KNN算法称为邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
假设给定一个训练数据:

在不同的类别上有近乎均等的样本数量,当对一个实际数据进行归类的时候,计算该数据与训练样本的距离(如下图):
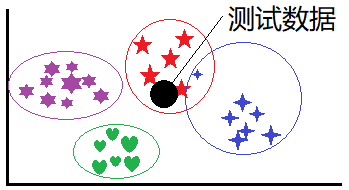
显然,这种方法对于训练数据的要求是在每个种类的样本数量基本相同,当每个种类的样本数量差别较大的时候会严重影响由于K值导致的错误:

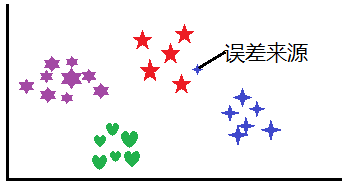
即便每个种类数据的样本数量相同,对数据进行归类的时候也有可能不准确(天然误差),这种误差是无法避免的:
下面简单介绍KNN算法的C语言实现(以手写数字识别为例)。
1.手写数字的标准图像是MNIST数据集,这里我对这个数据集进行了改动方便查看,一个手写数据的格式为:
/*一个手写数字的结构体*/
typedef struct
{
int pixel[1024];
int label;
}Digit;
/*一个手写数字的txt格式*/
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0 0 1 1 1 1 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 1 1 1 1 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 1 1 1 1 1 0 0 0 0 0 0 0
0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 1 1 1 1 0 0 0 0 0 0 0
0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0
0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0
0 0 0 0 0 0 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
9
2.txt手写数据的加载
int loadDigit(Digit *digit, FILE *fp, int *labels)
/*读取digit*/
{
int index=0;
for(index = 0; index<1024; index++)
{
if(!fscanf(fp, "%d", &(digit->pixel[index])) )
{
printf("FILE already read finish.\n");
return -1;
}
}
fscanf(fp, "%d", &(digit->label));
*labels = digit->label;
return 1;
}
int i;
FILE *fp;
/*读入训练数据*/
int trainLabels[ntrain];
int trainCount[10] = {0};
Digit *Dtrain = (Digit*)malloc(ntrain*sizeof(Digit));
fp = fopen(trainingFile,"r");
printf("..load training digits.\n");
for(i=0;i<ntrain;i++)
{
loadDigit(&Dtrain[i], fp, &trainLabels[i]);
trainCount[Dtrain[i].label] ++;
}
fclose(fp);
printf("..Done.\n");
同样,对于测试数据的加载方法相同。
3.距离的计算
/*一个有label的距离结构体*/
typedef struct
{
float distance;
int label;
}Distance;
float calDistance(Digit digit1, Digit digit2)
/*求距离*/
{
int i, squareSum=0.0;
for(i=0;i<1024;i++)
{
squareSum += pow(digit1.pixel[i]-digit2.pixel[i], 2.0);
}
return sqrtf(squareSum);
}
4.采用选择排序算法对距离进行从小到大排序
void exchange(Distance *in, int index1, int index2)
/*交换字符串两项*/
{
Distance tmp = (Distance)in[index1];
in[index1] = in[index2];
in[index2] = tmp;
}
void selectSort(Distance *in, int length)
/*选择排序*/
{
int i, j, min;
int N = length;
for(i=0;i<N-1;i++)
{
min = i;
for(j=i+1;j<N;j++)
{
if(in[j].distance<in[min].distance) min = j;
}
exchange(in,i,min);
}
}
5.数据的预测
在排序后的距离数组中选择前K个距离最近的预测值中最多的一个预测值,即为数据的预测值。
6.准确度测试
训练数据为943个手写数字,测试数据为196个手写数字,分别对这196个数据进行准确度测试,取K==1,得出的准确度为:
0: ( 19 / 20 ) = 95.00% 1: ( 20 / 20 ) = 100.00% 2: ( 25 / 25 ) = 100.00% 3: ( 17 / 18 ) = 94.44% 4: ( 21 / 25 ) = 84.00% 5: ( 16 / 16 ) = 100.00% 6: ( 16 / 16 ) = 100.00% 7: ( 19 / 19 ) = 100.00% 8: ( 15 / 17 ) = 88.24% 9: ( 20 / 20 ) = 100.00%
