1:Flink重新编译
由于实际生产环境当中,我们一般都是使用基于CDH的大数据软件组件,因此我们Flink也会选择基于CDH的软件组件,但是由于CDH版本的软件并没有对应的Flink这个软件安装包,所以我们可以对开源的Flink进行重新编译,然后用于适配我们对应的CDH版本的hadoop
1.1: 准备工作
- 安装maven3版本及以上:省略
- 安装jdk1.8:省略
1.2:下载flink源码包
cd /opt
wget http://archive.apache.org/dist/flink/flink-1.8.1/flink-1.8.1-src.tgz
tar -zxf flink-1.8.1-src.tgz -C /opt/install/
cd /opt/install/flink-1.8.1/
mvn -T2C clean install -DskipTests -Dfast -Pinclude-hadoop -Pvendor-repos -Dhadoop.version=2.6.0-cdh5.14.2
# 编译成功之后的文件夹目录位于
/opt/install/flink-1.8.1/flink-dist/target
2:flink架构模型
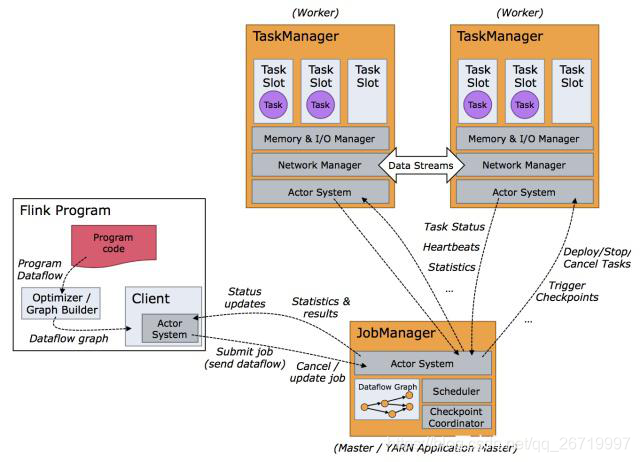
-
Client:Flink 作业在哪台机器上面提交,那么当前机器称之为Client。用户开发的Program 代码,它会构建出DataFlow graph,然后通过Client提交给JobManager。
-
JobManager:是主(master)节点,相当于YARN里面的ResourceManager,生成环境中一般可以做HA 高可用。JobManager会将任务进行拆分,调度到TaskManager上面执行。
-
TaskManager:是从节点(slave),TaskManager才是真正实现task的部分。
- Client提交作业到JobManager,就需要跟JobManager进行通信,它使用Akka框架或者库进行通信,另外Client与JobManager进行数据交互,使用的是Netty框架。Akka通信基于Actor System,Client可以向JobManager发送指令,比如Submit job或者Cancel /update job。JobManager也可以反馈信息给Client,比如status updates,Statistics和results。
- Client提交给JobManager的是一个Job,然后JobManager将Job拆分成task,提交给TaskManager(worker)。JobManager与TaskManager也是基于Akka进行通信,JobManager发送指令,比如Deploy/Stop/Cancel Tasks或者触发Checkpoint,反过来TaskManager也会跟JobManager通信返回Task Status,Heartbeat(心跳),Statistics等。另外TaskManager之间的数据通过网络进行传输,比如Data Stream做一些算子的操作,数据往往需要在TaskManager之间做数据传输。
- 当Flink系统启动时,首先启动JobManager和一至多个TaskManager。JobManager负责协调Flink系统,TaskManager则是执行并行程序的worker。当系统以本地形式启动时,一个JobManager和一个TaskManager会启动在同一个JVM中。当一个程序被提交后,系统会创建一个Client来进行预处理,将程序转变成一个并行数据流的形式,交给JobManager和TaskManager执行。
3:部署运行模式
类似于spark一样,flink也有各种运行模式,其中flink主要支持三大运行模式
- 第一种运行模式:local模式,适用于测试调试
- Flink 可以运行在 Linux、Mac OS X 和 Windows 上。本地模式的安装唯一需要的只是Java 1.7.x或更高版本,本地运行会启动Single JVM,主要用于测试调试代码。一台服务器即可运行
- 第二种运行模式:standAlone模式,适用于flink自主管理资源
- Flink自带了集群模式Standalone,主要是将资源调度管理交给flink集群自己来处理,standAlone是一种集群模式,可以有一个或者多个主节点JobManager(HA模式),用于资源管理调度,任务管理,任务划分等工作,多个从节点taskManager,主要用于执行JobManager分解出来的任务
- 第三种模式:flink on yarn模式,适用于使用yarn来统一调度管理资源
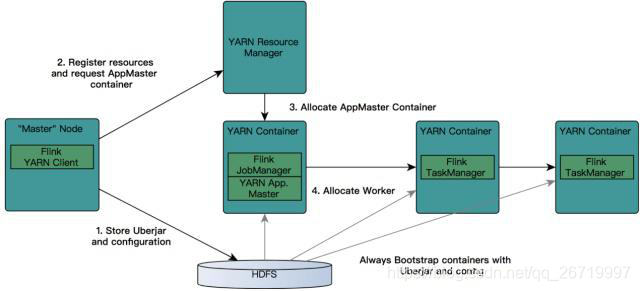
- Flink ON YARN工作流程如下所示:
- 首先提交job给YARN,就需要有一个Flink YARN Client。
- 第一步:Client将Flink 应用jar包和配置文件上传到HDFS。
- 第二步:Client向ResourceManager注册resources和请求APPMaster Container。
- 第三步:REsourceManager就会给某一个Worker节点分配一个Container来启动APPMaster,JobManager会在APPMaster中启动。
- 第四步:APPMaster为Flink的TaskManagers分配容器并启动TaskManager,TaskManager内部会划分很多个Slot,它会自动从HDFS下载jar文件和修改后的配置,然后运行相应的task。TaskManager也会与APPMaster中的JobManager进行交互,维持心跳等
- Flink ON YARN工作流程如下所示:
Flink的支持以上这三种部署模式,一般在学习研究环节,资源不充足的情况下,采用Local模式就行,生产环境中Flink ON YARN比较常见
