numpy常用函数
%matplotlib notebook
import matplotlib.pyplot as plt
import numpy as np
x1=np.arange(100)#返回0-99的一组等差数列
x2=np.linspace(0,100,100)#从(0,100)均匀取100个点
data=[6,7.5,8,0,1]
x3=np.array(data)#将输入数据转换为数组
x4=np.random.randn(100)#随机生成一个1行的数组
x5=np.random.randn(2,3)#随机生成一个2行3列的数组
data1=[[1,2,3,4],[5,6,7,8]]
x6=np.array(data1)#将输入数据转换为数组
x4
一、导入外部数据
import pandas as pd
import numpy as np
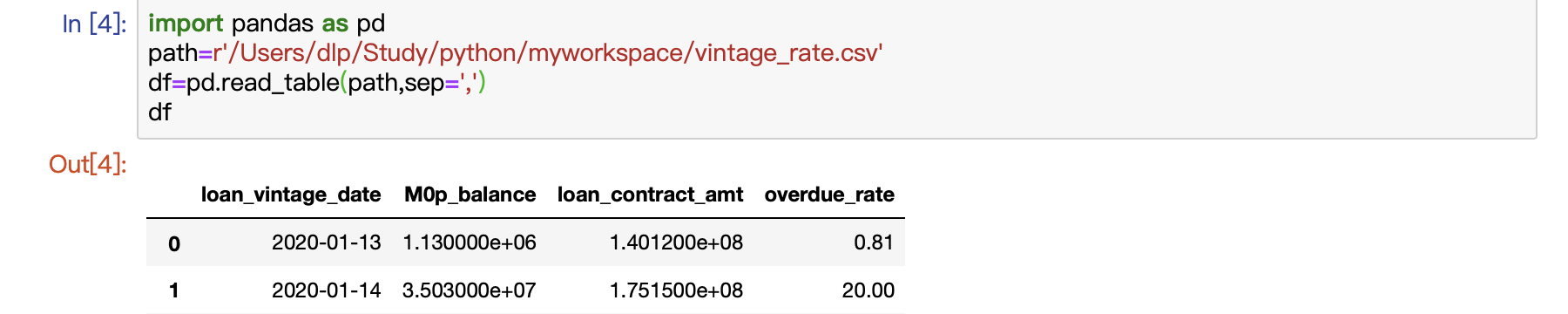
path=r'...\*.csv'
df=read_table(path,sep=',',header=None)
或df=pd.Dataframe(pd.read_csv(path,header=None))
二、数据表检查
