flink学习笔记-flink on yarn的两种模式都学会了吗?
其他
2020-04-07 11:31:32
阅读次数: 0
flink的任务也可以运行在yarn上面,将flnk的任务提交到yarn平台,通过yarn平台来实现我们的任务统一的资源调度管理,方便我们管理集群当中的CPU和内存等资源
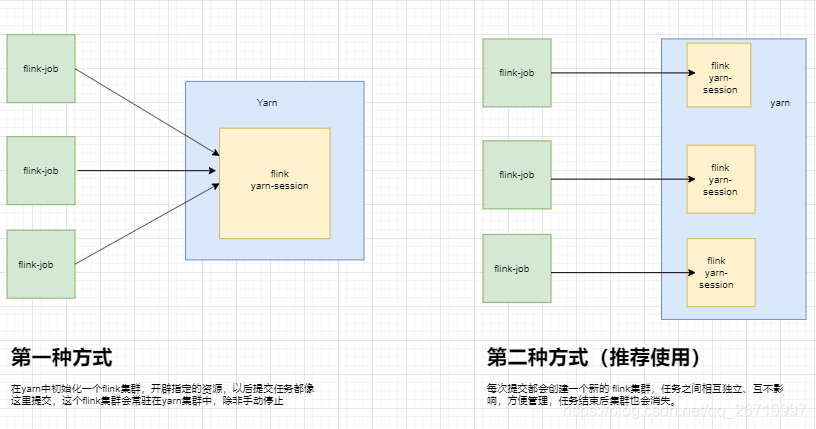
flink on yarn又分为两种模式
这种方式需要先启动集群,然后在提交作业,接着会向yarn申请一块资源空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,那下一个作业才会正常提交,实际工作当中一般不会使用这种模式cd / opt/ install/ hadoop- 2. 6. 0- cdh5. 14. 2/ etc/ hadoop
vim yarn- site. xml
<property>
<name>yarn. resourcemanager. am. max- attempts</ name>
<value>4</ value>
<description>
The maximum number of application master execution attempts.
</ description>
</ property>
scp yarn- site. xml node02:$PWD
scp yarn- site. xml node03:$PWD
cd / opt/ install/ flink- 1. 8. 1/ conf
vim flink- conf. yaml
high- availability: zookeeper
high- availability. storageDir: hdfs:/ / node01:8020/ flink_yarn_ha
high- availability. zookeeper. path. root: / flink- yarn
high- availability. zookeeper. quorum: node01:2181, node02:2181, node03:2181
yarn. application- attempts: 10
hdfs dfs - mkdir - p / flink_yarn
cd / opt/ install/ flink- 1. 8. 1/
bin/ yarn- session. sh - n 2 - jm 1024 - tm 1024 [ - d]
Diagnostics: Container [ ] is running beyond virtual memory limits. Current usage: 250. 5 MB of 1 GB physical memory used; 2. 2 GB of 2. 1 GB virtual memory used. Killing containerpid=6386, containerID=container_1521277661809_0006_01_000001
<property>
<name>yarn. nodemanager. vmem- check- enabled</ name>
<value>false</ value>
</ property>
第四步:查看yarn管理界面
问yarn的8088管理界面,发现yarn当中有一个应用:http://node01:8088/cluster。yarn当中会存在一个常驻的application,就是为我们flink单独启动的一个session
第五步:提交任务
vim wordcount. txt
hello world
flink hadoop
hdfs dfs - mkdir - p / flink_input
hdfs dfs - put wordcount. txt / flink_input
cd / kkb/ install/ flink- 1. 8. 1
bin/ flink run . / examples/ batch/ WordCount. jar
- input hdfs:/ / node01:8020/ flink_input
- output hdfs:/ / node01:8020/ flink_output/ wordcount- result. txt
这种方式的好处是一个任务会对应一个job,即每提交一个作业会根据自身的情况,向yarn申请资源,直到作业执行完成,并不会影响下一个作业的正常运行,除非是yarn上面没有任何资源的情况下。注意:client端必须要设置YARN_CONF_DIR或者HADOOP_CONF_DIR或者HADOOP_HOME环境变量,通过这个环境变量来读取YARN和HDFS的配置信息,否则启动会失败
cd / opt/ install/ flink- 1. 8. 1/
bin/ flink run - m yarn- cluster - yn 2 - yjm 1024 - ytm 1024 . / examples/ batch/ WordCount. jar - input hdfs:/ / node01:8020/ flink_input - output hdfs:/ / node01:8020/ out_result/ out_count. txt
hdfs dfs - text hdfs:/ / node01:8020/ out_result/ out_count. txt
发布了40 篇原创文章 ·
获赞 59 ·
访问量 1405
转载自 blog.csdn.net/qq_26719997/article/details/105010104