可以看出来,准确度不是十分高,但是也还说得过去吧。
然后给出几个未知的手写字符进行预测:

预测的结果(K==1)为:5-2-1-8-2-9-9-1-5。
可以看出预测的准确度还是可以的。
下面给出C语言源代码(代码和数据链接在文末):
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<math.h>
typedef const int cint;
typedef const char cchar;
/*一个手写数字的结构体*/
typedef struct
{
int pixel[1024];
int label;
}Digit;
/*一个有label的距离结构体*/
typedef struct
{
float distance;
int label;
}Distance;
/*文件路径+名称*/
cchar *trainingFile = "./mydatasets/my-digit-training.txt";
cchar *testingFile = "./mydatasets/my-digit-testing.txt";
cchar *predictFile = "./mydatasets/my-digit-predict.txt";
/*每个数据集的数字个数*/
cint ntrain = 943;
cint ntest = 196;
cint npredict = 9;
float calDistance(Digit digit1, Digit digit2)
/*求距离*/
{
int i, squareSum=0.0;
for(i=0;i<1024;i++)
{
squareSum += pow(digit1.pixel[i]-digit2.pixel[i], 2.0);
}
return sqrtf(squareSum);
}
int loadDigit(Digit *digit, FILE *fp, int *labels)
/*读取digit*/
{
int index=0;
for(index = 0; index<1024; index++)
{
if(!fscanf(fp, "%d", &(digit->pixel[index])) )
{
printf("FILE already read finish.\n");
return -1;
}
}
fscanf(fp, "%d", &(digit->label));
*labels = digit->label;
return 1;
}
void showDigit(Digit digit)
/*显示一个Digit 结构体*/
{
int i, j, id;
for(i=0;i<32;i++)
{
for(j=0;j<32;j++)
{
printf("%d", digit.pixel[i*32+j]);
}
printf("\n");
}
printf(" %d \n", digit.label);
}
void exchange(Distance *in, int index1, int index2)
/*交换字符串两项*/
{
Distance tmp = (Distance)in[index1];
in[index1] = in[index2];
in[index2] = tmp;
}
void selectSort(Distance *in, int length)
/*选择排序*/
{
int i, j, min;
int N = length;
for(i=0;i<N-1;i++)
{
min = i;
for(j=i+1;j<N;j++)
{
if(in[j].distance<in[min].distance) min = j;
}
exchange(in,i,min);
}
}
int prediction(int K, Digit in, Digit *train, int nt)
/*利用训练数据预测一个数据digit*/
{
int i, it;
Distance distance[nt];
/*求取输入digit与训练数据的距离*/
for(it=0; it<nt; it++)
{
distance[it].distance = calDistance(in, train[it]);
distance[it].label = train[it].label;
}
/*给计算的距离排序(选择排序)*/
int predict = 0;
selectSort(distance, nt);
for(i=0; i<K; i++)
{
predict += distance[i].label;
}
return (int)(predict/K);
}
void knn_classifiy(int K)
/*用测试数据集进行测试*/
{
printf(".knn_classifiy.\n");
int i;
FILE *fp;
/*读入训练数据*/
int trainLabels[ntrain];
int trainCount[10] = {0};
Digit *Dtrain = (Digit*)malloc(ntrain*sizeof(Digit));
fp = fopen(trainingFile,"r");
printf("..load training digits.\n");
for(i=0;i<ntrain;i++)
{
loadDigit(&Dtrain[i], fp, &trainLabels[i]);
trainCount[Dtrain[i].label] ++;
}
fclose(fp);
printf("..Done.\n");
/*读入测试数据*/
int testLabels[ntest];
int testCount[10] = {0};
Digit *Dtest = (Digit*)malloc(ntest*sizeof(Digit));
fp = fopen(testingFile,"r");
printf("..load testing digits.\n");