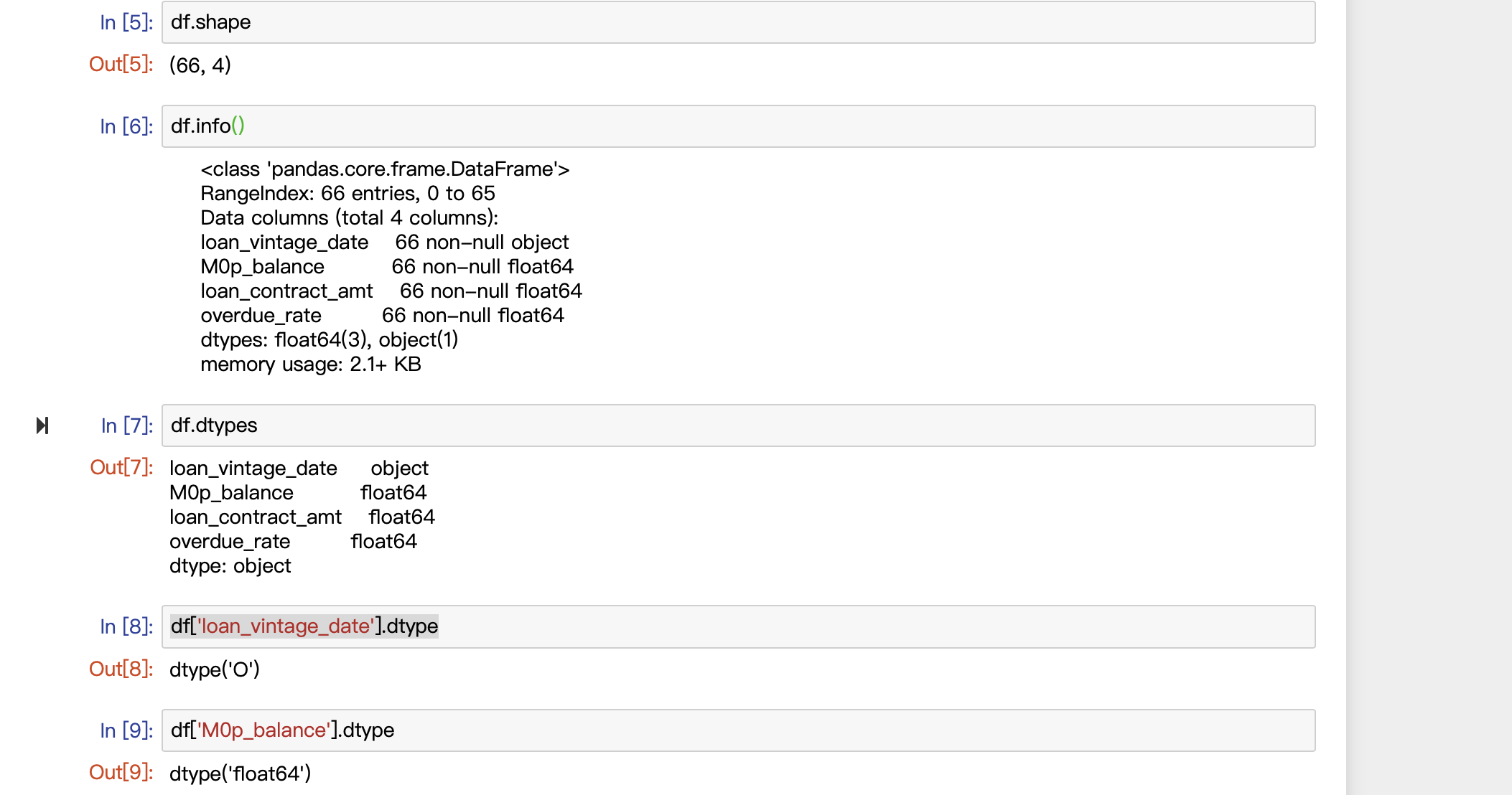
(1)数据维度:df.shape #使用shape函数来查看数据表的维度,也就是行数和列数。
(2)数据表信息:df.info() #使用info函数查看数据表的整体信息,包括数据维度、列名称、数据格式和所占空间等信息。
(3)数据格式:df.dtypes #查看数据表各列格式
df['某列'].dtype #查看单列的格式
(4)检查空值:df.isnull() #检查表中数据是否为空值
df['某列'].isnull #检查某列数据是否为空值
(5)查看唯一值:df['某列'].unique() #查看某列的唯一值,需要先选中列
(6)查看数据表的值:df.values
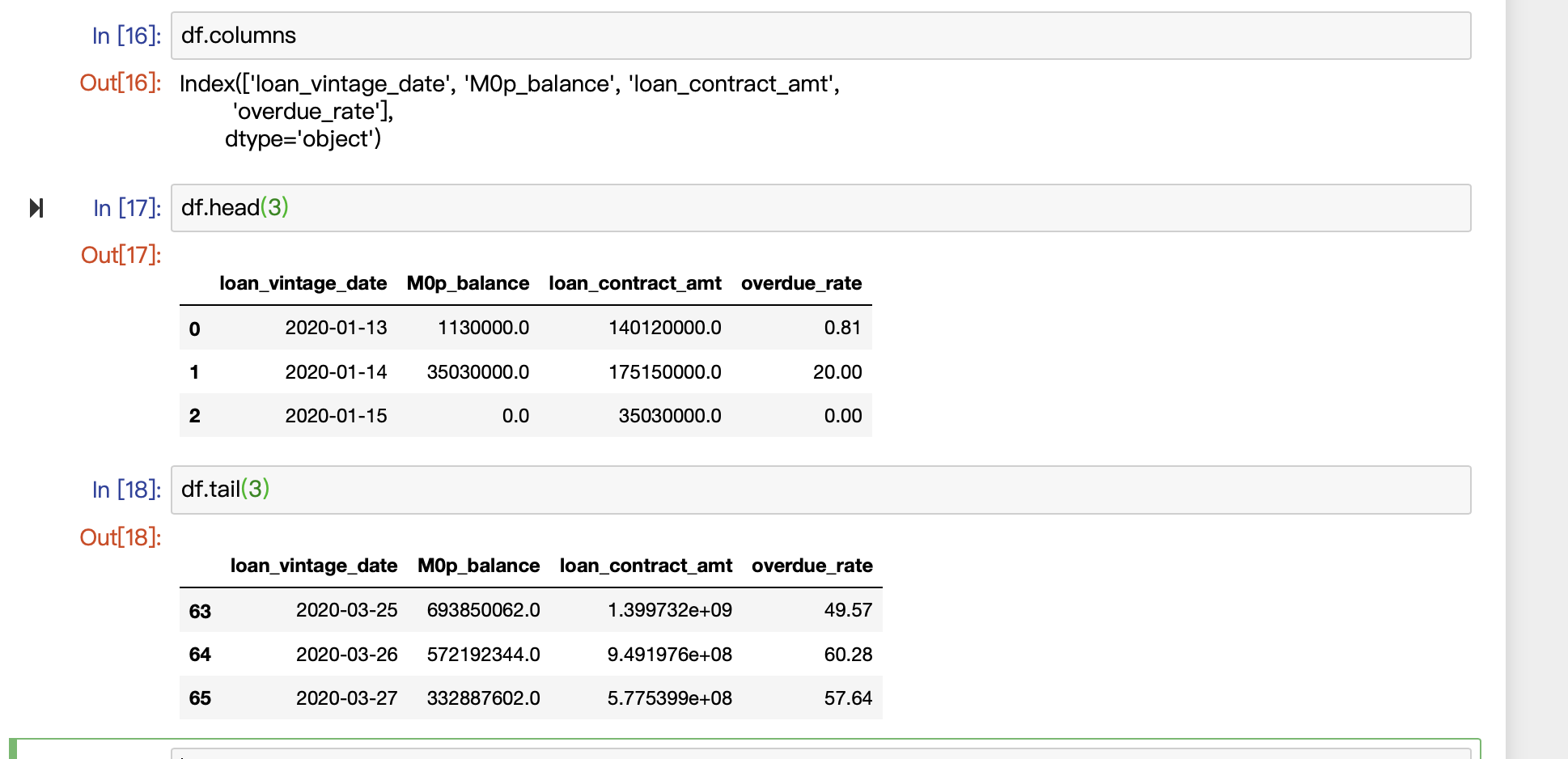
(7)查看列名称:df.columns
(8)查看前3行:df.head(3)
(9)查看后3行:df.tail(3)




三、数据清洗
1、处理空值
df.dropna(how='any') #删除数据表中含有空值的行
df.fillna(value=0) #使用数字0填充数据表中的空值
df['price'].fillna(df['price'].mean()) #使用price列的均值填充price列的空值