \hat y^{(i)})^2} =1-\frac{\frac{1}{m}\sum^{m}_{i=1}(y^{(i)} - \hat y^{(i)})^2}{\frac{1}{m}\sum^{m}_{i=1}(\bar y - \hat y^{(i)})^2} = 1-\frac{MSE}{VAR}
R 2 : = 1 − ∑ i = 1 m ( y ˉ − y ^ ( i ) ) 2 ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 = 1 − m 1 ∑ i = 1 m ( y ˉ − y ^ ( i ) ) 2 m 1 ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 = 1 − V A R M S E
我们可以把
R
2
R^2
R 2
R
2
R^2
R 2
fit_intercept : 默认为True,是否计算该模型的截距。如果使用中心化的数据,可以考虑设置为False,不考虑截距。注意这里是考虑,一般还是要考虑截距
normalize: 默认为false. 当fit_intercept设置为false的时候,这个参数会被自动忽略。如果为True,回归器会标准化输入参数:减去平均值,并且除以相应的二范数。当然啦,在这里还是建议将标准化的工作放在训练模型之前。通过设置sklearn.preprocessing.StandardScaler来实现,而在此处设置为false
copy_X : 默认为True, 否则X会被改写
n_jobs: int 默认为1. 当-1时默认使用全部CPUs ??(这个参数有待尝试)
可用属性:
可用的methods:
fit(X,y,sample_weight=None):
X: array, 稀疏矩阵 [n_samples,n_features]
y: array [n_samples, n_targets]
sample_weight: 权重 array [n_samples]
get_params(deep=True): 返回对regressor 的设置值
predict(X): 预测 基于 R^2值
score: 评估
参考https://blog.csdn.net/weixin_39175124/article/details/79465558
生成数据
import numpy as np
np. random. seed( 1234 )
x = np. random. rand( 500 , 3 )
y = x. dot( np. array( [ 4.2 , 5.7 , 10.8 ] ) )
import numpy as np
from sklearn. linear_model import LinearRegression
import matplotlib. pyplot as plt
% matplotlib inline
lr = LinearRegression( fit_intercept= True )
lr. fit( x, y)
print ( "估计的参数值为:%s" % ( lr. coef_) )
print ( 'R2:%s' % ( lr. score( x, y) ) )
x_test = np. array( [ 2 , 4 , 5 ] ) . reshape( 1 , - 1 )
y_hat = lr. predict( x_test)
print ( "预测值为: %s" % ( y_hat) )
估计的参数值为:[ 4.2 5.7 10.8]
R2:1.0
预测值为: [85.2]
class LR_LS ( ) :
def __init__ ( self) :
self. w = None
def fit ( self, X, y) :
self. w = np. linalg. inv( X. T. dot( X) ) . dot( X. T) . dot( y)
def predict ( self, X) :
y_pred = X. dot( self. w)
return y_pred
if __name__ == "__main__" :
lr_ls = LR_LS( )
lr_ls. fit( x, y)
print ( "估计的参数值:%s" % ( lr_ls. w) )
x_test = np. array( [ 2 , 4 , 5 ] ) . reshape( 1 , - 1 )
print ( "预测值为: %s" % ( lr_ls. predict( x_test) ) )
估计的参数值:[ 4.2 5.7 10.8]
预测值为: [85.2]
3、梯度下降法
class LR_GD ( ) :
def __init__ ( self) :
self. w = None
def fit ( self, X, y, alpha= 0.02 , loss = 1e - 10 ) :
y = y. reshape( - 1 , 1 )
[ m, d] = np. shape( X)
self. w = np. zeros( ( d) )
tol = 1e5
while tol > loss:
h_f = X. dot( self. w) . reshape( - 1 , 1 )
theta = self. w + alpha* np. mean( X* ( y - h_f) , axis= 0 )
tol = np. sum ( np. abs ( theta - self. w) )
self. w = theta
def predict ( self, X) :
y_pred = X. dot( self. w)
return y_pred
if __name__ == "__main__" :
lr_gd = LR_GD( )
lr_gd. fit( x, y)
print ( "估计的参数值为:%s" % ( lr_gd. w) )
x_test = np. array( [ 2 , 4 , 5 ] ) . reshape( 1 , - 1 )
print ( "预测值为:%s" % ( lr_gd. predict( x_test) ) )
估计的参数值为:[ 4.20000001 5.70000003 10.79999997]
预测值为:[85.19999995]
吴恩达 CS229课程
周志华 《机器学习》
李航 《统计学习方法》
https://hangzhou.anjuke.com/
https://www.jianshu.com/p/e0eb4f4ccf3e
https://blog.csdn.net/qq_28448117/article/details/79199835
https://blog.csdn.net/weixin_39175124/article/details/79465558
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WqZjcboS-1587453051502)(attachment:image.png)]](https://img-blog.csdnimg.cn/20200421160505827.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0VsZW5zdG9uZQ==,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mMIrixGD-1587453051504)(attachment:image.png)]](https://img-blog.csdnimg.cn/20200421160724252.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0VsZW5zdG9uZQ==,size_16,color_FFFFFF,t_70)