for(i=0;i<ntest;i++)
{
loadDigit(&Dtest[i], fp, &testLabels[i]);
testCount[Dtest[i].label] ++;
}
fclose(fp);
printf("..Done.\n");
/*求测试数据与训练数据之间的距离*/
printf("..Cal Distance begin.\n");
Distance Distance2Train[ntrain];
int CorrectCount[10] = {0};
int itrain, itest, predict;
for(itest=0; itest<ntest; itest++)
{
predict = prediction(K, Dtest[itest], Dtrain, ntrain);
//printf("%d-%d\n",predict, Dtest[itest].label);
/*给预测准确的进行计数*/
if(predict == Dtest[itest].label)
{
CorrectCount[predict] ++;
}
}
/*输出测试数据的准确率*/
printf(" Correct radio: \n\n");
for(i=0;i<10;i++)
{
printf("%d: ( %2d / %2d ) = %.2f%%\n",
i,
CorrectCount[i],
testCount[i],
(float)(CorrectCount[i]*1.0/testCount[i]*100));
}
}
void knn_predict(int K)
/*预测数据*/
{
int i;
FILE *fp;
/*读入训练数据*/
int trainLabels[ntrain];
int trainCount[10] = {0};
Digit *Dtrain = (Digit*)malloc(ntrain*sizeof(Digit));
fp = fopen(trainingFile,"r");
printf("..load training digits.\n");
for(i=0;i<ntrain;i++)
{
loadDigit(&Dtrain[i], fp, &trainLabels[i]);
trainCount[Dtrain[i].label] ++;
}
fclose(fp);
printf("..Done.\n");
/*读入需要预测的数据*/
int predictLabels[npredict];
int predictCount[10] = {0};
Digit *Dpredict = (Digit*)malloc(npredict*sizeof(Digit));
fp = fopen(predictFile,"r");
printf("..load predict digits.\n");
for(i=0;i<npredict;i++)
{
loadDigit(&Dpredict[i], fp, &predictLabels[i]);
predictCount[Dpredict[i].label] ++;
}
fclose(fp);
printf("..Done.\n");
/*求输入数据与训练数据之间的距离*/
printf("..Cal Distance begin.\n");
Distance Distance2Train[ntrain];
int itrain, ipredict, predict;
for(ipredict=0; ipredict<npredict; ipredict++)
{
predict = prediction(K, Dpredict[ipredict], Dtrain, ntrain);
printf("%d\n",predict);
}
}
int main(int argc, char** argv)
{
int K = 1;
/*对已知数据进行测试,统计预测的正确率*/
knn_classifiy(K);
/*对位置数据进行预测*/
knn_predict(K);
return 1;
}
编译与运行:
D:\>gcc main.c
D:\>a.exe
.knn_classifiy.
..load training digits.
..Done.
..load testing digits.
..Done.
..Cal Distance begin.
Correct radio:
0: ( 19 / 20 ) = 95.00%
1: ( 20 / 20 ) = 100.00%
2: ( 25 / 25 ) = 100.00%
3: ( 17 / 18 ) = 94.44%
4: ( 21 / 25 ) = 84.00%
5: ( 16 / 16 ) = 100.00%
6: ( 16 / 16 ) = 100.00%
7: ( 19 / 19 ) = 100.00%
8: ( 15 / 17 ) = 88.24%
9: ( 20 / 20 ) = 100.00%
..load training digits.
..Done.
..load predict digits.
..Done.
..Cal Distance begin.
5
2
1
8
2
9
9
1
5
可以说这个准确度还是可以的。
下面的链接还给出了一个GitHub上另一位作者的项目,使用python写的,python代码一共290行,并且用了很多API接口,我写的这个用的纯C语言,没用任何的接口,一共237行。我啥也不说。
友情链接:
手写数字txt文件地址:https://download.csdn.net/download/rong_toa/10413191
或者直接GitHub地址:https://github.com/RongToa/kNN
微信文章链接:https://mp.weixin.qq.com/s/yBPqSwpSOE4SGVifCDuoSg
Python代码地址:https://github.com/Alvin2580du/KNN_mnist